OpenSearchCon Europe 2025のセッション「Dive Deep on OpenSearch’s Vector Search」を日本語でまとめます。 可能な限り正確に内容を拾えるようにリスニングに努めたつもりですが、もし誤りがあればご指摘ください。
- OpenSearchCon とは?
- Dive Deep on OpenSearch’s Vector Search
- スピーカー
- セッションまとめ
OpenSearchCon とは?
イベントページ
各セッションはYouTubeで視聴可能
Dive Deep on OpenSearch’s Vector Search
セッションリンクは以下
スピーカー
- John Handler
- AWSのソリューションアーキテクト
- OpenSearchのベクトル検索機能について解説
- Yuye Zhu
- AWSのOpenSearchを中心とする機械学習エンジニア
- ベクトル検索やエージェントフレームワークなどの機械学習機能を主に担当
セッションまとめ
従来の検索からベクトル検索への進化

過去20〜25年間、私たちは特定の検索パターンに慣れ親しんできた。検索エンジンにキーワードを入力し、結果を確認して、期待した結果が得られなければ「どう言い換えるか」「どんな単語を使うか」を考えて再検索する、というプロセスである。この方法では、ユーザー自身が検索の意味や文脈を調整する責任を負っていた。

この従来の検索方式の限界を示す例として、「hot weather hats」(暑い天候用の帽子)を検索すると、実際には「体を暖かく保つ帽子」が結果として返されることがある。しかし、ユーザーが本当に求めているのは「太陽の下で着用し、涼しさを保つ帽子」である可能性が高い。
この問題を解決するのが、埋め込み技術である。これにより、単語の表面的な一致ではなく、意味的な類似性に基づいた検索が可能になった。
新しい検索パラダイム

埋め込み技術と大規模言語モデルの発展により、検索分野に4つの新しいアプローチが生まれた。
- セマンティック検索 : 単語の周辺コンテキストと単語自体を組み合わせてベクトル表現を作成し、単語の真の意味を捉える手法。表面的な単語の一致を超えて、意味的な関連性を理解できる。
- マルチモーダル検索: テキストと画像など、複数の情報タイプを組み合わせた検索。例えば、赤いスニーカーを探す際に、テキスト説明と画像の両方を検索条件として使用できる。
- スパース検索: 語彙的要素(単語の直接的マッチング)と意味的要素(文脈理解)を両方取り入れた手法。トークン化により単語を処理し、重み付けによって重要度を調整する。
- 会話型検索: 従来の単発クエリから脱却し、複数の質問にわたって会話の文脈を維持する手法。一度の検索で終わらず、継続的な対話を通じて精度の高い結果を提供する。
各種検索手法の詳細
語彙検索(Lexical Search)

語彙検索は、私たちが最も慣れ親しんだ従来の検索方式である。「gaming headset with microphone」のような検索において、製品のタイトルや説明文内の単語を直接マッチングして結果を返す。

語彙検索の基本原理は、データベース内のアイテムの中から、ユーザーの検索クエリと類似性の高いものを見つけることである。この時、「類似している」かどうかの判断基準が検索結果の品質を左右する。
語彙検索において、類似性の判断は単語レベルで行われる。単語は「soul」「sun」のような具体的なものから、「love」のような抽象的で定義が難しいものまで幅広く存在するが、いずれも意味を伝える基本単位として機能する。
ユーザーが検索クエリを入力する際、その意図は使用する単語によって表現される。語彙検索では「単語が一致すれば意味も一致する」という前提に基づいて動作するため、より多くの単語が一致し、特に珍しい(希少な)単語が一致するほど、より関連性の高い検索結果として評価される。
ベクトル検索(Vector Search)

ベクトル検索では、すべてのコンテンツを埋め込みモデルに入力してベクトル埋め込みを生成する。このベクトル埋め込みは、語彙検索と同様に単語の意味を捉えるが、学習ベースでより文脈に敏感な方法で処理される。単一単語の制約を超えて、ベクトル空間での意味理解が可能になる。
検索時には、ユーザーのクエリも同じプロセスでベクトル埋め込みに変換され、同じ意味空間に配置される。その後、ベクトル間の距離計算により、意味的に類似したコンテンツを特定する。

1536次元ベクトルのイメージ。この数値配列がテキストの意味をエンコードし、ベクトル空間での類似性計算を可能にする。
約20,000のデータポイントを含むベクトル空間の視覚化では、意味的に類似したアイテムが近くにクラスタリングされている様子が確認できる。


検索クエリをこの空間に投影し、距離の近さ(近接性)に基づいて類似性を判断する。例えば、左下にクラスタリングされたオブジェクト群は互いに類似しており、右上の離れた位置にあるオブジェクトは類似性が低いと判断される。
スパース検索(Sparse Search)

スパース検索では、まず全単語セットをトークナイザーで約32,000トークンに削減する。その後、トランスフォーマーモデルを使用して、各トークンに重みを付与する。
具体例として、「Apple products are expensive」という文では、apple、expensive、chip、storeなどのトークンに高い重みが付けられ、関連性の低いトークンには低い重みが設定される。一方、「An apple a day keeps a doctor away」では、apples、doctors、medical、prevent、fruit、dietに高い重みが付与される。
これは2段階のプロセスで構成される:
1. トークン化によりベクトル数を削減.
2. トランスフォーマーによる重み付け.
重みの大部分はゼロとなり、密なベクトルとは異なる疎な構造を持つ。

類似性計算では、クエリも同様にベクトル化される。例えば「Apple gift something phone electronics something phones」は、トークナイザーが生成した疑似トークンとして処理され、ドット積を使用して距離が計算される。
スパースベクトルは語彙的特徴とDense Vector的特徴の両方を併せ持ち、効率的で高速なマッチングを実現する。また、検索処理にハイブリッドな特性をもたらす。

OpenSearchプロジェクトでは、AWSがいくつかのスパースモデルをオープンソース化している。これらのモデルは2つのモードで動作可能である:
ドキュメントのみをエンコードする場合、ドキュメントをベクトル化した後、クエリ処理時にトークナイザーを使用してマッチングを行う。
会話型検索(Conversational Search)

会話型検索では、ユーザーからの質問に対して関連コンテキストを取得し、生成AIモデルに送信するプロンプトに含める。AIモデルは検索結果と会話履歴の両方を考慮して応答を生成する。
この仕組みにより、従来の単発クエリの制約から解放される。実用例として、「ビーチ用の靴が欲しい」と検索して女性用の靴ばかりが表示された場合、続けて「私は男性です」と入力するだけで、会話の文脈を理解して男性用の靴を表示できる。
OpenSearchでの技術実装
Neural Plugin
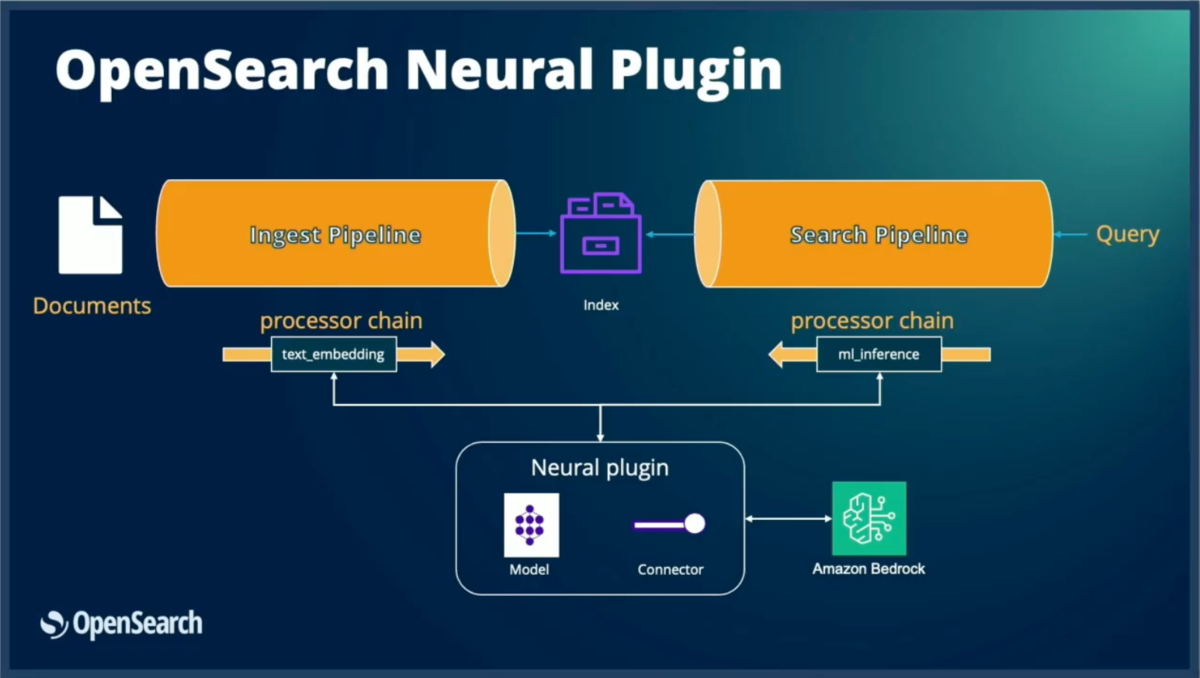
Neural Pluginは、OpenSearchと各種機械学習モデルを接続する中核コンポーネントである。モデルは外部サービスでのリモートホスティング、またはOpenSearchクラスター内のMLノードでのローカルホスティングが可能だが、いずれの場合もNeural Pluginを通じてモデルにアクセスする。
データ取り込み処理
ドキュメントが入力されると、事前定義された取り込みパイプラインが作動する。このパイプラインはモデルIDを通じて特定のモデルを参照し、処理を自動化する。また、フィールドマッピング(ソーステキストフィールド→目的ベクトルフィールド)を設定することで、Neural PluginがMLモデルを呼び出し、生成された埋め込みをドキュメントに配置する。
外部モデル連携
外部サービスのモデルを使用する場合、コネクターフレームワークが提供される。このフレームワークにより、認証情報、呼び出し方式、後処理方法などを含む外部モデルとの接続設定を定義できる。
検索処理
検索時には、OpenSearchが複数のプロセッサを使用して以下の処理を実行する:
- 埋め込み生成の呼び出し
- リランカーの呼び出し
- 埋め込みの取り込みとマッチング処理
ハイブリッドクエリもこの処理に含まれるため、どの検索手法を使用する場合でも、OpenSearchの両端(取り込みと検索)でパイプライン、コネクター、モデルIDによるモデル参照が必要となる。
取り込み・検索処理の詳細
取り込み側のアーキテクチャ
生データ(ドキュメントや画像)が入力されると、取り込みパイプラインが以下のプロセッサを使用して処理する:
- テキスト埋め込みプロセッサ:テキストの埋め込みを生成し、指定フィールドに配置
- マルチモーダル処理用プロセッサ:画像とテキストを組み合わせたマルチモーダルモデル用
- スパースエンコーディングプロセッサ:スパースモデル専用の処理
これらのプロセッサが埋め込みデータを生成し、OpenSearchインデックスに送信する。
検索側のアーキテクチャ
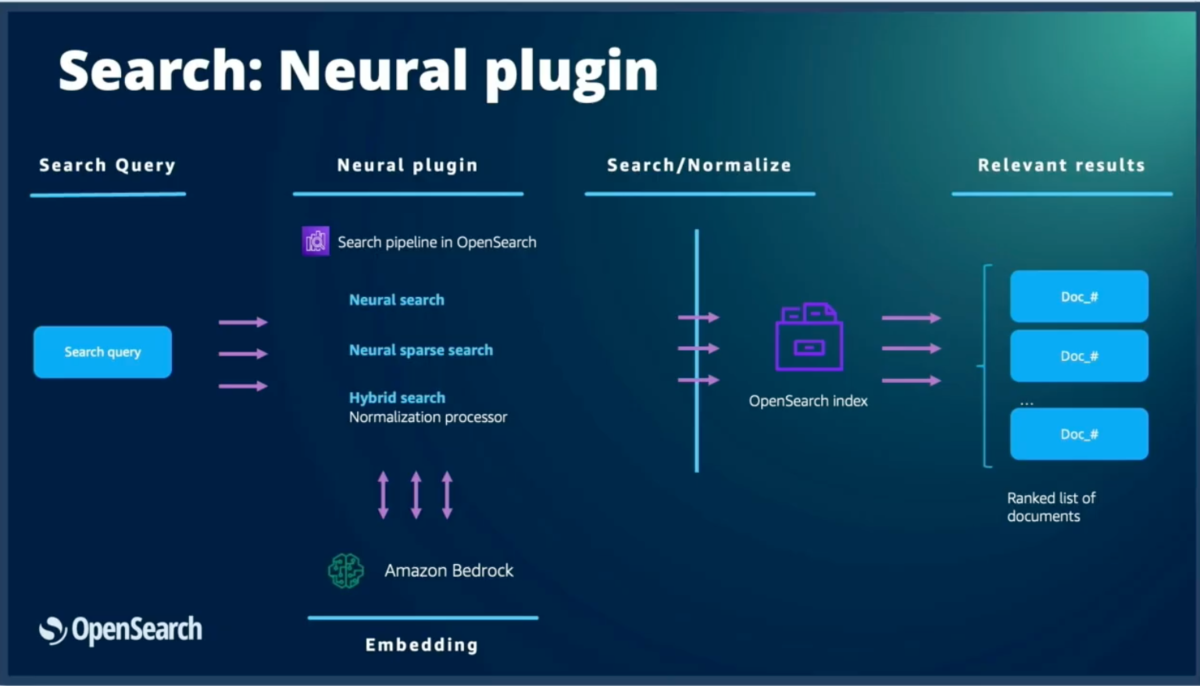
検索時には以下のプロセッサが動作する:
- Neural Search:クエリの埋め込み処理とK-NN(K最近傍)クエリの実行
- Neural Sparseプロセッサ:スパース埋め込みの生成とクエリ処理
- ハイブリッドプロセッサ:語彙検索とベクトル検索の両方を実行
これらの処理の間では、コネクターまたはローカルモデルを通じてMLモデルが呼び出され、必要な埋め込みが生成される。最終的にインデックスに対してクエリが実行され、関連度でランク付けされたドキュメントセットが返される。
共通する実装課題と解決アプローチ
インデックスマッピングの設定例

マルチモーダルな取り込みパイプラインでは、以下の要素を定義する。
画像に関しては、テキスト画像埋め込みプロセッサを使用し、フィールドマッピングに以下のように指定する:
- テキスト説明の埋め込み → 画像説明フィールドに配置
- 画像データ → 画像バイナリフィールドに配置

検索側では、ハイブリッドパイプラインを使用してプロセッサを設定する。例として、語彙検索とベクトル検索を統合する正規化プロセッサを使用し、設定されたパイプラインに対してクエリを実行する。
ハイブリッドクエリでは、複数の異なる検索クエリを組み合わせることができる。ハイブリッド機能は最大5つのクエリ句を受け入れ、すべてがベクトルベースである必要はない。つまり、ハイブリッドは語彙ベースまたはベクトルベースの複数クエリを、RRF(相互ランク融合)やmin-max正規化などの手法でブレンドする仕組みである。

これまで説明してきたように、各検索手法の実装は非常に似通っている。コードでの見た目も、パイプライン作成、コネクター作成、モデル作成、モデルデプロイという流れで、使用する手法に関係なくほぼ同じステップを踏む必要がある。
具体的には、どの検索手法を実装する場合でも以下のステップが共通して必要となる:
- コネクターの作成
- モデルグループの設定(モデルのアクセス制御を提供)
- モデルの登録
- モデルのデプロイ
- パイプラインの作成
- データの取り込み
- 検索パイプラインの作成
- データの検索実行
これらのステップはすべて一種の反復的なコード(repeated code)となっており、エラーが発生しやすい(error-prone)という問題がある。同じような設定を何度も書く必要があり、開発効率の低下やメンテナンス性の悪化を招いていた。
この課題を解決するため、簡素化されたアプローチを開発することになった。
opensearch-ml-quickstartライブラリ
OpenSearchの分散システムアーキテクチャ

解決策を説明する前に、OpenSearchの基本的なアーキテクチャを理解する必要がある。OpenSearchは分散システムとして設計されており、複数の専門ノードで構成される:
コネクターの役割と実装

コネクターを作成する際は、主にMLノードまたはデータノードと連携して、各種外部システムへの接続を確立する。
コネクター実装の具体例では、以下の主要要素が含まれる:
- 認証情報の設定:外部サービスへの安全なアクセスを確保
- アクション定義:モデルが実際に呼び出される処理の詳細
- 接続設定:外部サービスとの通信方法

このコネクターをOpenSearchにデプロイすると、モデルIDが付与される。モデルIDは任意のモデルを参照する汎用的な仕組みで、以下の2つのタイプをサポートする:

Amazon OpenSearch Serviceでは、SageMakerとBedrockでのモデル設定を簡素化する統合機能も提供されている。これらの統合により、スパースとベクトルの両方のモデルタイプを容易に設定できる。

Amazon PQA データセットでのデモ
データセット概要とOpenSearch ML QuickStartライブラリ
ベクトル検索機能をOpenSearchで使用するには、コネクター、モデル、検索プロセッサー、取り込みプロセッサーの設定が必要であり、OpenSearchの初心者には少し複雑に感じられる可能性がある。そのため、ripple OpenSearch ML QuickStartライブラリを構築した。

OpenSearch ML QuickStartリポジトリは、Amazon Product Question and Answering(PQA)データセットで動作する。このデータセットは数百万の製品と数十のカテゴリを含む公開データセットである。
ライブラリの構成
 OpenSearch ML QuickStartリポジトリには、モデルの種類に応じて以下のクラスが用意されている:
OpenSearch ML QuickStartリポジトリには、モデルの種類に応じて以下のクラスが用意されている:
ローカルMLモデルとリモートMLモデル
- ローカルMLモデル:モデルをOpenSearchクラスター内にダウンロードして使用
- リモートMLモデル:BedrockやSageMakerなどの外部サービスでホストされたモデルを使用
MLコネクタークラス.

リモートモデルを使用する際は、以下の2種類のコネクタークラスが提供される:
- OsMkコネクター:オープンソース版OpenSearch用
- AosMlコネクター:Amazon OpenSearch Service用
この2つの違いは認証方式にある。オープンソース版ではアクセスキーとシークレットキーのペアを使用し、Amazon OpenSearch Serviceでは、リソース識別子(ARN)を使用する。ARNはBedrockモデルやSageMakerエンドポイントのリソースを指定する。
会話型検索のサポート
会話型検索機能は、AOS ARMコネクターを通じて大規模言語モデルへのアクセスを提供する。
デモ
デモ1:語彙検索(Lexical Search)

最初のデモでは、「gaming headset with microphone」という検索クエリを使用した。結果として以下の3つのアイテムが返された:
- ゲーミングヘッドセットとヘッドフォンマイク
- ゲーミングヘッドセットマイク、ゲーミングヘッドセットとマイク
- 同様のゲーミングヘッドセット関連製品
語彙検索は、コーパス内で人気のあるキーワードを持つクエリでは良好に機能することが確認された。
次に「earbuds protecting me from noise」という曖昧なクエリを試したところ、予期しない結果が返された:
- コスチューム
- カジュアルウェア
この結果を分析すると、実際の製品には「earbuds」「noise」「protect」というキーワードは含まれておらず、代わりに「me」と「from」という一般的な単語のみが一致していた。これは語彙検索の限界を示しており、意味的な理解が必要であることを示している。
デモ2:Dense Vector Search

Dense Vector Searchのデモでは、SageMakerでホストされた「MS Marco distilled BERT task B」モデルを使用した。
実装の詳細:
- ホストタイプ:AOS(Amazon OpenSearch Service)
- モデルタイプ:SageMaker
- 埋め込みタイプ:Denseベクトル
- インデックス名と取り込みパイプライン名の指定
これらの設定により、AOS SageMaker MLコネクターのインスタンスが作成され、リモートMLモデルのインスタンスが生成される。
AOS SageMaker MLコネクターの内部動作:
- インラインポリシーの設定:SageMakerエンドポイントを呼び出す権限をロールに付与
- リソースの指定:スパースモデルまたはDenseモデルのリソースを設定
- ファイル名の返却:「sagemaker_dense」などのファイル名を生成
- テンプレートの設定:サービス名、リージョン、URLなどを含む
- コネクターの作成:定義されたペイロードでコネクターを生成
同じ「earbuds protecting me from noise」クエリでDense Vector Searchを実行すると:

- クエリタイプ:match queryではなくneural query
- 検索フィールド:テキストフィールドではなく埋め込みフィールド
- モデルID:取り込み時と同じモデルを使用
結果として、以下のような意味的に関連性の高い製品が返された:
- イヤホン/ヘッドフォン(正確なカテゴリ)
- 聴覚保護と有害なノイズに関する製品
- 同様の聴覚保護製品
しかし、「earbuds supporting Bluetooth 5.0」というクエリでは、Dense Vector Searchの課題が明らかになった:

Dense Vector Searchは意味的な理解をある程度捉えることができるが、特定のキーワードが重要な場合には完全に機能しないことがある。
デモ3:スパース検索(Sparse Search)

スパース検索では、SageMakerでホストされた「OpenSearch neural sparse encoding v1」モデルを使用した。

「earbuds supporting Bluetooth 5.0」クエリでの結果:

スパース検索は、このような特定のキーワードを含むクエリで完璧に機能することが示された。
デモ4:ハイブリッド検索(Hybrid Search)

ハイブリッド検索では、スパースモデルとDenseモデルの両方を組み合わせて使用する。これにより、すべての検索手法の利点を活用できる。
「earbuds supporting Bluetooth 5.0」クエリでの実装:

- ハイブリッドクエリには複数のクエリの配列が含まれる
- この例では、スパースクエリとdenseクエリの両方を使用
- denseクエリ:dense embeddingフィールドを検索
- スパースクエリ:スパース特徴の埋め込みフィールドを検索
- クエリテキストは同じだが、モデルIDは異なる
検索パイプラインの設定:
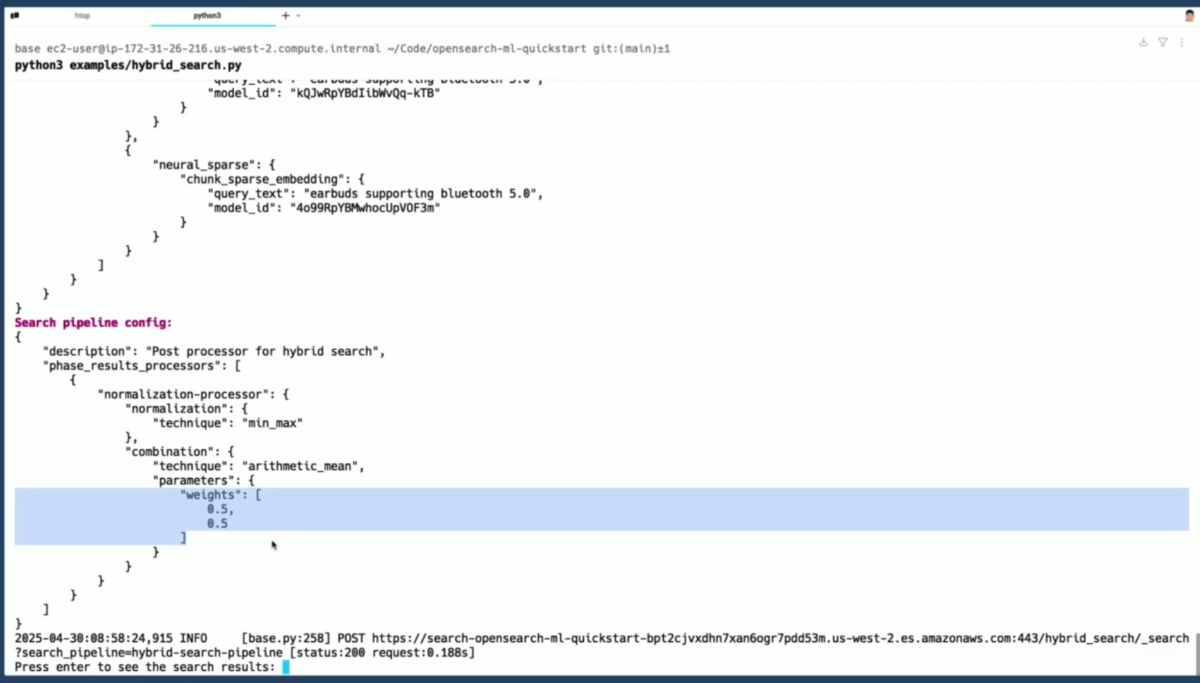
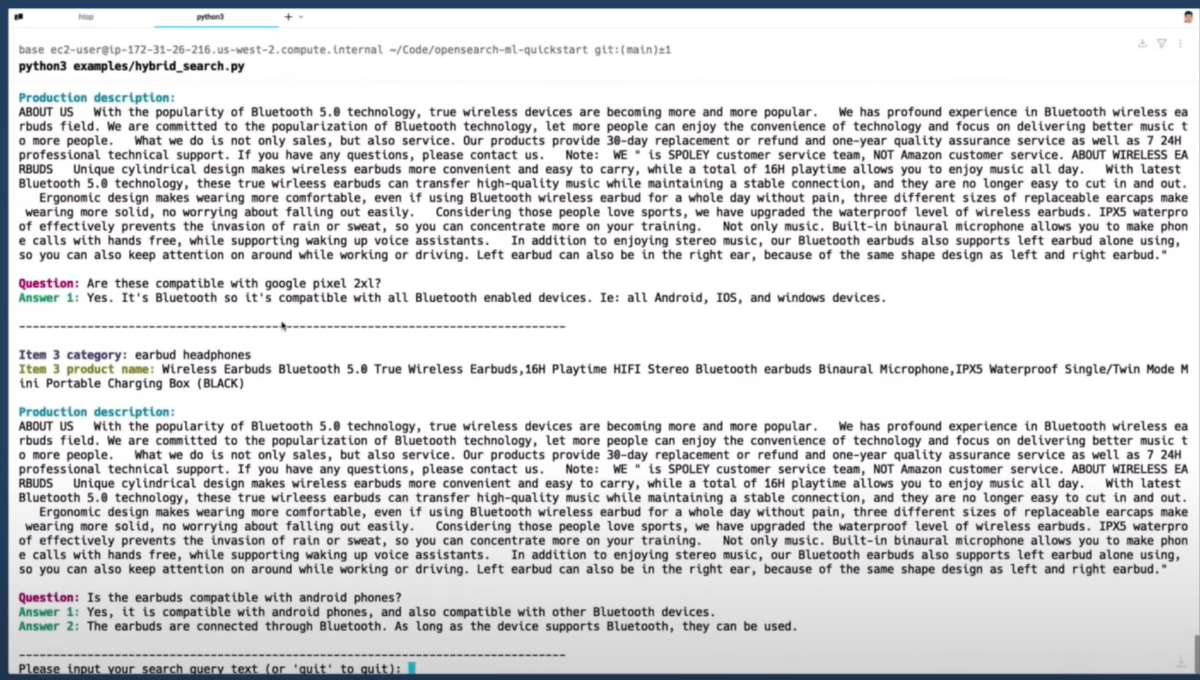
結果として、Dense Vector Searchとスパース検索の両方から最良の結果が組み合わされた。
デモ5:会話型検索(Conversational Search)
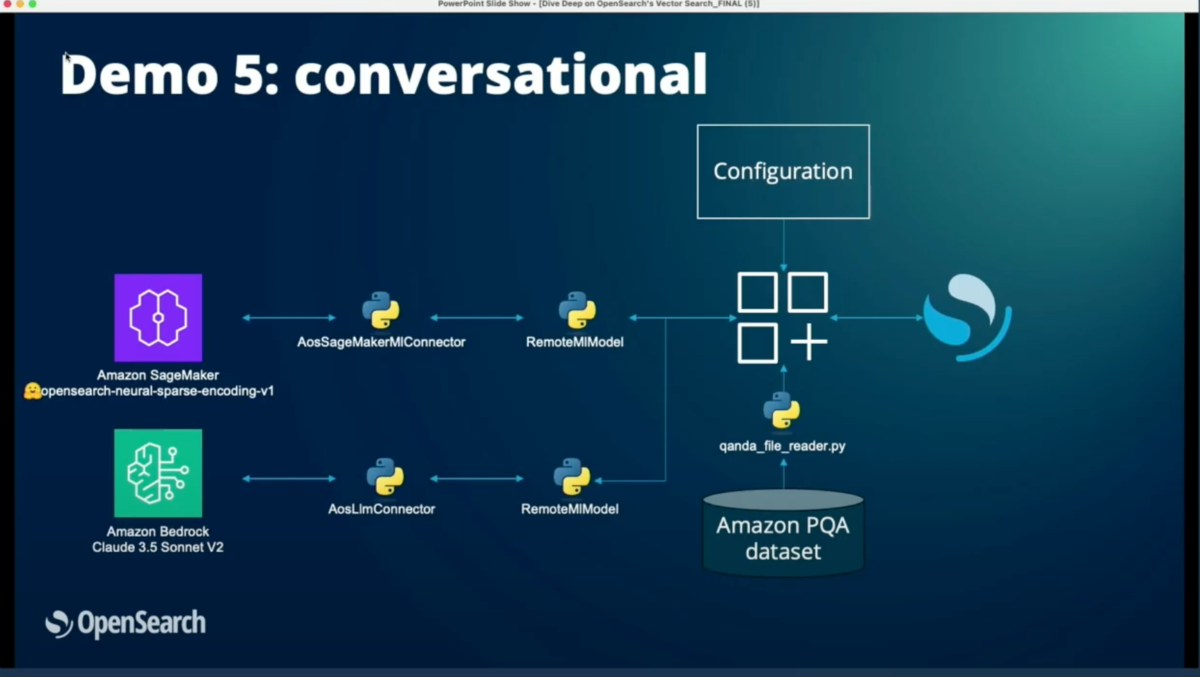
最後のデモでは、単純な検索を超えて、ユーザーの質問に答える機能を示した。これはRAG(Retrieval Augmented Generation)アプローチを使用している。
プロセス:
- SageMakerモデルを使用して関連する結果を取得
- LLMに結果を要約し、ユーザーの質問に答えるよう依頼

デモの質問:「What sheets should I buy if I have a cat?」(猫を飼っている場合、どのシーツを買うべきか?)
検索クエリの構成:
- 第1部分:neural sparseクエリ
- 第2部分:クエリ拡張(Bedrock Claudeモデルを使用)

取得された関連する質問:
- 「このシーツを買いたいが、猫がカバーを破いてしまうか心配」
- 「これらのシーツはペットに対してどの程度耐久性があるか」
- 「ボックススプリングをカバーしたいが、猫を飼っている」
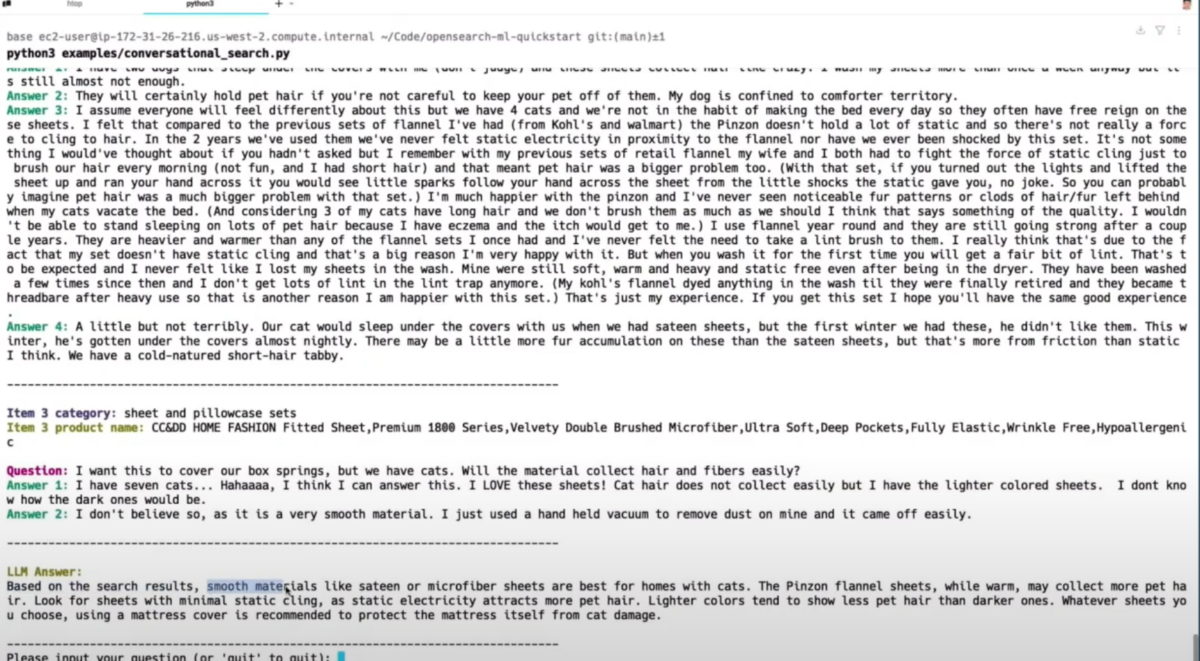
LLMの回答:
検索結果に基づいて、サテンやマイクロファイバーなどの滑らかな素材のシーツを推奨し、具体的な製品名(検索結果の第2の製品)も挙げた。これにより、ユーザーの質問に答えるだけでなく、具体的な製品推奨も提供できることが示された。
まとめ
このセッションでは、OpenSearchにおけるベクトル検索の進化と実装について包括的に説明された。従来の語彙検索から始まり、密ベクトル検索、スパース検索、ハイブリッド検索、そして会話型検索まで、各手法の特徴と利点が実演を通じて示された。
重要なポイント:
- チャット、セマンティック検索、ベクトル埋め込みは、データの取得と対話の新しい方法を提供する
- OpenSearchは必要なツールを提供するが、コネクター、モデル、接続の設定には多くの反復的なコードが必要
- OpenSource ML QuickStartライブラリは、これらの設定を簡素化し、再利用可能な例を提供する
このライブラリはオープンソースであり、開発者は自身のコードや検索アプリケーションに組み込むことができる。デモで示されたすべての例は、QuickStartリポジトリからダウンロードして実行可能である。