OpenSearchCon 2023のセッション「End-to-End Relevance」を日本語でまとめます。 可能な限り正確に内容を拾えるようにリスニングに努めたつもりですが、もし誤りがあればご指摘ください。
OpenSearchCon とは?
各セッションはYouTubeで視聴可能
End-to-End Relevance
セッションリンクは以下
スピーカー
- John Handler
- AWSのシニアプリンシパルソリューションアーキテクト
- OpenSearchと検索技術について長年の経験を持つ
セッションまとめ
検索の魔法と進化
検索は魔法のような体験を提供する。検索エンジンに数単語を入力するだけで、必要な情報が即座に見つかる。この検索の旅は「これが必要」から「それが答えだ」へとユーザーを導くプロセスである。

AI/MLの大きな波が押し寄せる中、大規模言語モデル(LLM)は自然言語理解、コンテキスト、セマンティクスといった新たな機能をもたらし、チャットボットの普及により、ユーザーは自然な会話形式でシステムと対話できるようになった。OpenSearchは、これらのLLMが生成するベクトルを活用し、検索機能を強化する役割を担っている。
検索とは何か


検索とは本質的に、ユーザーが小さな入力ウィンドウで自分のニーズを表現し、それをOpenSearchに送信するプロセスである。OpenSearchは膨大なデータの中から適切なものを見つけ出す必要がある。この「適切なものを見つける」プロセスこそが関連性(relevance)の核心であり、ユーザーの情報ニーズを満たす結果を返すことを意味する。

関連性を生み出す標準的なランキングモデルには以下がある:
- テキスト対テキストマッチング:Okapi BM25によって提供される
- ベクトル類似性:KNNプラグインを使用
学習によるランク付け(Learning to Rank):過去のユーザー行動に基づいて結果を再ランク付け
関連性に影響を与える多様な要素

関連性は単にランキング関数だけでなく、データ処理の全段階で決定される:ソースデータ:そもそもデータが存在しなければ検索できない
- データ準備:ソースデータをユーザーの検索意図に合う形式に変換
- パース・処理・エンリッチメント:データを強化し、より検索しやすい形に整形
- クエリ実行:クエリの修正と改善を含む処理
- OpenSearch内部の処理:テキスト分析、フィールドマッチング、ランキング、リランキング
- フロントエンド:ユーザー行動の追跡とフィードバック
データ準備の重要性

Wikipediaダンプの例では、生データは様々な特殊文字、テキストボックス、セクションマーカーを含む複雑な形式となっている。このような生データは、そのままでは効果的なマッチングには適さない。

WikiTextParserのようなオープンソースツールを使用して、WikiテキストをクリーンでフォーマットされたJSON形式に変換する必要がある。データは常に何らかの形で「汚れて」おり、不要な文字、冗長なコンテンツ、SEOスパム(キーワードの過剰な繰り返し)などを除去する前処理が不可欠である。
LLMのためのデータチャンキング

LLMでベクトル埋め込みを生成する場合、テキストを小さな断片に分割する必要がある。適切なチャンクサイズの選定は自動化が困難で、文書全体を小さな部分に分割するか、代表的な部分を選択するかの判断が必要となる。
データのエンリッチメント

基本的なフォーマット変換後、以下のようなエンチッチを行うことになる:
- クリックデータの追加:ユーザーフィードバックの活用
- ユーザー検索キーワードの追加:検索からクリックに至ったキーワードを文書に関連付け
- エンティティの抽出:例えば、Albert Einsteinに関するページであれば、そのエンティティをキーワードフィールドに追加
- 埋め込みの追加:LLMを使用してベクトル埋め込みを生成
これらの処理には、Neuralプラグイン、DIY方式、サードパーティモデルホスティングなど、複数の方法が利用可能である。
テキスト分析の仕組み

テキスト分析は、文書(フィールドと値のペアの集合)を解析し、エンドユーザーが期待するマッチ可能なトークン(用語)を生成するプロセスである。この分析フェーズは関連性にとって極めて重要で、適切なマッチングができなければ正しい結果は得られない。
分析プロセスでは、フィールドレベルのインデックスが生成され、ポスティングリスト(そのフィールドを含む文書のリスト)と結び付けられる。
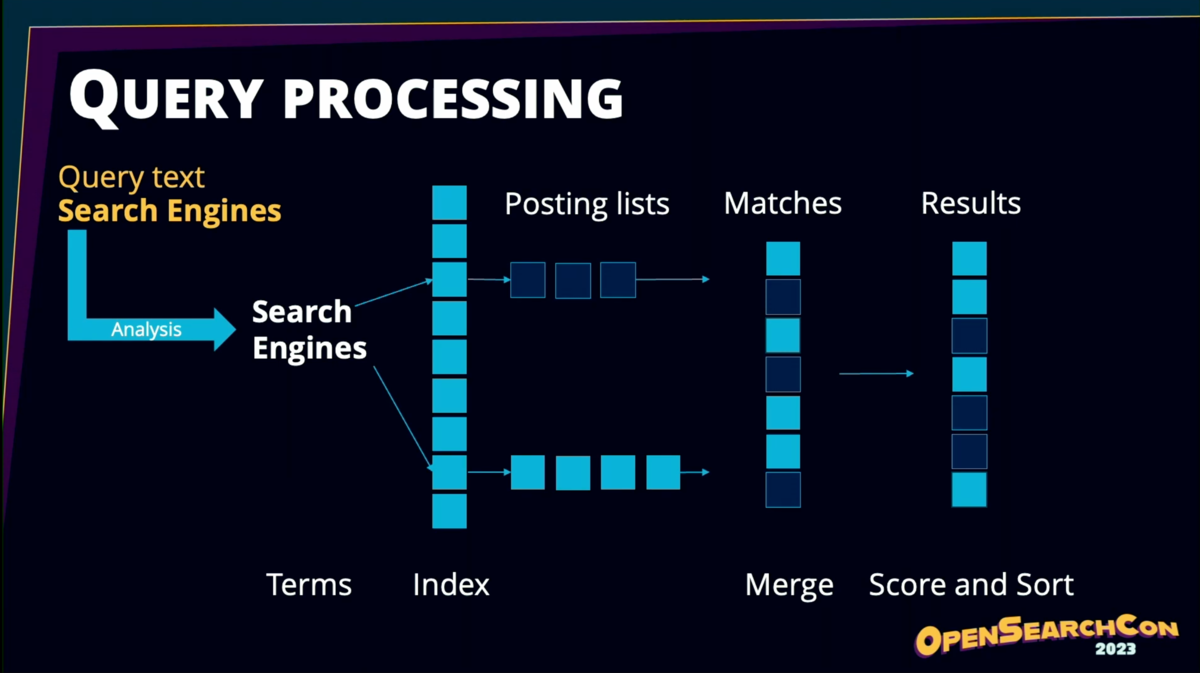
クエリ処理では「search engines」のようなクエリがポスティングリストと照合され、マッチした結果がソートされる。
キーワードフィールドとテキストフィールドの違い

- テキストフィールド:分析され、用語に解析される。カスタム分析を適用可能で、大きなテキストブロックに使用
- キーワードフィールド:正規化されるが、用語には解析されない。カスタムノーマライザーを適用可能で、小さな機械生成テキスト(ファセットなど)に使用
テキスト分析の実例

ソーステキストに対して:
- 標準アナライザー:空白で分割し、小文字化のみを実行
- 英語アナライザー:言語固有のステミングを適用し、「radiation」「radiates」などの異なる形態を同じ語幹にまとめる
これにより、ユーザーがどのような形で単語を入力しても適切にマッチングできるようになる。
テキストベースのランキング

「how does albedo diffuse radiation」というクエリに対して、「albedo」と「Albert Einstein」の両方の文書がマッチする可能性がある。この場合、より多くの単語がマッチする「albedo」を優先すべきである。

OpenSearchの中核的なテキストランキング関数であるOkapi BM25は、この基本的な考え方を実装している:
- IDF(逆文書頻度):コーパス全体での単語の出現頻度の逆数。頻出単語ほど価値が低い
- TF(頻度):特定の文書内での単語の出現回数
- Saturation(飽和制限):単一の用語がスコアを過度に支配しないようにする仕組み

テキストベースのRelevanceをチューニングする手法。
ベクトルランキング

ベクトルは整数の配列で、その次元数がn次元空間を作り出す。各文書はこの空間内の点として表現され、クエリも同じ空間にエンコードされて「近い」ものを見つける。
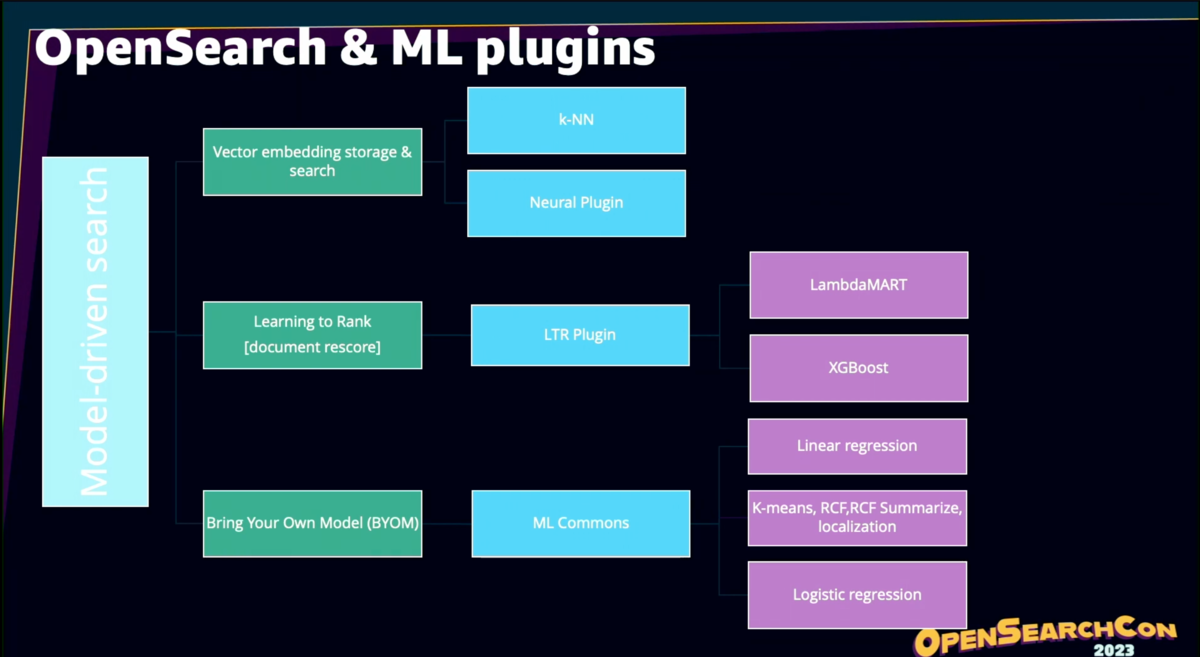
OpenSearchは、これらのベクトルを保存し、類似性マッチングを提供する複数のエンジンとアルゴリズムをサポートしている。
セマンティック検索の実装方法

DIY方式:
- ソースデータに対してバッチジョブを実行
- SageMakerやサードパーティのLLMにデータを送信
- 生成されたベクトルをOpenSearchに保存
- 検索時にクエリをベクトル化し、KNNで距離計算

Neural Plugin方式:
Neural Searchプラグインが埋め込み生成プロセスを自動化。文書とクエリをOpenSearchに送信するだけで、プラグインが自動的に埋め込みを処理する。
Neural Pluginの設定

- モデルをOpenSearchにロード
- マッピングでベクトルフィールドを定義(次元数は必須)
- インジェストパイプラインを追加し、Neural processorを設定
- クエリ時にNeural queryを使用
ユーザー行動の活用
検索結果に対するユーザーの行動を追跡し、システムの改善に活用する:

クエリ側の分析:
- ブランドやカテゴリのランディングページへの検索とアクセス
- 検索ログの調査(上位100クエリとロングテール)
- クエリの適切性評価

クリックストリーム分析:
- クリックや購入などのシグナルで文書をエンリッチ
- ゼロ結果クエリの分析(データ不足または検索方法の問題を特定)
- 壊れたリンクの修正
- セッション分析(単一セッションより複数セッションの分析が効果的)

パーソナライゼーション:
Learning to Rank

Learning to Rankでは以下のプロセスで検索品質を向上させる:
- 特定のクエリと文書の組み合わせについて判断を下し、ゴールデンセット(正解データ)を構築
- 追加の特徴量(ほぼ何でも追加可能)を設定
- XGBoost、LambdaMART、RankLibなどのMLモデルでトレーニング
- 生成されたモデルをOpenSearchにロード
- LTRを使用して検索を実行(初期ランキングの結果を取得し、モデルを適用して再ランク付け)
検索の未来

検索は大きく進化している:
- 10年前:平均2.3語の短いクエリ、意識的なキーワードマッチング
- その後:ファセット(左側のレールに表示される属性と値)の追加。これが後のOpenSearchの分析機能の基礎となった
- 5年前:「どうやって〜するか」「〜には何が必要か」といった質問形式のクエリ
- 現在:チャットボットとLLMによる会話型の検索

今後5年間で、10個のクリック可能な青いリンクという従来の検索結果は過去のものになるだろう。検索エンジンとの対話は会話型になり、小さなテキストボックスではなく、自然な会話を通じて必要な情報を見つけられるようになる。
これが検索の本来の魔法である - 必要なものを見つけるということ。
さらに、現在のOpenSearchのようなモノリシックなシステムから、複数のシステムが協調して動作するアーキテクチャへと移行していく。クエリの処理、改善、ユーザー意図の理解には多様な情報が必要で、複数のクエリシステムが連携することになる。
マッチングはOpenSearchが担当し続けるが、ポストマッチングでは複数のシステムがユーザー行動や他のシグナルを使用して再ランク付けを行う。最終的には、生成と要約により、10個の結果を1つの回答に集約する時代が来るだろう。