2024/6/4追記:勉強会(OTFSG #2)で以下の記事の内容を整理+情報を追加した発表をしました。以下がその時のスライドになりますので、併せてご参照ください
この記事は Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2023 の2日目の記事です。
Apache Icebergにおいて、Catalogはその根幹を担うコンポーネントだ。Icebergのreader,writerはCatalogによってテーブルを発見し、整合性を維持しながらテーブルを操作できる。一方でCatalogを構成する選択肢は多様で、要件に応じて選ぶ必要がある。そこで本記事では、Iceberg Catalogの主な選択肢と特徴をまとめる。
そもそもIcebergってなに?という方は以下の関連記事もご参照下さい。
- Apache Iceberg とは何か
- データレイクの新しいカタチ:Open Table Formatの紹介
- 【翻訳】Bilibiliは如何にしてApache IcebergでData Lakehouseを構築したか?
Iceberg Catalogの要件
Iceberg Catalogの主な仕事は以下である。
- テーブルの作成、ドロップなどのテーブル操作を管理する(Catalog interface参照)
- テーブルの作成、ドロップなどのテーブル操作を永続化する
- 各テーブルについて、現在の最新断面のメタデータが格納されているmetadata fileのロケーションをポイントし、必要に応じて(アトミックに)更新する
特に3点目について、Icebergテーブルは階層化されたメタデータファイルを辿って実データにアクセスする仕組みである。そこでは階層の「入り口」となるメタデータファイルを示す役割が必要になる。それがIceberg Catalogというわけだ。
また、Icebergでは楽観的同時実行制御でトランザクションを実現するため、テーブルが操作される度に辿るべき最新のメタデータが更新される。(下図のs0,s1,s2)そこで、Icebergは現時点での最新のメタデータを示す役割を担う。
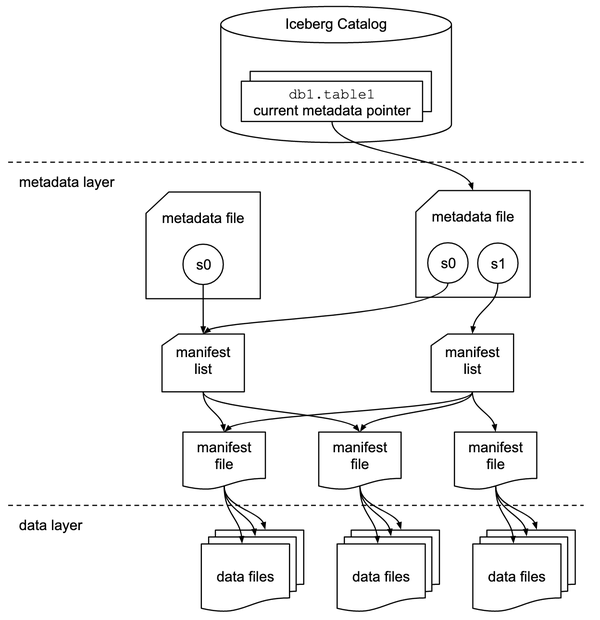
複数のreader,writerがデータの整合性を保ちながらテーブルを操作するには、Catalogからメタデータへのポインタがアトミックに更新できる必要がある。これは「必須」の要件ではなく、整合性を担保しない実装の選択肢もあるが、技術選定する際に必ず頭に入れておくべきポイントだ。
なお、Iceberg Catalogの仕事の一部は、Catalogの構成方法によって部分的にエンジン、ツール(にパッケージされるorg.apache.iceberg.hadoop.HadoopCatalogなどのライブラリ)が担う場合と、外部のサービス(REST Catalogなど)が担う場合がある。
Catalogの選択肢
前提として、CatalogはIcebergベースのデータレイクの根幹を担うコンポーネントなので、どれを選ぶ場合でも要件に応じて然るべきデータの耐久性やサービスの可用性を確保可能な設計にする必要がある。加えて、Catalogを選ぶ際には、使う予定の各エンジン/ツール(Spark, Trinoなど)がその方式をサポートしているかを考慮しなければならない。従って、Catalogの都合だけでなくクライアントも含めた総合的なアーキテクチャの中で選定しなければならない。
以上を踏まえてIceberg Catalogを構成する上での選択肢の概要を示す。
Hadoop Catalog
概要
専用のプロセスを必要としない、最も簡単なCatalogである。その仕組みは、任意のメタデータディレクトリ内のタイムスタンプに基づいて、最も最近書き込まれたタイムスタンプのファイルをメタデータとしてポイントするだけものだ。従って「Hadoop」という名前ではあるが、実はHadoopと無関係に使える。使い方は以下のようになる。
import org.apache.hadoop.conf.Configuration; import org.apache.iceberg.hadoop.HadoopCatalog; Configuration conf = new Configuration(); String warehousePath = "hdfs://host:8020/warehouse_path"; HadoopCatalog catalog = new HadoopCatalog(conf, warehousePath);
メタデータディレクトリ(warehousePath)の場所は適当なファイルシステムや、S3やGCSなどのオブジェクトストレージなど、幅広い選択肢がある。ただし、ストレージによってはファイル/オブジェクトのアトミックな変更をサポートしていない場合がある。つまり、データの整合性を担保できない可能性がある。また、S3などのオブジェクトストレージの場合、テーブル数、テーブルを構成するファイル数が多い場合はパフォーマンスに問題が出る可能性があるほか、APIレート制限も考慮する必要がある。
使い所
- Icebergの検証を目的に簡易な環境を構築したい場合
Hadoop Catalogはシンプルである一方でスケーラビリティや運用性を鑑みると欠点が多く、本番向けには他の選択肢を検討したほうが良いだろう。
参考
以降で紹介する選択肢は全てメタデータロケーションのアトミックな更新をサポートしている。
Hive Catalog(Hive Metastore Catalog)
概要
Hive Metastoreのテーブルエントリのlocationプロパティにメタデータファイルのパスをポイントする方式。
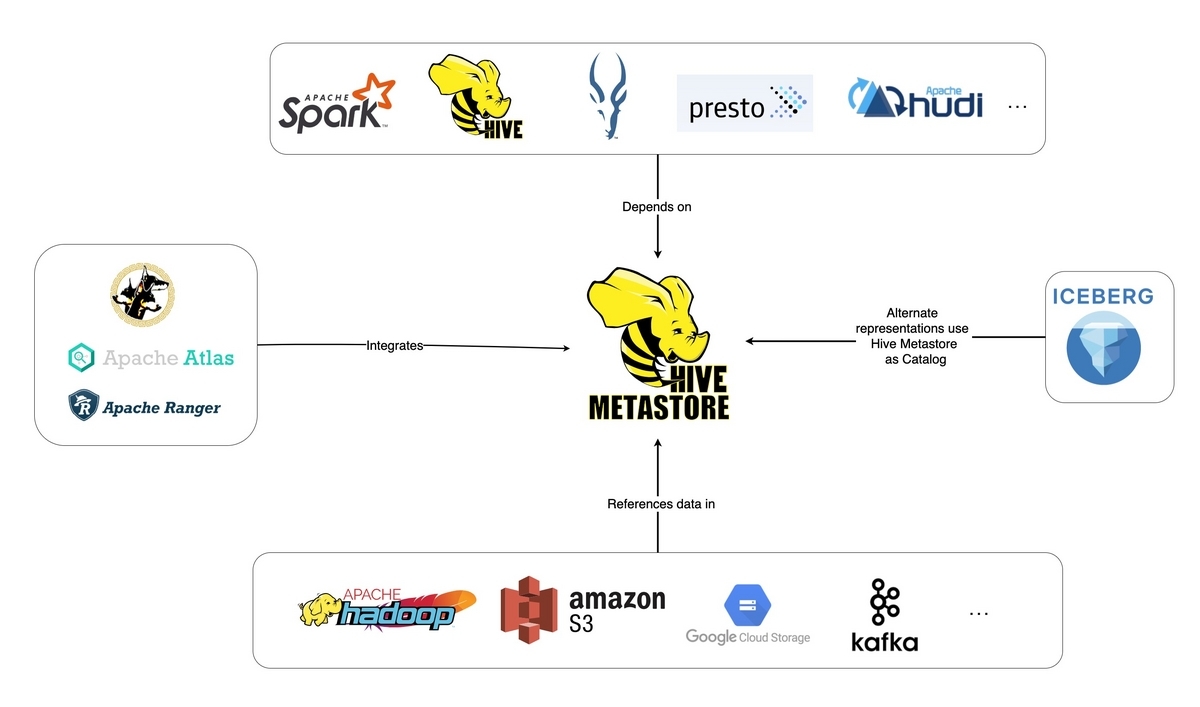
Hive Metastoreは様々なエンジン、ツールにサポートされており、非常に多くの採用事例がある。Icebergの導入も、現状のHive Metastore/Hive tableの課題を解決する流れで検討されることも多いだろう。一方で、Hive Metastoreを現状運用していない場合にIcebergのためだけにHive Metastoreを扱うのは、構築、運用の手間がかさむかもしれない。
使い所
- すでにHive Metastore, Hive Tableを利用している場合
参考
- CPU使用率90%を超える高負荷がLNEのHive Metastoreで発生 Hive table formatの課題はApache Icebergで解消
- ログパイプラインの4つの問題にLINEはどう立ち向かうかシンプルかつ拡張性のあるアーキテクチャを叶える、Icebergという選択肢
JDBC Catalog
org.apache.iceberg.jdbc.JdbcCatalogによって、MySQLやPostgreSQLなどのデータベースでIcebergのメタデータファイルをポイントする方式。JDBC Catalogで使用するデータベース自体は多様な選択肢があり得る。DB側の信頼性確保の仕組みなど、DBの機能を活用できる点が魅力である。ただし、Icebergを利用する各ツール、エンジンでJDBCドライバをパッケージする必要があるのでデプロイが煩雑になる。また同時に、それが可能なツール、エンジンしか選択出来なくなる点は考慮が必要である。
応用例としてJDBC CatalogをREST APIでラップする方法も考えられ、それによって先述の懸念点を緩和することが出来る。
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:1.4.1 \
--conf spark.sql.catalog.my_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.my_catalog.warehouse=s3://my-bucket/my/key/prefix \
--conf spark.sql.catalog.my_catalog.catalog-impl=org.apache.iceberg.jdbc.JdbcCatalog \
--conf spark.sql.catalog.my_catalog.uri=jdbc:mysql://test.1234567890.us-west-2.rds.amazonaws.com:3306/default \
--conf spark.sql.catalog.my_catalog.jdbc.verifyServerCertificate=true \
--conf spark.sql.catalog.my_catalog.jdbc.useSSL=true \
--conf spark.sql.catalog.my_catalog.jdbc.user=admin \
--conf spark.sql.catalog.my_catalog.jdbc.password=pass
使い所
- (特にオンプレミスで)IcebergのためだけにHive Meta Storeを構築したくない場合
- チームのケイパビリティ等の観点でデータベースによる管理が好ましい場合
参考
Nessie Catalog
概要
Gitライクにデータレイクのトランザクションを管理するNessieのテーブルプロパティでメタデータファイルのパスをポイントする方式。Nessieならではの魅力として、Iceberg Tableは通常単一テーブル(クエリ)単位でのACIDしかサポートしないのに対して、Iceberg on Nessieはマルチテーブル、マルチステートメントでのトランザクションをサポートしている点が挙げられる。一方で懸念点として、各種エンジン、ツールのNessieサポートがHive Metastoreに比べ限定的である。また、本エントリを書いている2023/12/02時点でネット上の情報が限られている(定性的評価)ように見受けられる。仕組みや性能特性など気になるが、筆者も知見がなく要調査。
使いどころ
参考
REST Catalog
概要
Iceberg REST Open API specificationに準拠して任意のカタログ実装のインターフェースをRESTで提供する方式。(バックエンドの特定の実装を限定するものではない)REST Catalogの肝は、Iceberg Catalog実装に関わるロジックをRESTの先にあるCatalogサーバに寄せられる点にある。従って、ツール、エンジン側にライブラリを組み込まずに済み、デプロイが簡素化できる。また、バックエンドに任意の実装を使用できる柔軟性も魅力と言える。
使い所
- Iceberg Catalogをエンジン、ツールから疎にしつつ、実装を隠蔽して提供したい場合(JDBC Catalogを使用している場合など)
参考
- Iceberg's REST Catalog: A Spark Demo
- Tabular社がREST Catalogのサンプル実装を提供している
- REST Catalog Explained
- Apache Iceberg's REST catalog
マネージドなソリューション
ここまで大なり小なりセルフマネージドなソリューションを挙げてきたが、Iceberg Catalogをマネージドに提供する製品も存在している。そして恐らく多くの人にとってはマネージドなソリューションを利用するのが構築、運用共に最も簡単な選択肢だと思われる。Iceberg Catalogの構築、運用を事業者に委ねられるだけでなく、Catalogをホストするためのインフラを管理せずに済むし、負荷に応じたスケールや可用性、堅牢性、セキュリティの確保を任せることができるからだ。従って個人的な意見としては、特別な要件がなく、SaaSやクラウドを利用することに特段制約がないのであればマネージドなソリューションを利用しておくのが無難なのではないかと思う。
また、マネージドなIceberg Catalogの中には、TableのComapactionなどのテーブルメンテナンスを自動化する仕組みを提供しているものもある。そういった便利機能が使えるのもマネージドなソリューションの魅力だろう。
Icebergをサポートするマネージドなソリューションの例
- AWS Glue DataCatalog
- AWSのHive Metastore互換なサーバレスのData Catalog
- Dremio Arctic
- Tabular
- Tabularのデータプラットフォームが提供するTabular Catalog, Iceberg Tables
- Snowflake
- 外部のIceberg Tableを読み込む方式と、Snowflake上で管理されるNative Iceberg Tableを利用する方式が選択できる
参考
さいごに
Apache Iceberg Catalogの選択肢については詳しくない部分も多々あり、追記したほうが良さそうな情報があれば是非教えてください。
明日、Distributed computing Advent Calendar 2023 の3日目は、なんと3日連続でIcebergネタとなっています。楽しみです!!!