
- はじめに
- オープンなモデルの急速な進化
- スケーラブルでコスト最適なAI Chat Bot(RAG)の作り方を考える
- おわりに
記事中のサンプルアプリケーション、コードはGithubで公開している
記事を通じて、以下のようなアプリケーションが作れるようになっている
はじめに
生成AIに注目が集まる昨今、SaaSベースのLLMを使ったチャットアプリケーションや検索サービスと組みわせたRAGアプローチが盛んに論じられている。一方で、オープン(≒OSS)なモデルをサーバ上でスケーラブルかつコスト最適にセルフホストする方法や、サービス全体の設計に組み込む方法についてはそれほど議論が盛り上がっていない印象を受ける。そこで、本エントリではオープンなモデルを活用する意義を整理しつつ、セルフホストなRAGアプリケーションの基本的な作り方と設計を最適化するためのいくつかのアイデアを示す。
関連情報:
オープンなモデルの急速な進化
オープンなモデルとは
本エントリでの「オープンなモデル」というのは、用途を厳しく限定せず、主にHugging Faceで無償配布されているモデルを指している。OSSと呼ばずに回りくどい書き方をしているのは、生成AIモデルが何をもってオープンソースと解せるかに関して、訓練時のパラメータの開示有無や商用利用の可否など多様な論点があるからだ。ここでは厳密な定義に拘らず、個人が気軽に使えればざっくり「オープン」ということにしておく。
オープンなモデルの活況
生成AIの世界ではOpen AIのGPT 3.5〜やGoogle DeepMindのGemini、AnthropicのClaudeなどのプロプライエタリなサービスが注目されがちだが、実は2023年には数多くのオープンなモデルが公開されてきた。
LLMに関して言えばCyberAgentのcalmや、elyza(東大松尾研発のスタートアップ)のELYZA、stabilityaiのJapanese StableLMなど日本語に対応したモデルが多数あるし、コード生成に特化したELYZA-japanese-CodeLlama-7bやテキストと画像をマルチモーダルに扱えるJapanese Stable VLMなども出てきている。2023年に発表されたモデルの数は、主要なLLMをざっと数えただけで50を超える。また、RAGに欠かせないEmbeddingsの領域ではintfloatのmultilingual-e5シリーズという大変優秀なモデルがある。その他にも本エントリでは掘下げないが、画像生成や音声合成、音声文字起こしなどについても日々新たなモデルが出てきている。
関連情報:
もちろん単に数が多いだけでなく、機能、非機能面でも注目に値する進化が続いている。例えば12月27日に公開された「ELYZA-japanese-Llama-2-13b」シリーズはベンチマーク上GPT-3.5(text-davinci-003)を上回る性能を誇っている。(ELYZA-japanese-Llama-2-13b発表の2日後、12/29に公開されたLightblueのQarasuはそれすら上回る性能であるとの触れ込みなのだから驚きだ)



関連情報:
また、embeddingの領域ではintfloat/multilingual-e5-largeはOpen AIなどが提供するEmbeddingsと同等以上の日本語性能を備えている。
関連情報:
オープンなモデルをセルフホストする利点
主にSaaS型のモデルを利用する場合との対比で、オープンなモデルをセルフホストする利点を整理する。
コスト効率
オープンなモデルは無償で手に入るので、モデル自体の利用にコストは発生せず、それをホストするインフラの調達、構築、運用のコストのみが問題になる。この特性によってSaaS型のモデルを利用する場合に比べてコスト効率が良くなる可能性がある。
ただ実際のところ、SaaS型のサービスは規模の経済や高度な最適化によって安価にモデルを提供できる。また、そうしたサービスは従量課金で提供されるため、実際に使用している間しかコストが発生しない。従って、SaaS型のモデルを利用する場合よりセルフホストの方がコスト効率が良いとは必ずしも言い切れない。
しかし、セルフホストについても、クラウドを使った柔軟なリソース確保や、負荷に応じたスケールなどの工夫によってコスト最適化の工夫の余地はある。また、セルフホスト/SaaSの二者択一ではなく、アプリケーションの構成要素の一部はセルフホスト、一部はSaaSで構成するようなハイブリッドなアプローチも考えられるはずだ。
例えば、RAGを構成する場合に、Embeddingに関しては比較的少ないVRAMでも高精度なベクトル変換が可能なセルフホストを用いて、検索結果を応答に要約する部分についてはSaaS型のLLMを使用するようなアプローチは私の観測範囲でも採用例が増えてきているように思う。
カスタマイズの自由度
SaaS型のサービスにおいて、利用者はエンドポイントの先で何が起きているかを知り得ない。「GPT-4」のエンドポイントをコールすることは、純技術的にLLMを利用しているというよりは、Open AI社が提供する「GPT-4と呼ばれるサービス」を利用していると理解するべきだ。極論すれば、APIの先でLLMではなく人間が人力で回答を入力していたとしても利用者は感知し得ないし、それによって満足できる性能が発揮されるならば文句を言う筋合いでもない。(厳密にはガバナンスの観点で問題はあるが)
関連情報:
SaaS型のサービスの「マネージド」な特性をポジティブに捉えれば、利用者は背後の複雑性を意識する必要がないため、個々の利用者にとって本質的なプロダクト/ビジネス価値の最大化に集中できる。しかしながら、負の側面に目を向けると、利用者は推論時のパラメータなどをチューニングすることが出来ないし、サービスのバージョンをコントロールすることも出来ない。ある時点で得られた結果が別のある時点ではモデルのアップデートによって再現しないといった事態も考えられる。そうでなくても、Chat GPTの気まぐれなレスポンスの遅さにイライラした経験がある人は少なくないはずだ。
また、SaaS型のサービスが出力する生成物は様々な基準によって「健全」に保たれる場合が多いため、何が「健全」であるかを自分で決めたい人にとってSaaSは窮屈かもしれない。それらの点において、モデルの挙動をより細かくコントロールできるセルフホストの特徴が利点になることもあるだろう。
選択肢の多様性
SaaS型のサービスとして提供されるモデルはある程度普遍的な需要に応えるものである可能性が高い。従って、ニッチなニーズに応えることができるモデルの供給は限定的になるかもしれない。例えば、世界的な展開を指向する事業者が日本の歴史や文学に特化したモデルを供給するモチベーションは薄いはずだ。その点でセルフホストであれば多様な選択肢から好みのモデルを選ぶことが出来る。
データのプライバシーとセキュリティ
SaaS型のLLMにプロンプトを投入して応答を得る上では、データのプライバシーやセキュリティが問題になる可能性がある。個人が趣味で扱う場合や、ちょっとしたPoCレベルであれば気にすることはないだろうが、責任ある企業が機微な情報を扱う場合は話が変わってくる。もちろんOpen AIをはじめとする事業者はユーザが投入したデータの安全な扱いについて一定のポリシーを示しているが、それをどう評価し、どのレベルまで受け入れるかは別の問題だ。
仮に法人としての事業者の善意に全幅の信頼を置くにしても、事業者の環境が攻撃者に侵害された場合や、事業者内での内部犯行のリスクなども鑑みると話はそれほど単純ではない。SaaSが日本国外でホストされている場合、何らかの規制要件によってデータローカリティがネックになることもあるだろう。
実際のところ、既に大々的にSaaS型のLLMを導入している企業の中でも、投入可能な情報には一定のルールがあるのが一般的で、顧客情報などを無制限に投入可能な例は珍しいのではないかと思う。その点で、モデルをホストするマシンやネットワークを自らの手で統制できるセルフホストの方が都合が良い場面はあるはずだ。(これとは別に、ホスト先をオンプレミスにすべきか、クラウドでも良いのかは深遠な論点である。実務的には画一的なポリシーを当て嵌めるというよりは、データの種類や量、用途などによってティアリングすることが多いだろう)
チームのケイパビリティ向上
ここまでに挙げたのとは毛色の異なる観点だが、「モデルを効率よくセルフホストし、アプリケーションに組み込む能力」をチームのケイパビリティとして備えておくことは、技術組織としての中長期的な優位性につながり得るはずだ。
先述の通り、2023年以降非常に多くのオープンなモデルが登場しており、日進月歩で改善が進んでいる。この状況は当面続くと考えられ、いずれはプロプライエタリと同等かそれ以上の精度、コスパを備えたモデルも出てくるかもしれない。そのような時代にあって、モデルの供給状況をウォッチし、適切に評価し、効果的に利用できることはそれ自体が非常に価値のある能力であるはずだ。その意味で、個人的にはこれがいま時点でオープンなモデルをセルフホストする最大の利点ではないかと思っている。
スケーラブルでコスト最適なAI Chat Bot(RAG)の作り方を考える
ここからは表題に立ち返り、オープンなモデルのみを使ったスケーラブルでコスト最適なAI Chat Bot、もといRAGアプリケーションの作り方を考える。
RAGアプローチの構成要素
RAG、つまり「Retrieval-Augmented Generation」は、文字通り「情報検索によって強化された生成」を意味する。これは、従来の言語生成モデルに情報の検索と統合の機能を加えたものだ。例えば、最新のニュースや特定の専門分野に関する質問に対して、最新のデータや専門的な知識に基づいて回答するため、生成できるコンテンツの豊かさと正確さが向上する。
RAGは二つの主要な部分から成り立っている。入力されたクエリに基づき関連情報をデータベース等から探し出す情報エンジン、そしてその検索結果を基に文章を生成するLLMだ。

検索エンジンには、伝統的なキーワードベースや、ベクトル検索による意味(セマンティック)ベースの検索、両者を組み合わせたハイブリッド検索などが用いられる。本記事では特にEmbeddingが活躍するベクトル検索を軸に紹介する。
ベクトル検索とは
ベクトル検索では、検索対象の文書を細切れ(チャンク)に分割した上で、それぞれ意味内容を多次元空間上の点として現すベクトル形式で表現する。その上で、検索時の文言も同じくベクトルに変換し、多次元空間上の近い位置にある点を発見することで、意味的に近い箇所を発見する。ここで、文書をベクトル表現に変換する際に用いるのが先般から言及しているEmbeddingモデルである。

ベクトル検索の前準備
- 元になる文書をチャンクに分割して、Embeddingモデルでベクトルに変換する
- 生成したベクトル(Embedding)を元にfaissなどの検索エンジンのindexを生成する
ベクトル検索の流れ
- ユーザーからのクエリをEmbeddingモデルでベクトルに変換する
- 2でベクトル化したクエリで、1でベクトルに変換した文書の中で意味的にクエリに近いチャンクを検索する
- ユーザからのクエリに対して意味的に近いチャンクが得られる

一連の流れの具体的な実装については、hotchpotchさんのRAG用途に使える、Wikipedia 日本語の embeddings とベクトル検索用の faiss index を作ったとwikipedia-passages-jawiki-embeddings-utilsが参考になる。
上記記事のリポジトリはテキストの分割、Embeddingへの変換、faiss indexの生成、ベクトル検索までの一連の処理を独自に実装しているため処理内容への理解を深めやすい。一方で、langchainを使えばそれらを隠蔽して、お手軽にEmbedding生成からベクトル検索までを実現することもできる。
from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings import HuggingFaceEmbeddings from langchain.document_loaders import TextLoader from langchain.vectorstores import FAISS loader = TextLoader("path_to_file") documents = loader.load() # テキスト分割の方式を指定 # see https://python.langchain.com/docs/modules/data_connection/document_transformers/text_splitters/recursive_text_splitter text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=300, chunk_overlap=20, ) splitted_texts = text_splitter.split_documents(documents) embed_model_id = "intfloat/multilingual-e5-large" embeddings = HuggingFaceEmbeddings(model_name=embed_model_id) # 分割したテキストをベクトルに変換した上で、faissのindexを作成 db = FAISS.from_documents(splitted_texts, embeddings) query = "検索クエリ" # 検索クエリをベクトルに変換して、意味的に近いチャンク上位5つを検索 docs = db.similarity_search(query, k=3) print(f"検索結果:") for i in range(len(docs)): print(docs[i])
langchainを用いる場合は処理が抽象化されている分、内側での処理が見えづらかったり、痒いところに手が届かなかったりすることもあるので、どちらを使用するかはケースバイケースで検討が必要だ。
なお、ここで用いられているFAISS(Fast Approximate Nearest Neighbor Search Library)は、Facebook AI Researchによって開発された高速で効率的な近似最近傍探索アルゴリズムを提供するライブラリである。FAISS自体は特別なプロセスやソフトウェアを用意しなくても、Pythonプロセス内でロードして使用できる。
(ベクトル検索に関して、ElasticSearchやpgvectorなどを「ベクトルDB」や「ベクトルストア」と呼んで利用することもある。ただ、検索対象のindexがそれほど大きくなく、性能や信頼性の要件がそれほど大きくない場合はカジュアルにfaissをロードして利用するだけで十分なケースも少なくない。個人的には、専用の「ベクトルDB」や「ベクトルストア」の導入を本格的に検討するのは、それが必要になってからで良いのではないかと思っている)
また、intfloat/multilingual-e5-largeはオープンなEmbeddingモデルである。
LLMのデプロイ
デプロイ方法
HuggingFaceで配布されているモデルであればデプロイ自体はそれほど難しいことではなく、どのモデルを使用する場合でも基本的にアプローチに違いはない。HuggingFaceの多くのモデルのModel Cardにはコピペで動くUsageが記載されているので、これを元にアプリケーションに応じてカスタマイズするか、必要に応じてlangchainなりを使えば良い。
ELYZA-japanese-Llama-2-13b-instructであれば以下のようになる。
import torch from transformers import AutoModelForCausalLM, AutoTokenizer B_INST, E_INST = "[INST]", "[/INST]" B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n" DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。" text = "仕事の熱意を取り戻すためのアイデアを5つ挙げてください。" model_name = "elyza/ELYZA-japanese-Llama-2-13b-instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.bfloat16, use_cache=True, device_map="auto", low_cpu_mem_usage=True, ) model.eval() prompt = "{bos_token}{b_inst} {system}{prompt} {e_inst} ".format( bos_token=tokenizer.bos_token, b_inst=B_INST, system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}", prompt=text, e_inst=E_INST, ) token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt") with torch.no_grad(): output_ids = model.generate( token_ids.to(model.device), max_new_tokens=256, pad_token_id=tokenizer.pad_token_id, eos_token_id=tokenizer.eos_token_id, ) output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1) :], skip_special_tokens=True) print(output)
必要なスペック
モデルを動かすには、そのパラメータ分のVRAM(GPU RAM)が基本的に必要になる。例えば1パラメータが16 bit(2 byte)のFloatでロードする場合、13Bのモデルであれば、13 * 2 = 26 GB程度のVRAMが必要な計算になる。実際には若干のオーバヘッドがあるため、少し余裕を持たせておいたほうが安全だろう。モデルのパラメータ数などの基本的な情報は、Hugging Faceの各ModelのModel Cardに書いてある。
モデルを動かすのに必要なVRAMを削減しつつ、推論の高速化を図る手法として量子化というアプローチがある。これはモデルのパラメータをより少量のビット数で表現することでモデルを軽量化するもので、代償としてモデルの精度が劣化する。
HuggingFace上では量子化済のモデルを提供している人も多くいるので、それらを用いることでお手軽に軽量版モデルを試すことが出来る。(例:mmnga/ELYZA-japanese-Llama-2-13b-fast-instruct-gguf)
関連情報:
なお、複数のGPUを搭載したマシンでは、 (現状デファクトである)transformersライブラリを利用する場合はdevice_map="auto"としておくことで分散的に推論を実施することが出来る。(vllmなどを使用する場合は別途手当が必要になる)
また、CPU RAMに関しても標準ではパラメータ分のRAMが必要になるのだが、AutoModelForCausalLM.from_pretrained時にlow_cpu_mem_usage=Trueとすることで必要メモリ量を半分程度に削減できる。また、device_map="auto"とすることでRAMに乗り切らない場合は適宜ディスクへオフロードする形になるため、実質RAMの要件はVRAMほどは厳しくはない。(これらのオプションは大抵のモデルのModel CardのUsageでは最初から指定されている)
End to Endなアプリケーションに仕立てる
ここまで紹介したベクトル検索とLLMを組み合わせて、適当なUIを実装することでRAG Chatアプリケーションを作ってみよう。
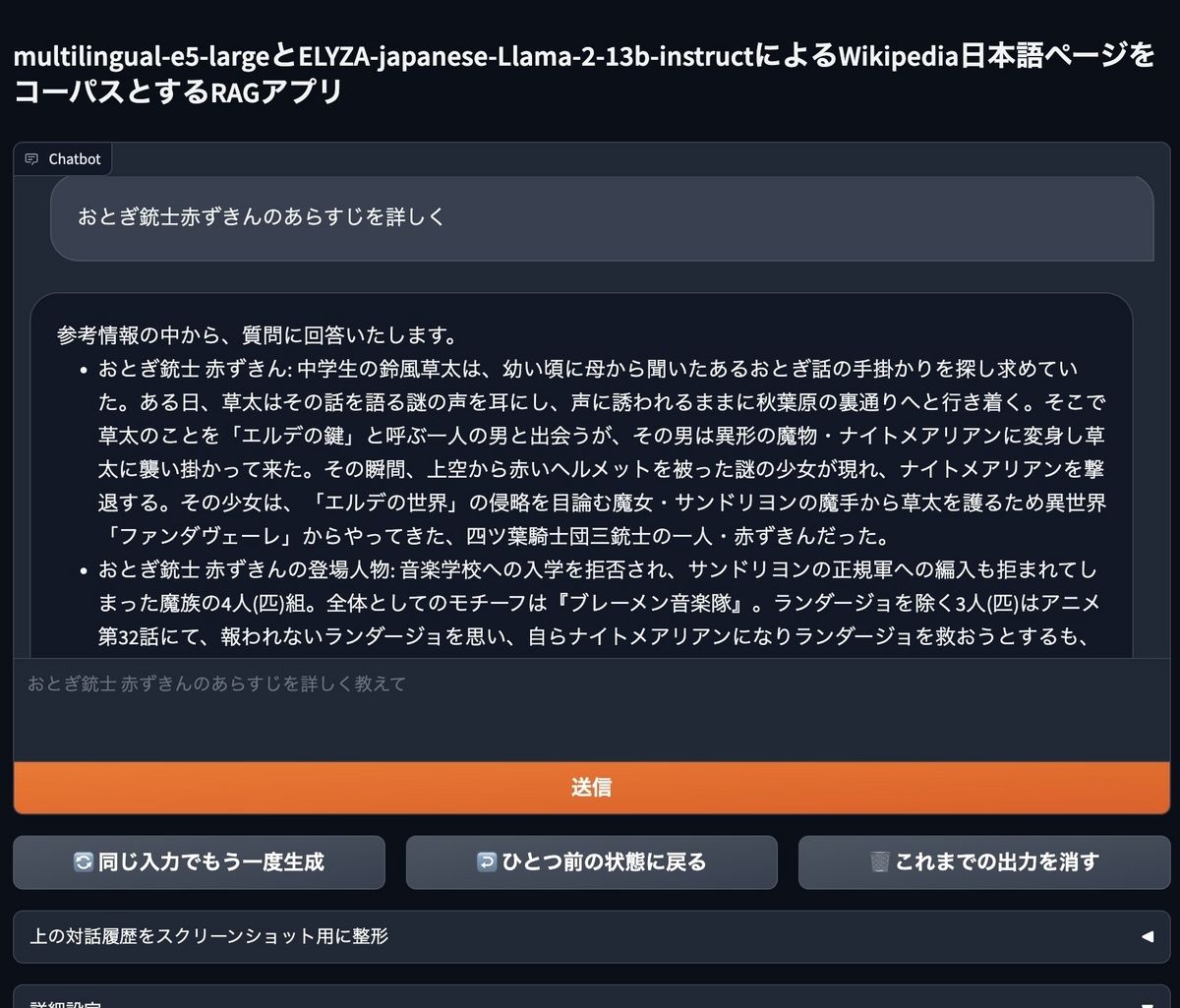
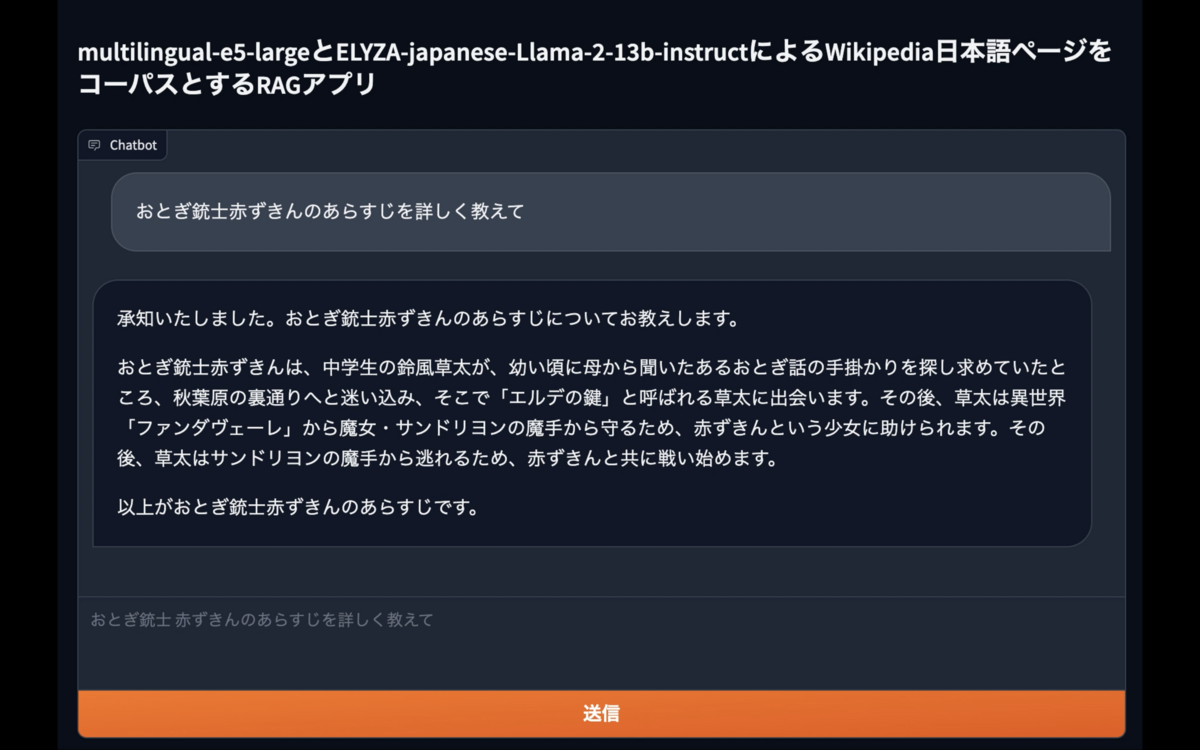
本記事ではWikipediaの日本語記事を元に、ユーザの質問に回答するGradioベースのRAGのサンプルアプリケーションを用意した。コーパスとしてfivehints氏によるsingletongue/wikipedia-utils、hotchpotch氏による同データのembeddings とベクトル検索用の faiss indexを使用している。モデルにはembeddingsにintfloat/multilingual-e5-large、LLMにelyza/ELYZA-japanese-Llama-2-13b-instructを使用する。gradioの実装はelyza/ELYZA-japanese-Llama-2-13b-instruct-demo を参考にした。
コードはGithubで公開している。以降は当該リポジトリのコードを適宜参照しながらRAGアプリケーションの作り方を紹介する。

動作イメージビデオ
環境
torch.cuda.is_available()かつ、VRAM 96GB程度のマシンでの稼働を想定している。
ただし、使用するVRAMの大部分は推論の高速化に使用しているvllmのcache領域であるため、gpu_memory_utilizationを指定することでVRAM 40GB程度まで必要量を削減可能である。(ELYZA-japanese-Llama-2-13b-instructが30GB弱、multilingual-e5-largeが10GB弱)
また、VRAMは必ずしも単一のGPUで供給する必要はなく、vllmではマシンが複数のGPUを利用可能な場合はtensor_parallel_sizeを指定することで分散的に推論できる。
engine_args = AsyncEngineArgs(model=LLM_MODEL_ID, dtype='bfloat16', tensor_parallel_size=4, # GPUの数を指定 disable_log_requests=True, disable_log_stats=True, gpu_memory_utilization=0.6) # VRAM全体の何%を推論に割り当てるかを指定する(ここでは60%)
筆者は以下の環境で動作確認している。
- Amazon EC2 g5.12xlarge (13BモデルのELYZA-japanese-Llama-2-13b-instructを動かす都合で本記事ではg5.12xlargeを使用するが、コストが気になる場合は代わりにelyza/ELYZA-japanese-Llama-2-7bを使用すればg5.2xlargeでも動く)

- Deep Learning OSS Nvidia Driver AMI GPU PyTorch 2.0.1(CUDA等の環境が整っており便利であるため)
使い方
pip install -r requirements.txt python app.py # http://[IP adress]:7860にアクセス
実装上のポイント
faiss_index検索時のtop_k
top_kでベクトル検索にヒットした上位何件を抽出するかを指定する。より多くのチャンクを取得することで、より多くのコンテキストをLLMに与えられる。特に、今回のようにWikipediaのようなデータをコーパスにする場合、1件だけでは役に立つ情報が十分に得られない可能性が高い。例えば、ユーザからの質問が新世紀エヴァンゲリオンに関するものであれば、新世紀エヴァンゲリオンと新世紀エヴァンゲリオンの登場人物の両方を参照した方がより良い回答が得られるかもしれない。他方で、類似度が低いチャンクはLLMを「混乱」させてしまい、結果的に精度が下がるリスクもある。従って、top_kの指定はコーパスとLLMの特性を考慮して慎重に検討する必要がある。
def search(self, question: str, top_k: int, search_text_prefix: str = "query") -> Tuple[List[Tuple[float, dict]], float, float]: emb = self.text_to_emb(question, search_text_prefix) scores, indexes = self.faiss_index.search(emb, top_k) scores = scores[0] indexes = indexes[0] results = [] for idx, score in zip(indexes, scores): idx = int(idx) passage = self.dataset[idx] results.append((score, passage)) return results
intfloat/multilingual-e5-largeでのquery / passageの指定
model cardにも記載がある通り、intfloat/multilingual-e5-largeを使用する場合、用途に応じて"query: " or "passage: "を付与する必要がある。(忘れがち)
Each input text should start with "query: " or "passage: ", even for non-English texts. For tasks other than retrieval, you can simply use the "query: " prefix.
def text_to_emb(self, text: str, prefix: str) -> np.ndarray: return self.emb_model.encode([prefix + text], normalize_embeddings=True)
LLMへのプロンプト
検索結果({contexts})を元に、ユーザの質問({question})に回答させる。加えて「推測や一般的な知識を含めないでください。参考情報に答えが見つからなかった場合は、その旨を述べてください。」と釘を刺すことで、LLMが「想像」で質問に回答しないように指示している。(必ずしも守ってくれるとは限らないが...)
このプロンプトの与え方はベーシックな例で、実際にはユースケースやモデルの特性に応じて様々な最適化の余地がある。
DEFAULT_QA_PROMPT = """ ## Instruction 参考情報を元に、質問に回答してください。 回答は参考情報だけを元に作成し、推測や一般的な知識を含めないでください。参考情報に答えが見つからなかった場合は、その旨を述べてください。 ## 参考情報 {contexts} ## 質問 {question} """.strip()
回答のストリーム
Chat Botを作る上では、LLMの出力をストリームでGUIに表示することが重要である。LLMの推論時間は生成量が増えるほど長くなるため、その分だけユーザを待たせることになる。しかし、「出来た部分から」順番に出力することで、ユーザ視点での待ち時間を減らせるためだ。
stream = await inferenceEngine.run( question=question, max_new_tokens=max_new_tokens, temperature=float(temperature), top_p=float(top_p), top_k=top_k, do_sample=do_sample, repetition_penalty=float(repetition_penalty), stream = True, ) async for response in stream: yield history + [(question, response)]
systemdによるプロセスのデーモン化
サーバ上にアプリケーションをホストする際は、コンソールからpython app.pyを実行するなどのユーザーの介入なしに自動的に開始し、システム起動時に実行され、システムが稼働している間ずっとバックグラウンドで動作させる必要がある。
これを実現する仕組みとしてLinuxにはsystemdがあり、システムのブートプロセスを管理し、後でサービスとアプリケーションを開始、停止、管理するために使用される。
リポジトリにはサンプルアプリケーションをデーモン化する際の簡単なサンプルコードを用意している。
[Unit] Description=Gradio front page. Answer the question based on wikipedia ja page After=network.target [Service] User=[linux-user] Group=[linux-group] WorkingDirectory=[project directory path] ExecStartPre=[path to python env] -m pip install -r requirements.txt ExecStart=[path to python env] app.py TimeoutStartSec=0 Restart=never [Install] WantedBy=multi-user.target
以下のように利用する。
sudo systemctl daemon-reload sudo systemctl enable simple-web.service sudo systemctl start simple-web.service
スケーラビリティ、コスト最適化のアイデア
スケーラビリティの確保
ここまでで基本的なRAG Chat Botの作り方を紹介したが、実運用を鑑みるとスケーラビリティの問題が出てくる。一般的にChat Botのユーザは複数人存在する可能性が高いため、複数の質問が同時に投入されることもあるだろう。その場合、現状の構成ではアプリケーションは1つの推論しか並列で実行できないため、利用が集中する時間帯はユーザが待たされることになる。
対策の一つとして、単一プロセス内のマルチスレッドか、同一ノード(サーバ)内のマルチプロセスで並列的に推論を実施する方向性が考えられる。ただ、どちらにせよ単一のノードが搭載できるGPU/VRAMの数には限界があるため、1つの推論パイプラインを構えるだけで数十GBのVRAMを要するLLMをホストする観点では不安が残る。(クラウドプロバイダーが提供するような、複数のGPUを搭載しているマシンであればある程度までは単一ノード内でスケールできるだろうが)
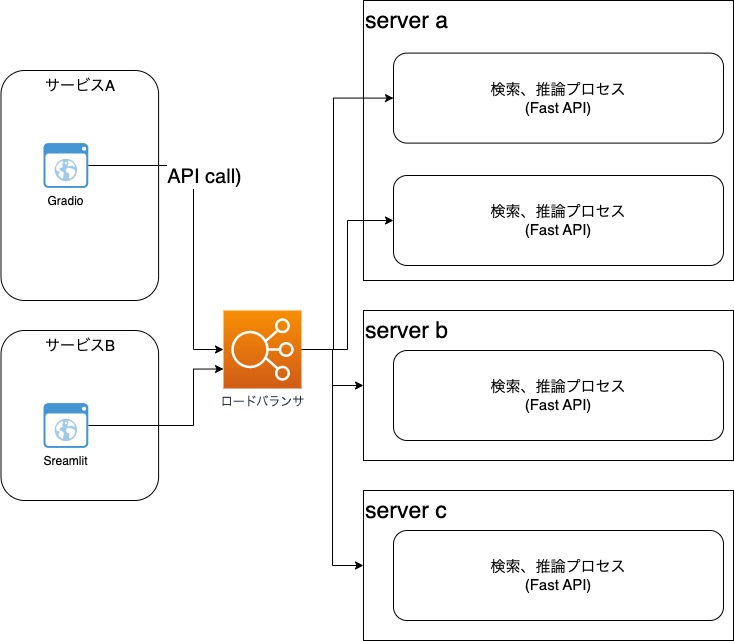
そこで、よりスケーラブルな構成案として、マルチノードに推論を分散する作戦を考えてみよう。そのためには、UI(Gradio)とRAGの検索、推論エンジンを別プロセスに分割することが前提になる。

これによって、n台のノードにAPIをデプロイし、前段にロードバランサを構えてGradioのUIからcallしてスケールアウトする構成が実現できる。RAGの検索、推論はモデル側で状態を維持する必要がないため、UIアプリケーションはRAGのエンジンノード群に繋がるロードバランサのエンドポイントのみを意識して呼び出せば良い点がポイントだ。
また、同じ考え方で同一ノード内に複数のAPIプロセスをホストするマルチプロセスのアプローチも比較的容易に実現できる。(gunicornのworkerの仕組みなどが使えるだろう)

更に発展的な例として、同じモデルを利用する複数のサービスから共通的に推論APIを呼び出す構成も考えられる。つまり、Open AIなどのSaaSプロバイダーが実現しているAPIサービスそのものを自前で実現するというわけだ。今回の例ではRAGの検索とLLMの推論を同一のプロセスで実施しているが、必要に応じて切り離すことも勿論可能だ。
実装上のポイント
API切り出し
これらのアイデアを実現するには、アプリケーションの実装としてUIから検索、推論エンジンを疎結合に呼び出せるように切り出す必要がある。
セルフホストなLLMをAPI化するソフトウェアは既に複数存在している。ものによってはOpen AI互換なAPIを提供するものもあるため、これらを使用すればOpen AIを前提とした既存アプリケーションでも簡単にバックエンドをセルフホストに差し替えることができる。
しかし、本記事のサンプルアプリケーションでは、プレーンな実装を示すため、敢えてFast APIを用いて検索と推論部分をAPIに切り出した「API Mode」を用意した。
pip install -r requirements.txt python app.py --api_mode gunicorn -w 1 -k uvicorn.workers.UvicornWorker rag_inf_api:app # 適宜別ノードから起動
FastAPIとは、PythonベースのWeb APIフレームワークで、以下のようなシンプルな実装でAPIエンドポイントを構えることができる。
@app.post("/question") async def instruct(body: QuestionRequest): async def generate(): async for item in await inferenceEngine.run( question=body.question, max_new_tokens=body.max_new_tokens, temperature=body.temperature, top_p=body.top_p, top_k=body.top_k, do_sample=body.do_sample, repetition_penalty=body.repetition_penalty, stream=True, ): yield item
Streamによるデータのやり取り
先述の通り、LLMを用いたChatアプリケーションでユーザ体験を向上するには、推論中にユーザを待たせないことが重要になる。これはGUIと推論部分を別プロセスに切り離した場合でも同じであるため、APIは推論内容を非同期的にGUIへ配信する必要がある。
そこで、inferenceEngine.run()を非同期的に呼び出す非同期ジェネレータ関数async def generate()を実装し、返されたStream(async for)を順次StreamingResponse(generate(), media_type="text/event-stream")へ渡すことによって非同期的な配信を実現している。
@app.post("/question") async def instruct(body: QuestionRequest): async def generate(): async for item in await inferenceEngine.run( question=body.question, max_new_tokens=body.max_new_tokens, temperature=body.temperature, top_p=body.top_p, top_k=body.top_k, do_sample=body.do_sample, repetition_penalty=body.repetition_penalty, stream=True, ): yield item return StreamingResponse(generate(), media_type="text/event-stream")
クライアント(UI)サイドでは、httpx.AsyncClient()によってレスポンスを順次受け取り、Gradioに表示させている。
async with httpx.AsyncClient() as client: try: async with client.stream('POST', API_URL, json=data) as response: if response.status_code != 200: raise Exception(f"Error: Server responded with status code {response.status_code}") async for line in response.aiter_text(): if line: new_response = line.strip() yield new_response except httpx.HTTPError as e: raise Exception(f"HTTP request failed: {str(e)}")
コスト効率の改善
以上のアイデアによってスケーラビリティの問題は解決の目処が立ったが、高額なVRAMを積んだマシンを向上的に多数稼働させることは経済的な負担が大きい可能性が高いため、コスト最適化が重要なテーマとなる。
モデルサイズの最適化
最初にモデルサイズの最適化余地を検討したい。先述の通り、LLMは量子化することによって必要なVRAMを削減するとともに、推論を高速化できる。モデルが小さくなればより廉価なマシンで稼働させることができる。また、推論が高速になるということは、スループットが向上するということなので、結果的に単位時間あたりに必要なマシンリソースの削減にも繋がる。
また、ユースケースに合ったモデルの選択も意識したい。モデルの選択肢は日々増えており、ユースケースに応じて機能面、非機能面で最適な選択肢は異なる可能性がある。従って、「一つに決める」のではなく、適材適所でベストなモデルを目利きして採用することが重要だ。
クラウドのAutoScalingによる動的スケール
次に考慮したいこととして、先程マルチノードに分散するアイデアを紹介したが、稼働させるマシンの数にも最適化を施したい。大抵のChat Botはユーザアクセスが集中する時間帯と、全く使われない時間帯に波があるはずで、クラウドの場合常に決まった数のマシンを稼働させ続けることは無駄が大きい。
そのような悩みを緩和する道具として、GCP, Azure, AWSなどのクラウドプロバイダーは、アプリケーションを構成するマシンの数を動的に増減させる「AutoScaling」機能を提供している。
これらの仕組みを用いることで、マシンリソースの使用量やリクエスト数などに応じてマシンの数を増減させ、需要に応じたリソース確保を実現できる。

これはコスト効率の改善につながるし、ユーザの増加に従ってマシンリソースを増強できるため、スケーラビリティの向上にもつなげることができる。もちろん、スケールの上限も設定できるので、想定以上のマシンリソースが確保されてしまうような事態も回避できる。なお、Auto Scalingを本格的に設計に組み込む場合、インスタンスを減少させる際のリクエストルーティングの停止(draining)や、新規インスタンスへのアプリケーションのデプロイ方法などを検討する必要がある。
SPOTマシンの活用
LLMをはじめとするMLモデルの興味深い特徴として、モデルは状態を持たず、個々の推論は互いに依存せず実施可能である。だからこそ、先に上げたような分散が容易にできるわけだが、この特徴はクラウドプロバイダーが提供するSPOTマシンの仕組みとも実は相性が良い。
SPOTマシンとは、クラウドプロバイダーが保有する膨大なマシン群のうち、一時的に使用されていない「余り物」を貸し出す仕組みだ。SPOTマシンは「余り物」であるが故に、通常のマシンに比べて遥かに廉価に利用でき、90%引きで使えることすらある。(価格は受給に応じて変動することが多い)
今回検証に利用したAWSのg5.16xlargeに関して言えば、過去1週間のSPOT料金は通常料金である$5.9404 / hourに対して$0.6524 / hourで、89.02%割引されていた。

もちろんSPOTマシンには欠点もあり、代表的なポイントとして以下の2つが挙げられる。
- クラウドプロバイダの「余り物」がない時はお目当てのマシンが利用できないこともある
- SPOTマシンを利用中に、当該マシンがクラウドプロバイダにとって必要になった際は「取り上げられる」可能性がある = 突然シャットダウンされることがある(厳密にはシャットダウンの数分前に警告通知が届く)
ただ、前者に関しては使用するマシンに複数のインスタンスタイプを織り交ぜ、どうしてもSPOTが確保できない場合はオンデマンドなマシンを立ち上げる作りにするなどの対策によって緩和できる。(大抵のクラウドプロバイダはそれらを抽象化した仕組みも含めて提供している)
後者は、恒常的に状態を保つ必要があるアプリケーションの場合難しい制約になるが、ここで冒頭で述べたLLM/MLモデルの特徴が活きてくる。LLMの個々の推論は状態を保たないので、突然マシンがシャットダウンされたとしても、アプリケーション全体に及ぼす影響は少ない。SPOTマシンのシャットダウン時には数分前に通知(イベント)が届くので、それをトリガーとして適切にロードバランサのルーティング先から切り離してやればよいのだ。

おわりに
本記事では、セルフホストなRAGアプリケーションを構築する意義と基本的なアプローチ、設計面での最適化についていくつかのアイデアを紹介した。
しかし実のところ、より良い設計、つまり性能、信頼性、コスト、セキュリティ、運用性に優れた設計を実現する観点ではまだまだ語り尽くせていない論点が多々ある。これを読んだ読者の皆さんも、記事を通じて色々なアイデアが思いついているのではないかと想像しており、仮にそうなっていれば本記事での私の主要な目標は達成されたことになる。
というのも、私の中での本記事の狙いの一つは、MLモデルをシステム設計に組み込む上で、他の多くのシステムの場合と何ら変わらないアーキテクティングのテクニックが役立つという「当たり前のこと」に気づいて頂くきっかけになるような、皆さんの想像力を刺激するものを書くことだったからだ。
私の感覚では、LLMをはじめとする生成AIを適切に選定し、構成し、導入し、運用するプロセスに関する議論がまだ発展途上であるように感じている。その背景には、ソフトウェアエンジニア/アーキテクトとデータサイエンティスト/MLエンジニアとの間に断絶があるのではないかと想像している。MLの専門家はモデルの構築や調整が得意であるが、それらのモデルを安定的にホストしたり、End to Endなサービスに組み込む作業については土地勘がない場合も多い。一方でサービスの開発者からすると、MLは良くわからないので近寄りがたい。結果として、MLの専門家がJupyter上で実現した「魔法」がエンドユーザーに届きづらい状況が起きているように思う。そういった断絶を越えるためにも、サービス開発者がMLモデルを程よい距離感で扱えるようになり、歩み寄っていく必要があるはずだ。本記事がそんなムーブメントの一つのきっかけになればと願っている。