OpenSearchCon Europe 2025のセッション「Unifying Diverse Logs in Big Data Systems for Seamless Analysis and Action with OpenSearch and LLMs」を日本語でまとめます。 可能な限り正確に内容を拾えるようにリスニングに努めたつもりですが、もし誤りがあればご指摘ください。
OpenSearchCon とは?
イベントページ
各セッションはYouTubeで視聴可能
Concurrency and Merge Policies to the Rescue
セッションリンクは以下.
スピーカー
- Satej Sahu
- Zalando SE

セッションまとめ
本セッションでは、Apache Sparkのジョブのデバッグ作業を、大規模言語モデル(LLM)とOpenSearchを活用して自動化するアプローチが紹介された。
データエンジニアリングにおける課題


従来のデータベースがインデックスを使用して特定のアルゴリズムに従ってクエリを実行するように、ビッグデータの世界では分散システム上でジョブが実行される。S3などのオブジェクトストレージに保存された大量のデータに対して並列実行を行う際、Sparkはジョブを作成し、それをステージに分割、さらに各ステージをタスクに分解する。例えば、4コアのCPUシステムでは4つのタスクが同時に実行され、このような分散管理とオーケストレーションがSparkの中核となっている。
単一マシンでは簡単な処理でも、数十億レコードになると単一CPUでは処理できない。Sparkはこのクエリを複数のステージに分割し、各ステージをさらにタスクに分解する。各タスクは必要なデータがすべて揃っているかを確認してから実行され、完了後はステージがすべてのタスクの結果を集約して次のステージに進む仕組みとなっている。
Apache Sparkを使用したビッグデータ処理では、分散システム上で並列実行されるジョブの管理が複雑になる。Sparkは大量のデータを処理するため、ジョブをステージに分割し、さらに各ステージを複数のタスクに分解して、CPUの各コアで並列実行する。例えば、4コアのCPUであれば4つのタスクが同時に実行される仕組みである。
このような分散処理において問題が発生した場合、データエンジニアはSpark UIを通じて原因を特定する必要がある。Spark UIには膨大な情報が表示され、メモリスピル、データスキュー、ホットデータなど、様々な問題の可能性を一つ一つ調査しなければならない。発表者の経験では、問題の特定だけで3〜5時間かかることも珍しくない。
特に課題となるのは、経験の浅いエンジニアにとってこれらの概念を理解し、適切に問題を特定することが困難な点である。スピルやスキューといった専門用語の意味を理解し、それらがパフォーマンスに与える影響を正確に把握するには、相当な経験と知識が必要となる。
既存のAI Assistantの限界

例えばDatabricksはAI Assistantを提供しており、Apache Sparkに関する質問に回答できる。しかし、このアシスタントには重要な制限がある。実行中のジョブの具体的なコンテキストを理解できず、ドキュメントベースの一般的な回答しか提供できないのである。
例えば、5時間実行されているジョブがなぜ遅いのかという質問に対して、AI Assistantは一般的な最適化の方法は教えてくれるが、その特定のジョブの何が問題なのかは特定できない。結果として、データエンジニアは依然として手動でSpark UIを分析し、イベントタイムラインやステージ情報、タスクの実行状況などを一つ一つ確認する必要がある。
LLMを活用した自動化ソリューション
イベントログの構造と特性

Spark UIが表示するすべての情報は、JSON形式の単一のイベントログファイルから生成されている。このログファイルには、各行が1つのJSONオブジェクトとして、ジョブ、ステージ、タスクの実行情報が時系列で記録されている。メモリ使用量、実行時間、シャッフルデータ量などの詳細な情報も含まれており、これらは構造化されたテキストデータとしてLLMが理解・分析するのに適した形式となっている。
そこで、LLMを活用してこのイベントログを自動的に分析し、問題を特定するシステムの開発に着手した。基本的なアイデアは、ベストプラクティスに則った分析手順(イベントタイムラインの確認、最も時間のかかるステージの特定、スピルやスキューの検出など)をLLMのプロンプトに組み込み、イベントログを入力として与えることである。
第1段階:基本的なRAGアプローチ



最初の実装では、イベントログをS3に保存するよう設定し、それをマウントして特定の場所にログが生成されるようにした。Lambdaを使用してこれらのログをOpenSearchに自動的にインジェストし、Databricksのドキュメントが推奨する5つのステップをプロンプトに組み込んでLLMに分析させた。
初期のプロンプトには、具体的なログの例と、それをどのように解析すべきかの短い例も含めた。しかし、この基本的なアプローチでは出力が十分に詳細ではなく、具体的な数値や計算が不足していることが判明した。
第2段階:グラフデータベースの活用

Chain of Thoughtアプローチを導入して改善を図ったが、さらなる精度向上のため、ジョブ、ステージ、タスクの関係性に着目した。これらの関係をグラフデータベース(Neo4j)に保存し、Cypherクエリ言語を使用して効率的に情報を取得できるようにした。
この関係モデルとコンテキスト検索を組み合わせることで、まず関連するステージを取得し、そこからすべての情報を解析してOpenSearchのベクトルストアと連携させる。これにより、LLMはより深いレベルで段階的に問題を分析できるようになった。
第3段階:ソリューションドキュメントの統合
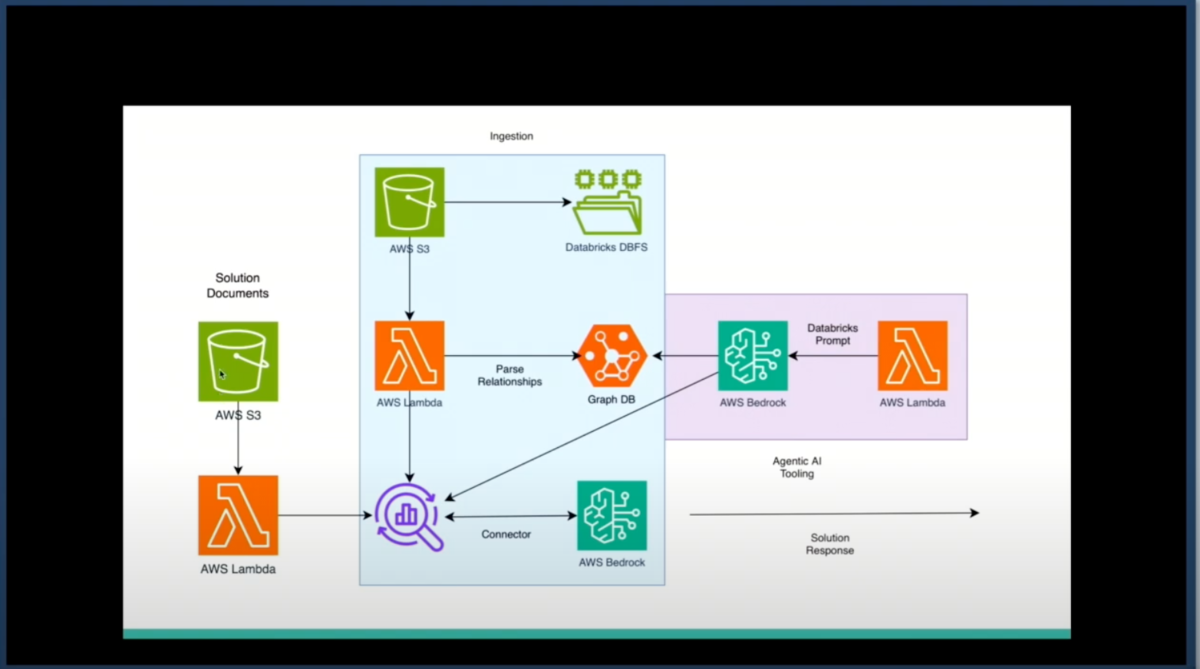
問題の特定だけでなく、解決策の提案も重要である。DatabricksやApache Sparkのドキュメントには、各問題に対する解決方法、アプローチ、設定変更の詳細が記載されている。これらのソリューションドキュメントも別のパイプラインでOpenSearchに保存し、問題が特定された後に適切な解決策を検索できるようにした。
人間のエンジニアは、自分の設定、使用しているクラスター、更新可能な項目などの膨大なコンテキスト情報を記憶する必要があるが、LLMとOpenSearchの組み合わせにより、この負担を大幅に軽減できる。
第4段階:エージェンティックツールの統合
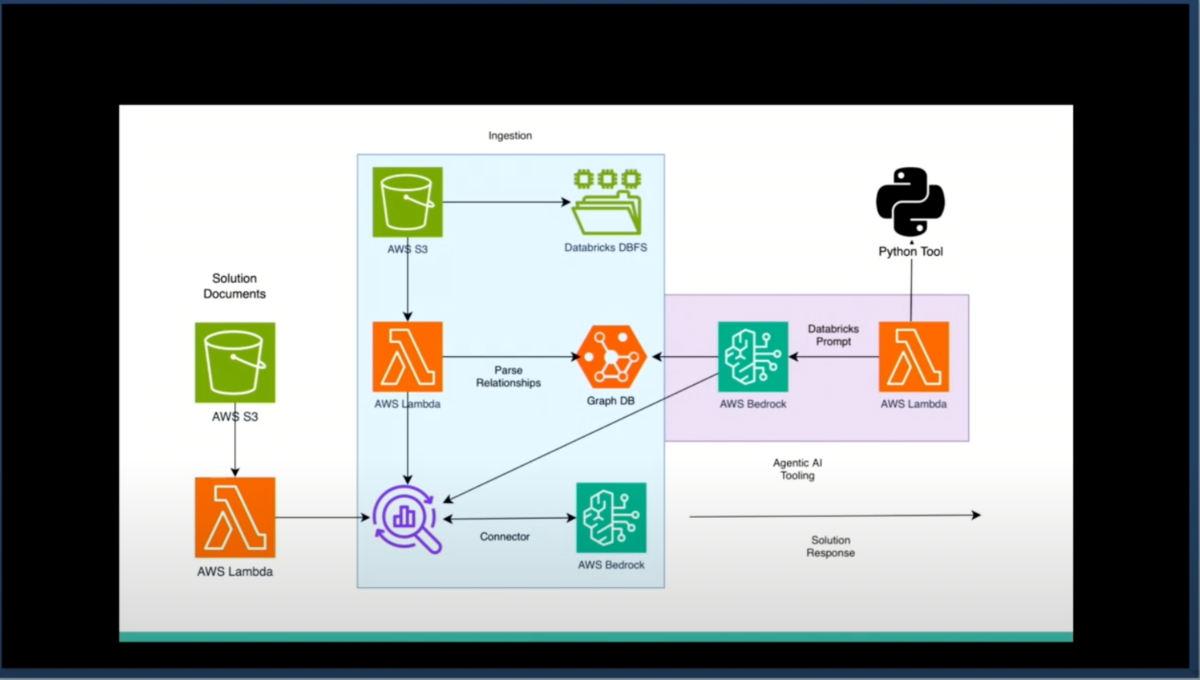
適切なパーティション値の計算など、具体的な数値計算が必要な場合のために、Pythonインターフェースを統合した。例えば、総シャッフルデータ量が6.4GBで、Databricks推奨の128MBのターゲットパーティションサイズを使用する場合、50パーティションが必要という計算を自動的に実行し、並列性を考慮して最終的に80パーティションを推奨するといった具体的な提案が可能になった。

さらに野心的な試みとして、Databricksの実行環境自体をツールレイヤーとして追加することも検討した。LLMが提案した解決策を自動的に実行し、並列で複数の解決策を試すことができる。ただし、Databricksの実行コストが高いため、本番データから合成データを生成し、小規模データでの実行結果から本番環境での効果を予測するアプローチを採用した。

単一のエージェントがすべてを処理する代わりに、問題セットをそれぞれ専門の小さなエージェントが並列で処理するアーキテクチャを実装した。親エージェントが全体を統括し、3つのレベルのエージェント(ステージレベル、ジョブレベル、タスクレベル)が協調して動作する。いずれかのエージェントが解決策を見つけた時点で処理を終了し、親エージェントに結果を返す効率的な設計となっている。
実装の成果





全体的なプロセスは、まずSpark UIのチェックリストをロードし、最も時間のかかっているステージをクエリすることから始まる。次にスキュー、スピル、またはI/Oバウンドの問題を検出し、関連するドキュメント情報を取得して問題の説明を行う。そして修正案(remediation)を提案し、最後に将来の再利用のためのサマリーを提供するという流れになっている。
このシステムは非常に具体的な分析結果を提供する。例えば、6.4GBのシャッフルデータと現在のワーカー設定情報から、128MBのターゲットサイズに基づいて必要なパーティション数を計算し、spark.sql.shuffle.partitions=80という具体的な設定変更を推奨する。この計算過程では、Pythonツールを呼び出して正確な数値を算出している。

この実験から得られた結果は非常に印象的なものだった。第一に、実際の問題を迅速に発見できるようになる。問題発見とデバッグにかかる時間は5〜8時間から5〜15分に短縮された。これは、データエンジニアが解決策を見つけることを妨げる最大の障壁を取り除くものである。なぜなら、彼らは何が正確な問題なのかを知らないことが多いからだ。より経験豊富なエンジニアが必要とされていた作業を、システムが代替できるようになった。
発表者は、これをデータやAIの民主化を超えた「運用効率の民主化」と表現した。LLMとツーリングのエコシステムを通じて、専門知識のギャップを埋めることができる。問題の特定という最も困難で時間のかかる部分を自動化することで、エンジニアはより創造的で価値の高い作業に集中できるようになった。
QA
Q: LLMはパーティション数の指定以外にどのような最適化の提案をしてくれるのですか?
A: 現在のプロンプトはDatabricksのドキュメントに記載されている内容に限定されています。LLMはまずイベントタイムラインを確認し、長時間実行されているプロセスがあるかを確認します。問題がなければステージレベルに深く入り、どこで最も時間を費やしているかを特定します。
今後の改善としては、データ自体に関するコンテキスト情報を追加することが考えられます。現在はイベントログのみを理解していますが、実際のデータやユーザーが実行しようとしているプロセスの情報を含めることで、より具体的な解決策を提供できる可能性があります。
Q: アーキテクチャ図にOpenSearchがありましたが、何を保存していて、どのようにワークフローで使用されているのですか?
A: OpenSearchには2種類の情報を保存しています。
第一に、イベントログです。Spark UIが表示するすべての情報(アプリケーション情報、ジョブ、ステージ、タスクの成功/失敗、実行時間など)は、すべてこのイベントログから生成されています。データエンジニアは通常、この膨大な情報を手動で確認する必要があります。私たちはこのログ情報をOpenSearchに収集し、RAGフローで使用できるようにしています。
保存時には、グラフデータベースからの関係データもメタデータとして含めています。これにより、特定のジョブに関連するコンテキスト情報を検索する際に、より効果的な相関付けが可能になります。
第二に、ソリューションドキュメントです。イベントログは問題に関する情報のみを含み、解決策は含まれていません。そのため、問題が特定された後に適切な解決策を見つけるために、Databricksのドキュメントから抽出したソリューション情報も別途OpenSearchに保存しています。
Q: このソリューションはDatabricks専用ですか?他のビッグデータシステムにも適用できますか?
A: このアプローチは任意の構造化されたシステムに適用可能です。すでにSOP(標準作業手順)があれば、それをプロンプトとして使用し、ログを保存して、同様のエージェンティックアプローチを実装できます。
例えば、Apache Druidのような他のオープンソースエンジンも、Apache Sparkと非常に似た動作をします。パーティショニングやビッグデータ処理などの共通概念は同じですが、各エンジンの内部動作には固有の特徴があります。これらのコンテキストの違いは重要ですが、比較的簡単に切り替えることができます。