Bytedanceが発表した、人物の画像を元に動画を生成するモデル「MagicAnimate」を試したので知見を記しておく。
基本的にはオフィシャルのGetting Startedに従っておけば動くのだが、進めていて一部詰まる箇所があったので、誰かしらの役に立つのではないかと思っている。
何ができるの?
人物が写った画像(以下動画左)と、動きを定義するシーケンス(以下動画中央)をインプットとして、人物が動いている動画(以下動画右)を生成できる。
ByteDanceのMagicAnimateを試食中。左の画像を入力として、中央のMotion Sequenceに沿って動かしてくれる。VRAM24GB環境で推論時間4分程度。幅広い画風に対応してる印象。Motion Sqeuenceの出来が完成品を左右するので、これをいい感じに作れる職人が求められてる。「シーケンスエンジニアリング」的な pic.twitter.com/Ac202JsEHH
— べりんぐ (@_Bassari) December 8, 2023
踊る牛久大仏 pic.twitter.com/WknwBhK9k3
— べりんぐ (@_Bassari) December 8, 2023
踊るヘンリ8世 pic.twitter.com/gLAj33Gp8k
— べりんぐ (@_Bassari) December 9, 2023
どうやって使うの
方法1:Hugging FaceのSpace上のデモページを使う
すぐに試したい場合はBytedanceが公開しているデモページが使える。ただし、使えるマシンリソースや細かいチューニングには制限がある。 https://huggingface.co/spaces/zcxu-eric/magicanimate
方法2:任意の環境にモデルをセルフホストする
モデルはBSD-3-Clauseで配布されているので、任意の環境にホストして動かすことができる。以降、本記事ではこちらの方式について解説する。
環境
Amazon EC2を使用した。
インスタンスタイプ
g5.2xlarge(A10G Tensor Core GPU、VRAM24GB)

この環境で、Sampling steps 25、Guidance scale 7.5(推論時のパラメータ)の場合で推論時間は4分前後であった。
OS(AMI)
Amazon Linux 2ベースのDeep Learning OSS Nvidia Driver AMI GPU PyTorch 2.0.1(CUDA等の環境が整っており便利であるため)
手順
マシンにsshで繋ぎ込んだ状態からスタート。基本的にはオフィシャルのGetting Startedに沿って進める。
MagicAnimateを動かすprerequisitesはpython>=3.8, CUDA>=11.3だが、これらはAMIにビルトインされている。
前準備
MagicAnimateをダウンロード
git clone https://github.com/magic-research/magic-animate cd magic-animate
依存関係をインストール
python -v venv myenv source myenv/bin/activate pip install -r requirements.txt
pretrained_model, checkpointsをダウンロード
# mainでも動くかも git clone -b fp16 https://huggingface.co/runwayml/stable-diffusion-v1-5 pretrained_models/stable-diffusion-v1-5/ git clone https://huggingface.co/stabilityai/sd-vae-ft-mse pretrained_models/sd-vae-ft-mse/ git lfs clone https://huggingface.co/zcxu-eric/MagicAnimate pretrained_models/MagicAnimate/
ディレクトリ構造は以下のようになる。
tree -L 1 pretrained_models/ pretrained_models/ |-- MagicAnimate |-- sd-vae-ft-mse |-- stable-diffusion-v1-5
ffmpeg, ffprobeのインストール
sudo mkdir /usr/local/ffmpeg sudo wget -P /usr/local/ffmpeg https://johnvansickle.com/ffmpeg/releases/ffmpeg-release-amd64-static.tar.xz cd /usr/local/ffmpeg sudo tar -xf ffmpeg-release-amd64-static.tar.xz sudo ln -sfn /usr/local/ffmpeg/ffmpeg-*-amd64-static/ffmpeg /usr/bin/ffmpeg sudo ln -sfn /usr/local/ffmpeg/ffmpeg-*-amd64-static/ffprobe /usr/bin/ffprobe sudo rm ffmpeg-release-amd64-static.tar.xz ffmpeg -version ffmpeg version 6.1-static https://johnvansickle.com/ffmpeg/ Copyright (c) 2000-2023 the FFmpeg developers built with gcc 8 (Debian 8.3.0-6) ffprobe -version ffprobe version 6.1-static https://johnvansickle.com/ffmpeg/ Copyright (c) 2007-2023 the FFmpeg developers built with gcc 8 (Debian 8.3.0-6)
デモアプリを立ち上げる
この時点でscripts/animate.shを実行すればCLIベースで生成することもできるが、ここでは操作の取り回しが良いGradioベースのwebアプリケーションを立ち上げる。
デモアプリはGradioで作られており、実体はdemo/gradio_animate.py, gradio_animate_dist.pyである。(後者のgradio_animate_distは複数のGPUを積んだマシン向けの並列推論用).
起動する前に、デモアプリのちょっとしたバグを修正しておこう。demo/gradio_animate.pyの95行目(末尾付近)にdemo.queue(1)を追記する。
demo.queue(1) # この行を追記 demo.launch(share=**True**)
これが必要な理由は、GradioのWeb UIからサーバーサイドに推論をリクエストした際のタイムアウト仕様が関係している。元のコードでは、Gradioの内部仕様上、リクエストから60秒が経過するとタイムアウトとなり504として処理されてしまう。しかし実際には、MagicAnimateの推論には60秒以上かかる可能性が高いため、常にタイムアウトになってしまう。queue(1)を挟むことでタイムアウトの制限がなくなるため、これをワークアラウンドとする。
参考:Gradio fn function errors right after 60 seconds
それではいよいよデモアプリを立ち上げよう。
python -m demo.gradio_animate #中略 Initialization Done! Running on local URL: http://XXXXXX:7860 Running on public URL: https://XXXXXXXXXXXXX.gradio.live
URLにアクセスすると、以下のページが表示される。
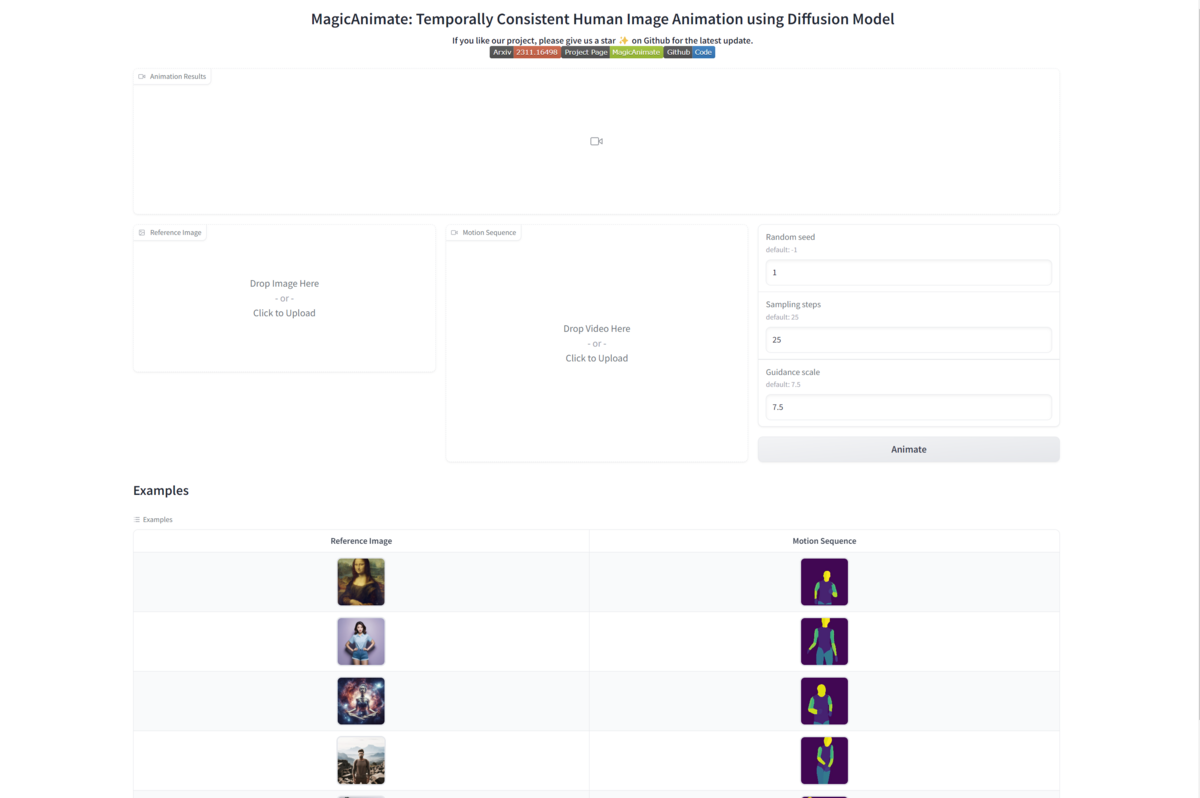
Reference Image, Motion Sequence, Random Seed, Sampling Steps, Guidance scaleを指定して「Animate」をクリックすると推論が始まる。
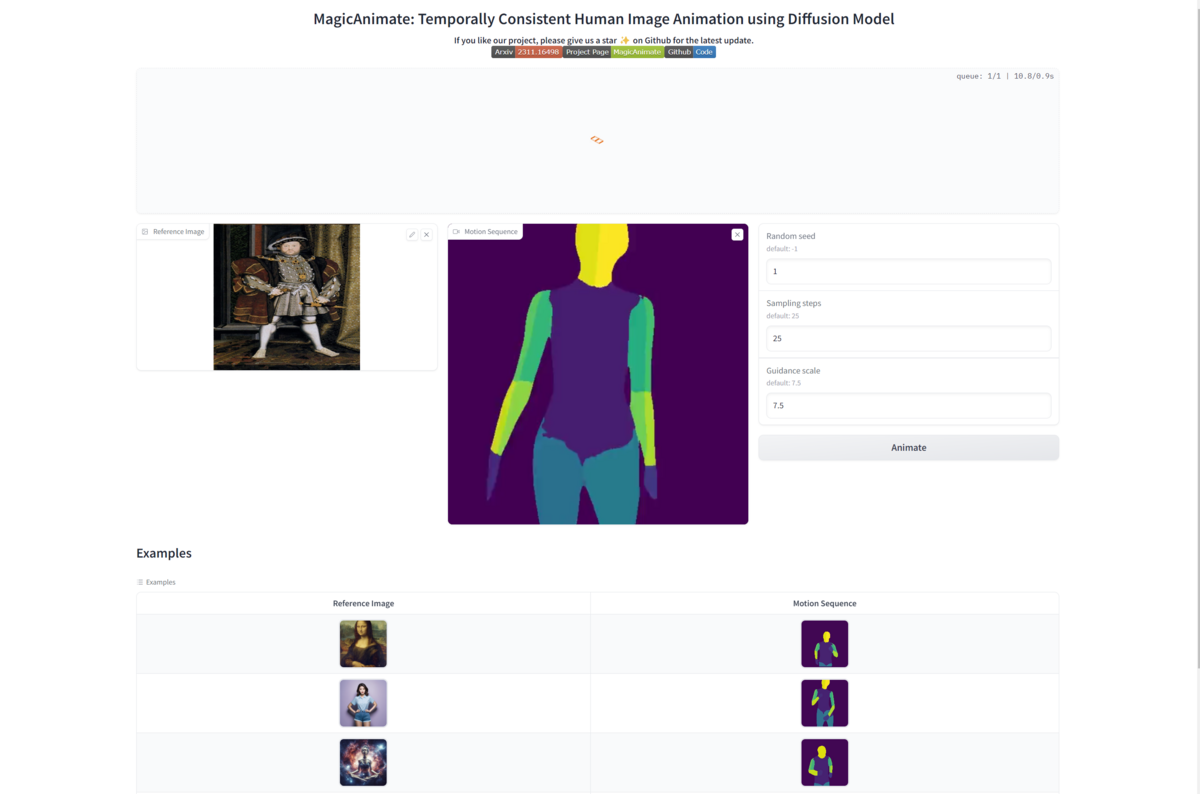
推論が完了すると生成された動画が画面に出力され、demo/outputs/に格納される。Sampling Stepsを大きくすれば推論時間が増加する代わりに、品質が上がる可能性がある。

生成される動画の動きや、人物の体型はMotion Sequenceに左右されるため、これをいい感じに作れる人が求められていると思う。
以下は坂本アヒル先生のずんだもんを動かそうとして失敗した例。
失敗例(Motion Sequenceが動かしたい人物の体格に近くないと破綻しちゃうっぽい) pic.twitter.com/oImtc0Llmz
— べりんぐ (@_Bassari) December 9, 2023
公式のReference ImageとMotion Sequenceを使って生成した例。Sequenceが画像に最適化されていることが分かる。いい感じの動画を作るには画像ごとにいい感じのSequenceを作って上げる必要があるんだろうなぁ pic.twitter.com/EQ0rcIjpuX
— べりんぐ (@_Bassari) December 9, 2023
また、顔の作りが写実的ではない画像や、体形が人間離れしていると上手く生成できないようだ。
真ずんだもん立ち絵ver.2で実験。耳としっぽが正しく認識出来てなくて背景がおかしなことになっている。顔が崩れてしまうのはデフォルメされてると上手く対応できないのかな(ByteDanceのサンプル画像は全て写実的)https://t.co/46O2Tkzxvi pic.twitter.com/fTCJv1V7ZK
— べりんぐ (@_Bassari) December 9, 2023
Enjoy!