 .
.
Iceberg Summit 2024 のセッション「eBay's Voyage with Apache Iceberg」を日本語でまとめます。
可能な限り正確に内容を拾えるようにリスニングに努めたつもりですが、もし誤りがあればご指摘ください。
Iceberg Summit とは?
公式ページより翻訳
本イベントでは、Apache Icebergを実務で活用していたり、Icebergの開発に携わる技術者による数十の技術的なセッションが開催されます。計算エンジンの統合、Icebergのデータパイプライン、PyIcebergの利用、データモデリング、データガバナンス、テーブルの最適化とメンテナンス、セキュリティとガバナンスなどのトピックを扱います
Iceberg Summitは、データエンジニア、開発者、アーキテクト間でのApache Icebergの教育と知識共有を促進するために、Apache Software Foundationが承認したイベントです。
各セッションはYoutubeで視聴できます.
eBay's Voyage with Apache Iceberg
日本語に訳すと「eBayでのApache Iceberg導入の旅」という感じでしょうか。
スピーカー
 .
.
- Manu Zhang
eBayについて ja.wikipedia.org.
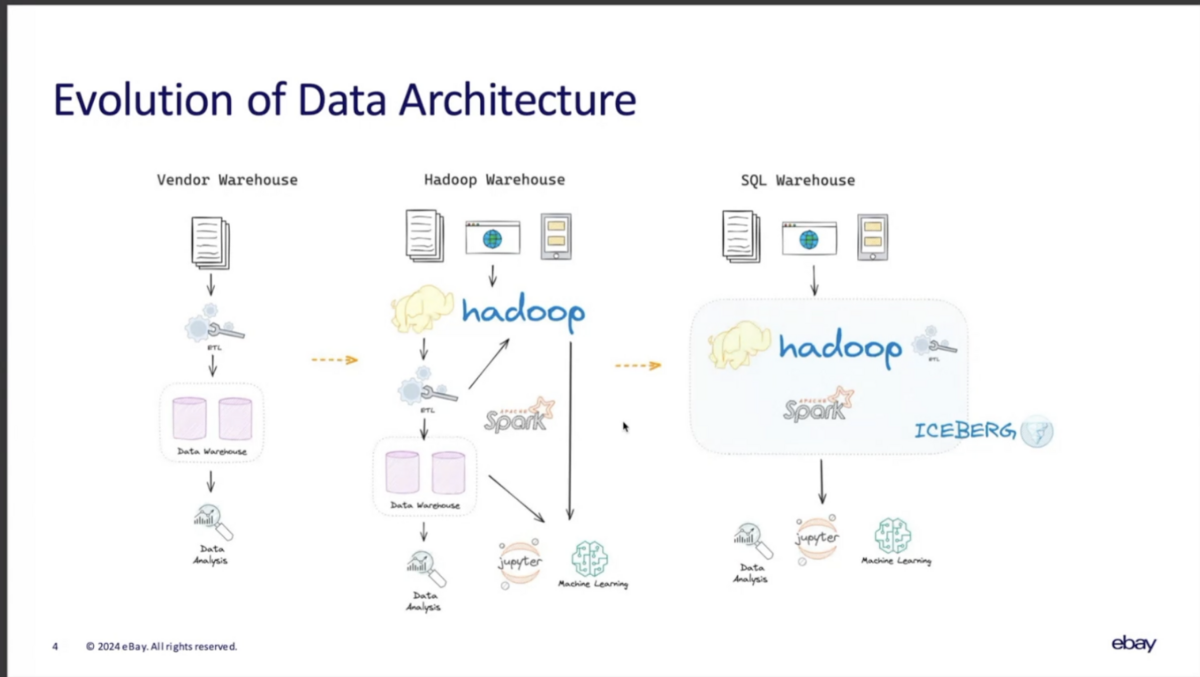
eBayのデータアーキテクチャの歴史
 .
.
初期
20年前、eBayのデータ基盤はDWHを中心とする構成から始まった。当時は構造化データをETLを経てDWHにロードして分析していた。
ビッグデータ時代の到来
データの量、速度、多様性が爆発的に増加するにつれ、DWH以外の様々な仕組みが必要とされるようになった。
従来のデータ分析アプリケーションに加えて、リアルタイムモニタリング、データサイエンス、機械学習など、より幅広いアプリケーションが登場した。
結果として、HDFS、Hive、Sparkなどのオープンソースプロジェクトで構築されたデータレイクアーキテクチャへの移行が進んだ。
これらの仕組みは十分に役に立ってきたが、トランザクションサポート、高速な更新、データ品質の管理、データガバナンスなどの機能が十分ではなかった。
また、パイプラインの複雑性の解決や、ユーザビリティの向上が課題になってきた。
Icebergの導入
従来のデータ基盤の課題を解決するため、Icebergによって様々なユーザ体験を統合した。そのため、Manuさんはこれを"シングルウェアハウス"と呼ぶのを好んでいる。
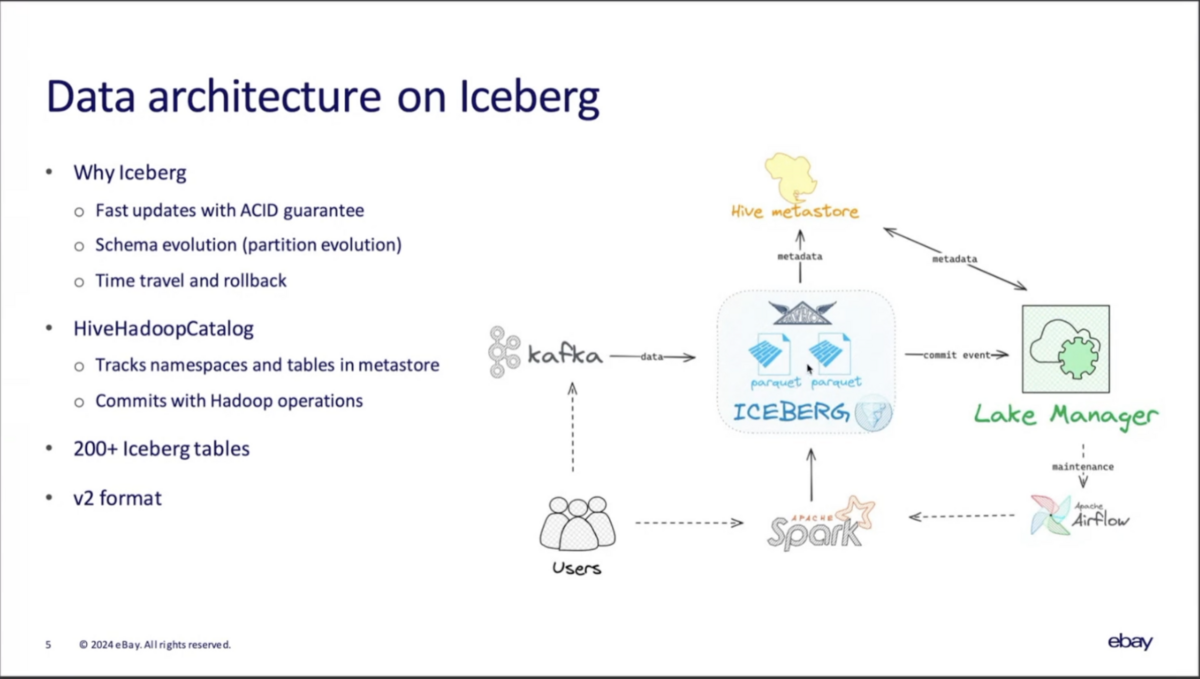
Icebergを導入したデータ基盤の全体像
 .
.
Kafkaからデータを取り込み、SparkやFlinkで変換し、Icebergのテーブルに書き込む。
Commit Eventは後述するLake Managerへ送られ、Catalogへ送信されると同時に、必要に応じてテーブルメンテナンスジョブがAirflowにスケジュールされる。
Catalogに関してはHive Metastoreと統合した独自のカスタムCatalogを開発し、従来のHiveテーブルとの相互運用性を確保した。加えて、Metastoreの性能をスケールさせるためメタデータをキャッシュしている。
これはHive CatalogとHadoop Catalogの良いところを組み合わせたような仕組みなので、「Hive-Hadoop Catalog」と呼んでいる。
200以上のIceberg Tableがあり、Table Spec v2を使用している。Merge on Readも有効化している。
ユーザのほとんどはSparkでアプリケーションを書いている。
Icebergを導入して特に嬉しかったこと
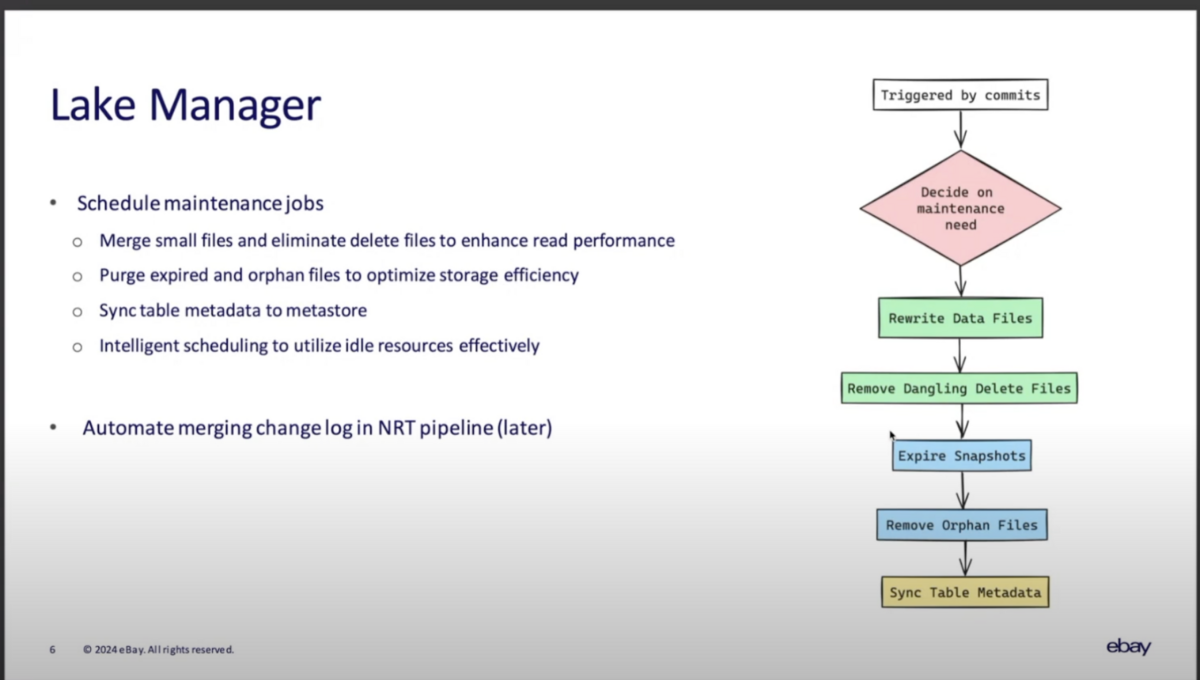
Lake Manager
 .
.
Icebergの運用上のポイントとして、small fileのコンパクションによる性能の最適化や、expired / orphan file(不要なデータ)をPurge(削除)してストレージ効率の最適化などのテーブルメンテナンスの実施戦略が重要になる。
eBayが独自に開発したLake Managerは、Icebergテーブルへのコミットをトリガーにテーブルメンテナンス要否を判定し、必要に応じてバックグラウンドジョブをスケジュールする。そのタイミングは、テーブルのアクティビティや、クラスタ上の有休リソースの状況を鑑みてベストなタイミングを選ぶようになっている。
同時にHive Metastoreへのメタデータの同期も実施しており、最終コミット時間、最終圧縮時間、データファイルの総数、スナップショットの数などが保存され、運用を最適化するための分析に使用されている。
また、Lake Managerはchange logのニアリアルタイムなマージをする役割も担っている。(後述).
eBayにおけるIcebergの代表的なユースケース
データコンプライアンス要件への対応
 .
.
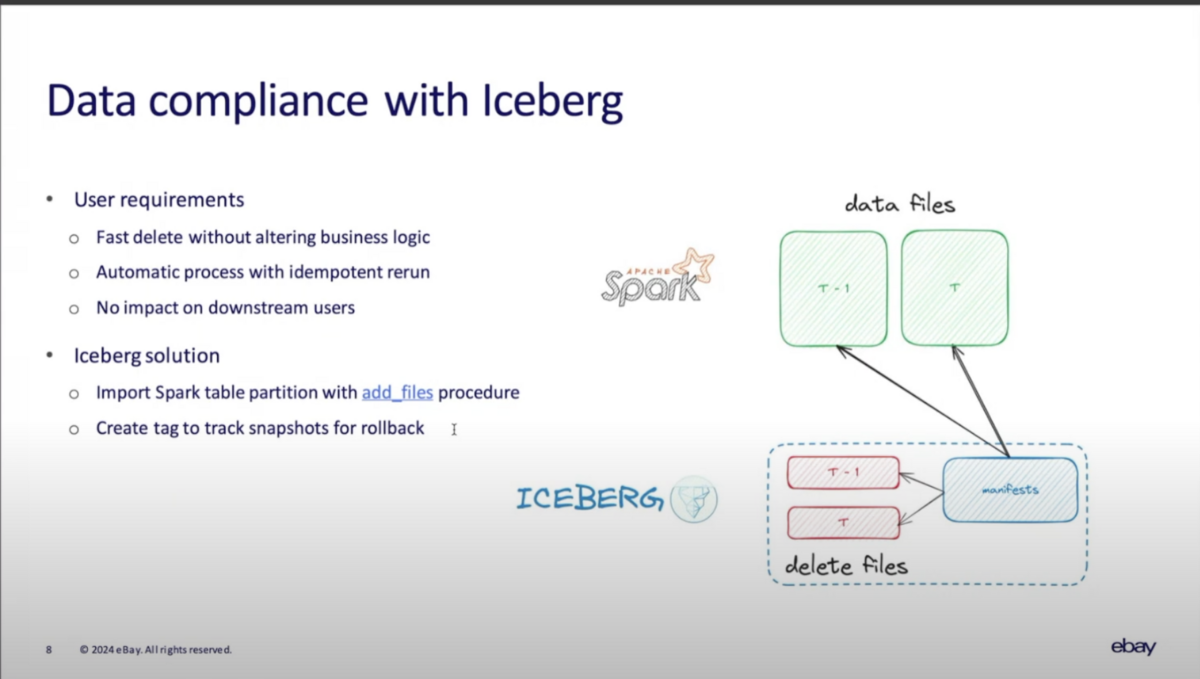
GDPRなどのデータコンプライアンス要件に応えるため、データ基盤として、以下の要件に応える必要があった。
- タイトなタイムラインの中で、ビジネスロジックを変更せずに高速な削除を実現
- データ削除が途中で失敗した場合でも再実行時の冪等性を確保
- 一連の削除処理の中でユーザ影響を発生させない
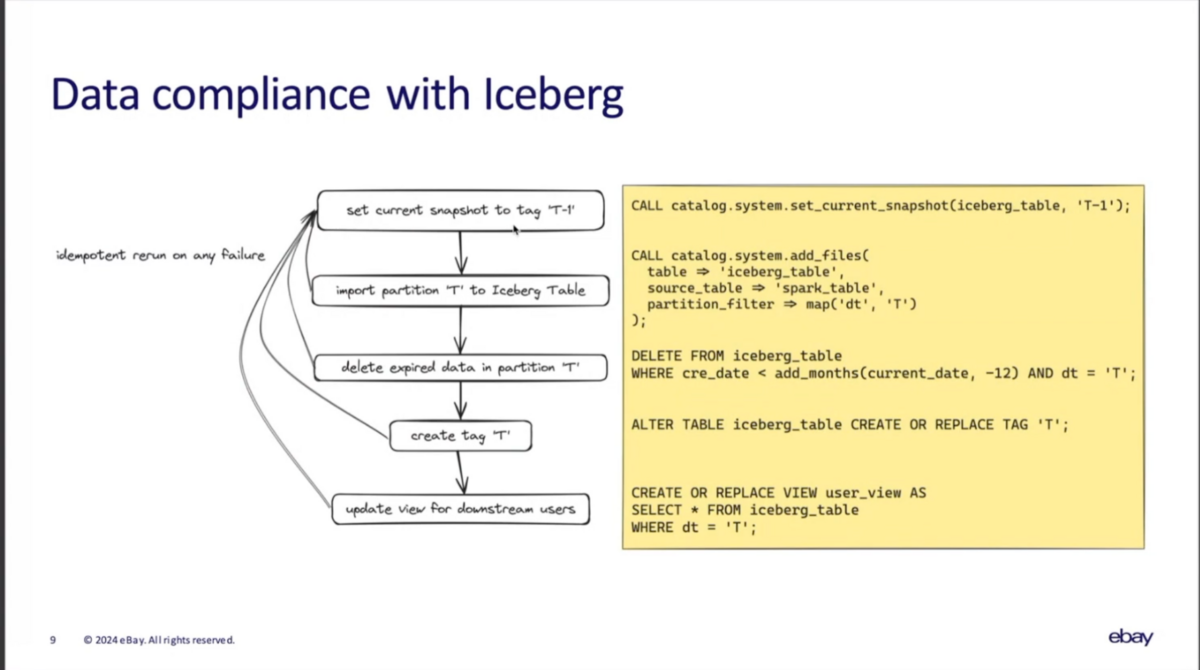
これらの要求に応えるため、Sparkのadd_filesプロシージャを活用している。
- まず、 T-1のスナップショットに'T-1'タグを設定
- 次に、add_filesプロシージャでソースとなるSpark Tableから当日のパーティションTをメタデータに追加
- Tの中で、削除要件の対象データを削除(Icebergによる論理削除)
- 現在のスナップショットに'T'タグを設定
- ユーザ向けのビューを更新
(この部分、丹念に聞いたものの今ひとつadd_filesを使う理由や、タグ運用の効果、前提としているソーステーブルのパーティション、テーブル構造の想定が理解できていない。元ネタの非Icebergなテーブルが存在していて、それを削除したい要件ということ...? また、データ削除の要件の前提によって、あるべき削除方法も変わる気がする... わかる方いたらご連絡ください&解説してください。。。。)
 .
.
これらの仕組みはユーザ目線では便利だが、課題もある
- add_filesはシリアルにパーティションを操作するため、対象のパーティションが大量に存在する場合に性能上の課題があった
- これについては、manuさん自身がIcebergにコントリビュートして直している
- Spark Tableとの間のストレージの重複
- タグを考慮したしスナップショット運用
- add_filesでINT96のtimestampを操作に失敗する場合がある
ニアリアルタイムパイプライン
 .
.
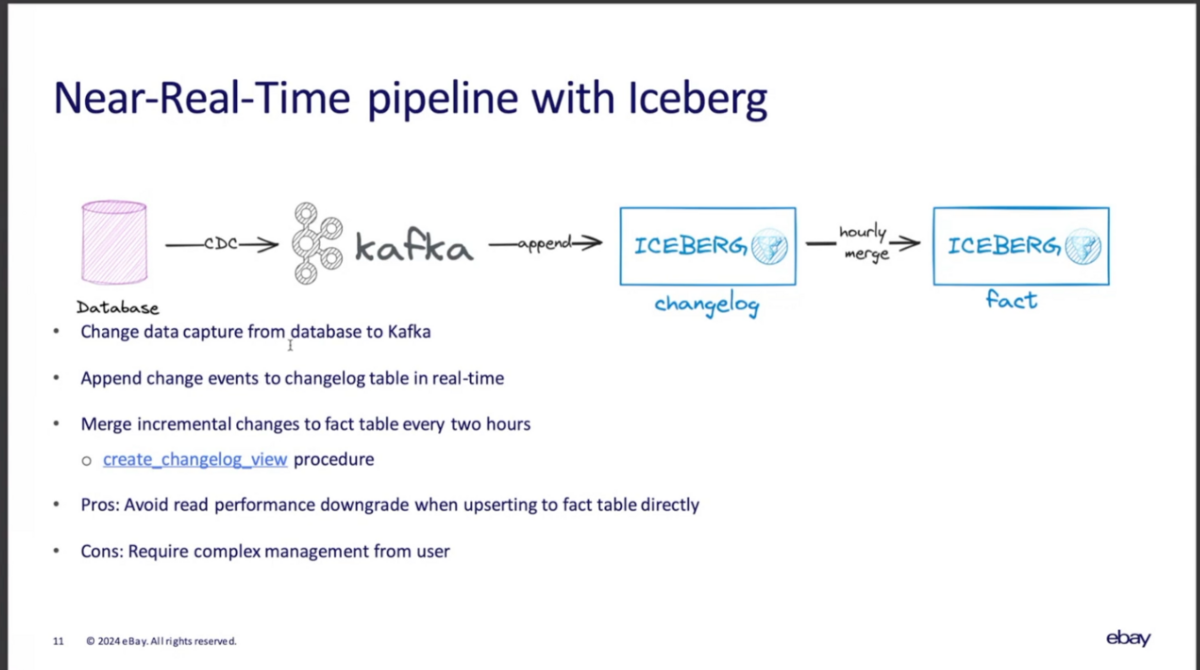
ニアリアルタイムパイプラインは2つのテーブルで構成されるのが特徴。まず、Kafkaから連携されるchange logをIcebergのchangelogテーブルに書き込む。その上で、2時間ごとにcreate_changelog_viewプロシージャでfactテーブルを更新する。
create_changelog_viewについてはこちらで解説しました bering.hatenadiary.com
ここでは、factテーブルを直接更新しないことで、読み込み性能の劣化を回避している。ただし、パイプラインが複雑になる課題がある。
 .
.
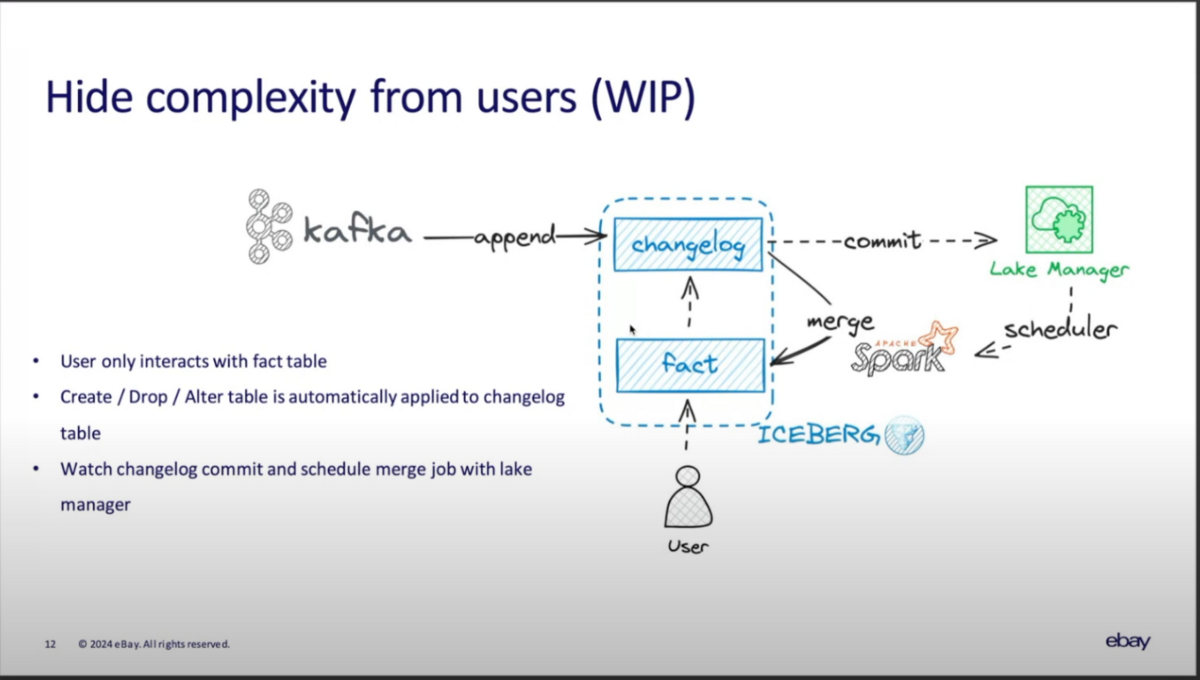
そこで、ユーザから複雑性を隠し、単一のfactテーブルに集中できるようにするための新しい仕組みの構築に取り組んでいる。
新しいプロセスでは、ユーザがfactテーブルを作成した際に、Lake Managerが自動的にchangelogテーブルとCDCの設定を作成する。
そして、ユーザがfactテーブルにデータをロードすると、実際には最初にchangelogテーブルに追加され、以降はLake Managerが増分変更をマージするSparkジョブをスケジュールする。
factテーブルにスキーマの変更が適用された場合はバックグラウンドでchangelogテーブルにも適用するほか、ユーザは設定を操作することでレイテンシを調整できる。
今後の展望
Apache Icebergを使ったeBayの旅は、多くのエキサイティングな可能性を秘めて、実際にはまだ始まったばかり。
例えば...
- ディザスタリカバリのための差分コピー
- プライマリ、セカンダリインデックスによる性能向上
- z-orderの活用
- データ圧縮戦略の改善
- Apache Rangerと統合したデータセキュリティの強化
- Rest Catalogの導入
QA
Q1: Hive-Hadoopカタログは、あなたが実装したカスタムカタログですか、それともIcebergが提供しているものですか?
A1: オリジナルなもの。Spark Catalogとよく似たもので、Spark テーブルやHiveテーブルと一緒にIcebergテーブルを読み取ることができる
Q2: ファイルの削除はどのように行いますか? 孤立ファイルを削除するのですか、それともマニフェストとデータファイルを実際に書き換えるのですか?
A2: データファイルを書き込むときは、新しいデータファイルを生成し、さらに期限切れのファイルと孤立したファイルを削除する別の手順を実行します。
Q3: equality deleteと、positional deleteのどちらを使用していますか?
A3: SparkのMerge intoではpositional delete、FlinkのUpsertではequality deleteを使用しています
Q4: IngestionでIcebergのチェリーピックは使っていますか?
A4: まだ試していません.
(オーガナイザのJBも正直わからないと言っていた).
Q5: Kafkaから連携される更新イベントを直接反映しないのはなぜ?
A5: small fileが大量に溜まり、メンテナンスジョブが追いつかなる結果、読み取りパフォーマンスの低下が問題になるためです
Q5: テーブルサイズと、日次の流入データ量はどれぐらいですか?
A5: テーブルはTBオーダーで、GBオーダーの変更が日々発生します.
Q6: ユーザはLake Managerをパイプラインのオーケストレーションに使うのですか?
A6: いいえ。ユーザは各自でETLパイプラインを作成します。Lake Managerは実際にはバックグラウンドでジョブをスケジュールするために動作しており、常にユーザーからは見えません.
Q7: Lake Managerのテーブルメンテナンスジョブと通常のジョブが競合することはない?
A7: はい、時々競合して失敗することがあります。しかし、途中からでも再試行できるようになっています。圧縮ジョブは自動で再試行されます.
Q8: メンテナンスジョブの再試行ではエクスポテンシャルバックオフを使っていますか?
A8: はい、Icebergはエクスポテンシャルバックオフをサポートしていますし、Airflowなどのレイヤでも多段的に再試行が行われます