OpenSearchCon North America 2025のセッション「Next-Gen Search: How Uber and the OpenSearch Community Built a Cloud Native 3.0」をまとめます。

スピーカー
このセッションは、UberのPlatform Engineering組織でSenior Engineering Managerを務めるShubham Gupta氏によって行われました。
Gupta氏は、Uberの重要なプロダクトを支える高性能でスケーラブルな検索プラットフォームの開発において、複数のエンジニアリングチームを率いています。またOpenSearchのTechnical Steering Committee(TSC)メンバーとしても活動しており、オープンソースコミュニティへの貢献も積極的に行っています。
クラウドネイティブなOpenSearchを必要とした背景
本セッションでは、Uberでクラウドネイティブ、つまりサーバーレスなOpenSearchをどのように構築しているかについてお話しします。
Uberにおける検索の課題

Uberの検索システムが直面している独自の課題について説明します。
まず最も重要な特徴として、私たちの検索は位置情報に極めて特化しています。単純な地理的検索ではなく、ユーザーの現在地や目的地、配達先などの文脈を常に考慮する必要があります。
さらに、私たちが扱うデータの規模は膨大です。数十億もの料理や食料品、そして数十億の位置情報と道路の情報から適切な結果を見つけ出す必要があります。このような大規模なデータセットを扱いながら、同時に高いスループットとレイテンシーに敏感な複数のユースケースに対応しなければなりません。
検索の意図も非常に多様で、ユーザーが明確に欲しいものを知っている場合もあれば、探索的に新しいレストランや料理を発見したい場合もあります。
そして最後に、rerankの複雑さがあります。価格、配達速度、信頼性、パーティーサイズ、食事制限など、多数の要因を考慮して最適な結果を提示する必要があるのです。

Uberでは毎日500億件以上の検索を処理しており、これは50以上のユースケースにまたがっています。そして、これらの50以上のユースケースは、Uberにある150以上のクラスターによって支えられています。
Uber Eatsの検索ユースケース

検索のユースケースについて、Uber Eatsから具体的に見ていきます。
皆さんも使われていると思いますが、Uber Eatsアプリを開くとまず住所の設定を求められます。住所を設定し、それがアパートの場合は、配達してほしい場所のピンを選ぶように求められます。
その後、店舗とアイテムを含むおすすめフィードが表示されます。この選択が気に入らない場合は、特定のアイテムや店舗を検索できます。たとえば、Uberのサニービルオフィス近くでピザを検索するといった具合です。
興味深いのは、これらすべてのユースケースが検索問題として定式化され、検索プラットフォームによって支えられている点です。
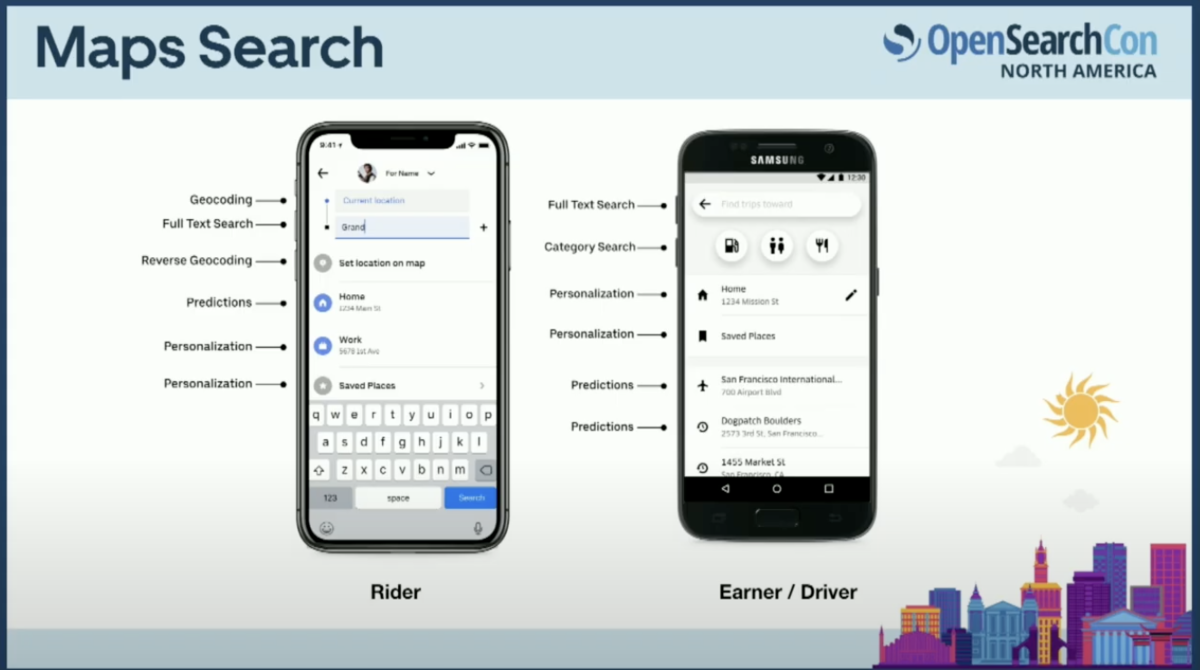
同様に、Uberのアプリにアクセスすると、乗客は目的地の住所を検索できます。ドライバーアプリでは、ドライバーが行きたい場所の住所を検索できます。
これらのユースケースも、同じ検索プラットフォームによって支えられています。
リアルタイムマッチング

より複雑でリアルタイムなユースケースとして、ライダーとドライバーのマッチングについて説明します。
このシステムでは大量のシグナルを受け取ります。主に2つのシグナルがあり、1つはドライバーアプリからのドライバーの位置情報、もう1つは乗客からの乗車リクエストです。これら2つのシグナルを取得する目的は、どの仕事がどのドライバーとどの場所にマッチするかを特定することです。
これらのシグナルを検索システムに入力し、クエリのフィルタリングとrerankを行います。例えば、サンフランシスコのチェイスセンター近くでUber XLに対応できるドライバーを2マイル以内で見つけるといった、非常に豊富なクエリを作成できます。
また、現時点で割り当てられていない食品配達の注文を見つけて、適切なドライバーを見つけるために、より複雑なクエリを作成することも可能です。
RAG/GenAI

RAGとGenAIのユースケースの話をしましょう。
Uberでは様々な苦情に対応する必要があります。たとえばドライバーからは書類の不備でアプリにアクセスできないとか、ユーザーからは、ドライバーの対応に問題があったので料金を支払いたくないといった苦情です。
これらの問題は2年前までは人間が解決していましたが、徐々に自動化を進めています。これらの問題を解決する方法は、近似最近傍探索または最近傍探索のようなソリューションを使用することです。
自動化の方法として、近似最近傍探索を使用しています。具体的には、過去のQ&Aコーパスをファインチューニングされた大規模言語モデルで埋め込みに変換します。新しい問い合わせが来たとき、そのクエリをベクトル化し、最も近い過去のQ&Aを見つけることで、適切な回答を提供できるようにしています。
このカンファレンスではベクトル検索に関する多くの講演があるので詳細は割愛しますが、これもUberで解決している問題の一つです。
OpenSearch導入以前のUberの検索プラットフォーム

現在の検索プラットフォームは、Apache Luceneを使用して構築されたカスタムソリューションです。
インジェスション用にLambdaアーキテクチャを採用しており、バルクインデキシングはSparkを使用して行い、ストリーミングインジェスションはKafkaを介して行っています。
このシステムは、ジオシャーディングのネイティブサポートを提供しています。また、Uberのユースケースに合わせた独自のインデックスレイアウトとクエリ演算子も提供しており、これらについては今後のスライドで詳しく説明します。
ケーススタディ:Uber Eats

Uber Eatsのケーススタディから始めて、複雑な問題をどのように解決しているかを説明します。
Uber Eatsには、フィードと検索という2つの主要な入り口があります。これらを通じて、消費者はレストラン、料理、食料品店、食料品、オファーなどの様々なインベントリタイプを発見できます。
パフォーマンス要件として、P50で50ミリ秒未満、P99で150ミリ秒未満でこれらを処理する必要があります。さらに、ピーク時には毎秒約10万件のドキュメント更新というスループットを処理しています。
転置インデックスと静的ランク

この要件にどう対応したかについて基本的なことから説明します。
Uber Eatsの店舗を表す4つのドキュメントがあると想像してください。インデックスを構築する最も単純な方法は、各セルが0または1である2次元行列を構築することです。1は特定の用語が特定のドキュメントに存在することを表し、0は存在しないことを表します。
たとえば、ドキュメント1にはCostcoとSunnyvaleが含まれ、ドキュメント2にはSafewayとSunnyvaleが含まれます。Sunnyvaleはドキュメント1、ドキュメント3にも存在します。
しかし、この方法はデータの疎性のため非常に非効率的なデータ構造となります。これはパフォーマンスの低下とストレージ要件の悪化を引き起こします。アイテムが増えれば増えるほど、この問題は悪化していきます。

そこで、Apache Luceneが提供する転置インデックスと呼ばれるデータ構造を使用しています。これは基本的に用語に対応するドキュメントIDを保存するだけのシンプルな構造です。転置インデックスは、用語からドキュメントIDのリストへのマッピングを含むデータ構造です。
しかし、このデータ構造に関してUberで直面する課題が2つあります。
1つは、複数の転置インデックスにまたがる多数のクエリがあることで、その数は数百、時には数千にものぼります。2つ目は、これらの転置インデックスが非常に長いため、すべてを網羅的に検索しようとすると、P99で150ミリ秒以内に回答することができません。
そこで、静的ランクと呼ばれる概念を考案しました。静的ランクは本質的にアーリーターミネーションを可能にする仕組みです。これは、オフラインで計算する特定の制約に基づいてドキュメントIDを並べ替えることを意味します。Uber Eatsの文脈では、人気度として考えることができます。
例えば、Costcoのチキンナゲット(ドキュメント5)は他のアイテムよりも人気があるといった具合です。これらはオフラインで計算される静的な値で、パーソナライズは含まれません。
多くの転置インデックスがある中で、時間枠内でどれだけ処理できるかに基づいてアーリーターミネーションし、一致するドキュメントを返します。ただし、このインデックスをソートする計算量が多い問題があり、これを解決する方法について後ほど説明します。

また、rerank用の特徴を保存するためにForwardインデックスも使用しています。これは、取得後のrerank時に、ユーザーのためにより動的なスライシングとダイシングを行い、パーソナライズを追加するのに役立ちます。
カスタム結合

Uber Eatsの独自要件のために開発した主要な機能の1つは、店舗とアイテムを横断するフィルタリングです。事前に正規化されたコンテンツを使用しているため、インジェクションファンアウトを避けるために、独自の結合の概念を考案しました。これは一般的なブロック結合とは異なるアプローチです。
このアプローチは4つの異なる側面で大幅に役立ちました。基本的な考え方は、インデックス内の店舗とアイテムを並べ替えることです。
例えばCostco、Safeway、Targetの3つの店舗があり、それぞれにアイテムがあると想像してください。転置リストは、最も人気のある店舗、次にその店舗内で人気のあるアイテム(グローバルではなくその店舗内での人気度)、次により人気の低い別の店舗であるSafeway、そしてSafeway内で人気のあるアイテムという順序で構成されます。

このアプローチでは、2段階のソートされたルックアップを連動させてナビゲートします。特定の親イテレーターポインター(例えばドキュメントID 0)から始めて、これがクエリに適格な場合、まずその店舗内のすべての一致するアイテムを調べることができます。
重要なのは、すべてを網羅的に検索するのではなく、店舗間で十分なコンテンツの多様性を確保しながら早期終了できることです。つまり、店舗を反復し、次にアイテムを反復し、別の店舗に移動してさらにアイテムを反復するという流れで、インデックスを使い尽くすか十分な店舗とアイテムを取得するまで続けます。
しかし、更新が来るたびに転置リストをソートするのは計算量が多く理想的ではありません。この問題を解決するため、リーダーとライターを分離しました。ライターは更新を消費し、ソートされたインデックスをディスクにフラッシュし、そのインデックスをリーダーに送って読み取らせます。
このカスタムジョインには新鮮さと効率の間にトレードオフがありますが、このモデルは任意のネストされたジョインに拡張可能です。
Concurrent Search
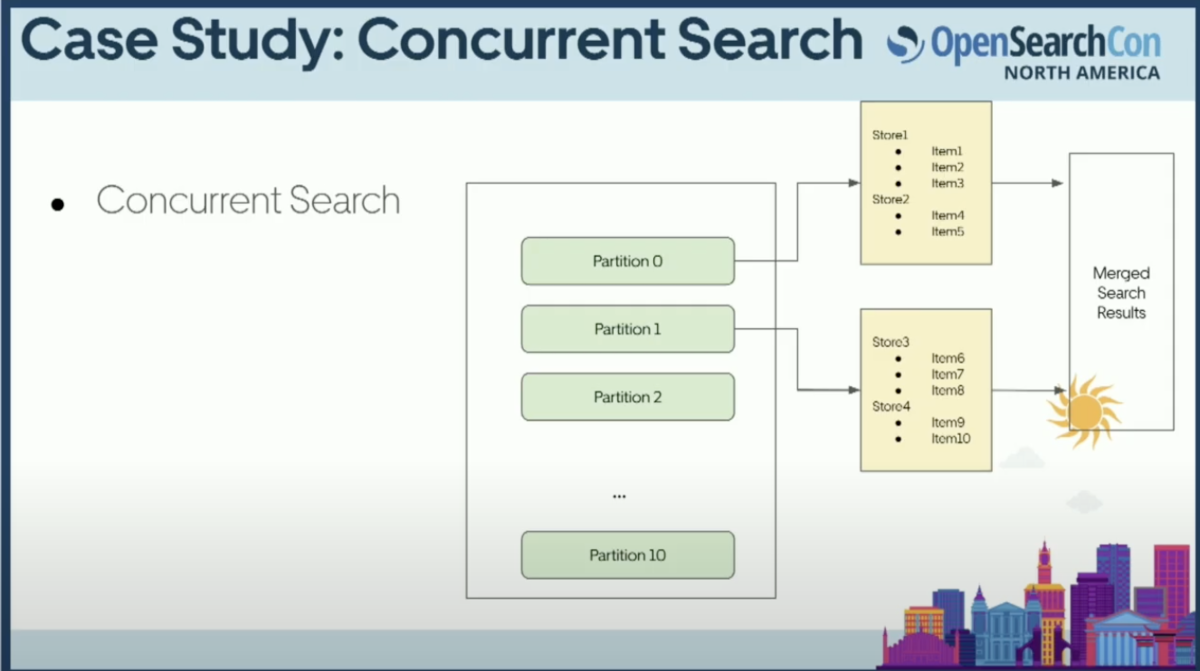
最後に、システムにConcurrent Searchと呼ばれる機能も組み込みました。これは、シャードを単一のファイルセグメントとして考えるのではなく、大きなファイルセグメントをより小さなファイルやサブシャードに分割するという考え方です。
より多くのCPUを使用してより高性能なクエリを実現するというトレードオフはありますが、KNNやNNスタイルの検索で興味深い結果が得られました。各サブシャードのKを調整できるため、追加のコンピューティングを行わずに済みます。直感に反するかもしれませんが、これは本番環境で実際に観察した結果です。
CPUを過度に使用することなく、より高速でより高品質なベクトル検索を実現することができました。
アーキテクチャの全体像

アーキテクチャの全体像について説明します。
クライアントからの読み取りと書き込みを受け付けるゲートウェイがあります。書き込みはKafkaに送られ、Kafkaにはingestorと呼ばれるサービスがあります。これはKafkaからデータを消費して、先ほど説明したソートされたインデックスを作成します。
そのインデックスはリモートストレージ(S3やHDFSなど)に送られます。searcherサービスは定期的にこれらのセグメントを独自のペースでダウンロードし、ゲートウェイを介して来る読み取りリクエストを処理します。
また、ブートストラップ時やバックフィル時にSparkを使用してオフラインインデックスを構築するオプションもあります。
OSSへの参加

ここまで説明した仕組みは2024年初頭までは素晴らしいシステムでしたが、2つの大きな課題が見え始めました。
1つ目は、製品チームから寄せられる新機能リクエストの速度に追いつけないことでした。2つ目は、特にセマンティック検索の分野で多くのシステム改善が業界で進んでおり、このサイロ化されたエコシステムではそれらを取り入れることができないことでした。
結果として、私たちはオープンスタンダードを受け入れ、活気あるOpenSearchコミュニティと協力することを決めました。

その結果、2024年9月にOpenSearchソフトウェア財団の創設メンバーとして参加しました。
私たちは多くの皆さんとOpenSearch 2025ロードマップを共同で作成し、UberでOpenSearchの採用を始めました。これは、UberでOpenSearchクラスターがまだ本番利用されていないという意味ではありません。
ただ、非常に重要なビジネスクリティカルなユースケースはまだOpenSearchで実行されていないということです。現在は、多くのテールユースケースからOpenSearchへのオンボーディングを開始しています。
クラウドネイティブなOpenSearch
OpenSearchクラスターマネージャーの現状

OpenSearchにおけるクラウドネイティブとは何を意味するのか、その詳細に入る前に、OpenSearchのクラスターマネージャーについて説明しておきます。
OpenSearchのクラスターマネージャーには2つの重要な役割があります。1つ目は、同期的な更新を実行することです。単一のモノリシックなBLOBストアに、すべてのノードにわたるメタデータをキャプチャします。
2つ目は、すべてのノードで同期的なRPCコールを作成し、すべてのノードでメタデータが一貫していることを確認することです。
クラスターマネージャーの問題点

同期的なクラスターマネージャーには多くの問題があります。
まず、クラスターサイズが200ノードを超えると信頼性のリスクが発生します。信頼性のリスクは主に可用性の低下という形で現れ、これは非常に頻繁に発生します。
また、一時的なネットワークの途切れによる頻繁なシャードの移動も発生します。これは主に、複数のプロバイダーにわたってこのようなシステムを実行しているためです。
ローリングアップグレードのサポートが不足していることも問題です。
さらに、異種シャーディングのサポートも不足しています。具体的には、シャードごとに異なる数のレプリカを持つことができません。私たちの場合、位置情報に特化した検索のため、シャード間でクエリの分布が不均一になります。すべてのシャードに同時に散布収集するのではなく、1つのクエリが特定の1つまたは複数のシャードにのみ送信されることが必要なのです。
クラウドネイティブクラスターマネージャーのビジョン

では、私たちが何を実現したいのか説明します。この図は少し複雑ですが、やろうとしていることは主に2つです。
1つ目は、すべてのノードにわたる同期的なメタデータ更新を非同期にすることです。2つ目は、メタデータを分解し、各ノードがその役割に応じて必要なメタデータだけを受け取れるようにすることです。すべてのノードがクラスター全体のすべてのメタデータを受け取る必要はありません。
より具体的には、Controller/Config Storageと呼ぶコントローラーを持ちます。これは、すべてのノードにわたるメタデータを管理し、そのメタデータをetcdのようなストアに保存します。
データノード、コーディネートノード、インジェスターノードは、クラスターマネージャーからの指示を待つのではなく、それぞれが独自のペースでetcdウォッチャーを通じてメタデータを取得します。
現在までの実装状況

私たちはこの取り組みを開始しており、これまでにコントロールプレーンの変更のための新しいリポジトリを作成しました。
このリポジトリには、クラスターメタデータをリモートストレージ(etcd)に保存し、各役割に応じた特定のメタデータを保存する機能が含まれています。例えば、コーディネーターノードはすべてのデータノードのメタデータを受け取りますが、データノードは自身に関連するシャードレベルの情報のみを受け取ります。
また、データプレーンの変更も行いました。これにより、データノードはリモートクラスターか従来の同期クラスターかを意識する必要がなくなります。今後、このリポジトリに関連するコード変更を継続的にプッシュしていく予定です。
今後の取り組み

最終的に私たちが目指しているのは、OpenSearchをサーバーレス、あるいはチームメンバーの中にはクラスターレスと呼ぶ人もいますが、真にクラウドネイティブなものにすることです。現在この道を進んでおり、年末までにプロトタイプが稼働することを期待しています。コードは継続的にプッシュしていますので、興味がある方はぜひご覧ください。
コントリビューションも歓迎します。いくつかのRFCがすでにオープンされていますので、レビューやコメントをお待ちしています。
このクラウドネイティブな取り組みに加えて、Term based shardingとTerm based routingをOpenSearchにコントリビュートする予定です。これは既存のUIDベースのシャーディングとは異なるアプローチです。
また、Spark上で完全にOpenSearchのバッチインデックスを構築する機能にも取り組んでいます。これにより、インデックス作成のためだけにクラスターを起動する必要がなくなり、Spark上でOpenSearchインデックスを構築して別のクラスターに送ることができるようになります。
先ほど説明した効率的な親子結合もOpenSearchにコントリビュートする予定です。すでにLuceneにコードをコミットしており、将来的にはGPUをサービング層で活用する計画もあります。
QA

質問1:OpenSearchの実行環境について
回答:UberのOpenSearchインスタンスは現在オンプレミスで稼働していますが、OCIクラウドへの移行も計画しています。OpenSource OpenSearchを自社で実行しており、マネージドサービスは使用していません。複数のプロバイダーにわたって実行しており、オンプレミスとクラウドの両方にゾーンがあります。これが、ネットワークの不具合によるシャードの移動が頻繁に見られる理由です。
質問2:オートスケーリングの仕組みについて
回答:現在2つのシステムが稼働しています。1つはOpenSource OpenSearch、もう1つはカスタムソフトウェアのLuceneプラスです。Luceneプラスでは、垂直スケーリングと水平スケーリングを実行しており、Uberのクラスターマネージャーによって管理されています。シャードごとに異なる数のレプリカを持つため、シャード単位でスケーリングを行っています。一方、OpenSearchは標準構成で実行しており、単一のハードウェアフリートをクラスターマネージャーがバランスを取っています。将来的にはこの機能をOpenSearchに導入し、ホットなシャードだけを効率的にスケーリングできるようにしたいと考えています。
質問3:検索効率を高めた方法について
回答:効率を高めた方法は4つあります。まず、インデックスをソートし、2段階のロックステップイテレータを使用することで、多くのイテレータスキップを回避できます。都市ベースの店舗を1つの場所にまとめることで、CPUのL0、L1キャッシュを効率的に使用でき、レイテンシーコストの大部分を節約できます。また、ソートされた配列でデルタエンコーディングを使用することで、インデックスサイズを大幅に縮小し、結果としてレイテンシーも改善しています。
質問4:親子関係のデータソースについて
回答:データはカタログから来ています。カタログは固定されており、例えばCostcoやSafewayにどのようなアイテムがあるか正確に把握しています。これがすべての親ポインターのソースです。時間の経過とともに、アイテムの人気度が変化すれば順序も更新されますが、親子関係の基本的なポインターはカタログが真のソースとなります。
質問5:クラウドネイティブ取り組みのタイムラインについて
回答:現時点では公開できる具体的なタイムラインはありませんが、クラウドネイティブな取り組みのプロトタイプを来年の初めまでに稼働させることを目標としています。その後、より広く公開できると考えています。
質問6:ドキュメントの一般的なサイズについて
回答:ユースケースによって異なりますが、Uber Eatsに特化して言えば、ドキュメントはアイテムまたは店舗として格納され、かなり小さく数キロバイト程度に制限されています。Forwardインデックスにreranking用の特徴も格納していますが、それを含めても1ドキュメントあたり数キロバイトを超えることはありません。
質問7:ベクトル検索について
回答:Uberでは現在ベクトル検索を使用しており、バニラのLuceneのベクトル検索サポートを利用しています。高次元のベクトルをそのまま使うのではなく、スカラー量子化や積量子化などの量子化技術を活用しています。Luceneが提供するスカラー量子化から大きな恩恵を受けており、またサブシャードを使用してKを調整することで、各サブシャードから取得するアイテム数を削減し、並列処理を改善しています。
質問8:シャード分割について
回答:現在シャード分割はあまり行っていません。必要な場合は手動で対応しており、新しいクラスターを作成してトラフィックをティーし、その後古いクラスターを廃止するという方法を取っています。少し手作業的ですが、現時点ではこの方法で運用しています。
質問9:Forwardインデックスの使用目的について
回答:Forwardインデックスは検索には使用していません。検索段階で取得したコンテンツを再ランク付けするために使用しています。転置インデックスでコンテンツを取得し、静的ランクで早期終了した後、埋め込みや異なる特徴を使用してrerankingを行います。Uberではロジスティック回帰を多く使用しており、現在は深層学習モデルへの移行も進めています。Forwardインデックスは、OpenSearchで言うところのStored Fieldsに相当します。
質問10:スキーマ管理について
回答:Uberでは非常に厳密に型付けされたスキーマを構築しており、Uberのエコシステムとうまく連携しています。OpenSearchの動的マッピングは危険なことが多く、過去に問題を経験したため、Uberでは動的マッピングの使用を許可していません。代わりにAtlasベースのような内部スキーマを使用しています。これはまだOpenSearchにコントリビュートしていない部分ですが、将来的には移行の機会があると考えています。