Iceberg Summit 2024 のセッション「Table Encryption in Apache Iceberg」を日本語でまとめます。
可能な限り正確に内容を拾えるようにリスニングに努めたつもりですが、もし誤りがあればご指摘ください。
Iceberg Summit とは?
イベント概要
公式ページより翻訳
本イベントでは、Apache Icebergを実務で活用していたり、Icebergの開発に携わる技術者による数十の技術的なセッションが開催されます。計算エンジンの統合、Icebergのデータパイプライン、PyIcebergの利用、データモデリング、データガバナンス、テーブルの最適化とメンテナンス、セキュリティとガバナンスなどのトピックを扱います。
Iceberg Summitは、データエンジニア、開発者、アーキテクト間でのApache Icebergの教育と知識共有を促進するために、Apache Software Foundationが承認したイベントです。
イベントページ
(イベントページが消えてしまったので web.archive.org より)
各セッションはYoutubeで視聴可能
Table Encryption in Apache Iceberg
スピーカー
- Gidon Gershinsky
Iceberg におけるテーブルの暗号化とは?
本セッションにおける議論では、Icebergテーブルの保管中の暗号化(Data at Rest)を扱う。
また、ここでのリスクシナリオでは、何らかの理由でIcebergのバックエンドを構成するストレージのセキュリティに頼れないシナリオを想定している。つまりストレージのアクセス権が奪われるなどして、データが漏洩したり、悪意を持って改変され得る前提に立って、ストレージにデータを送信する前に保護を行う必要があると考える。(クライアントサイド暗号化)
(筆者注:これは「ストレージが脆弱である前提」ではなく、システム内に複数の防御層を設置する多層防御の一環として捉えるべきものと思われる)
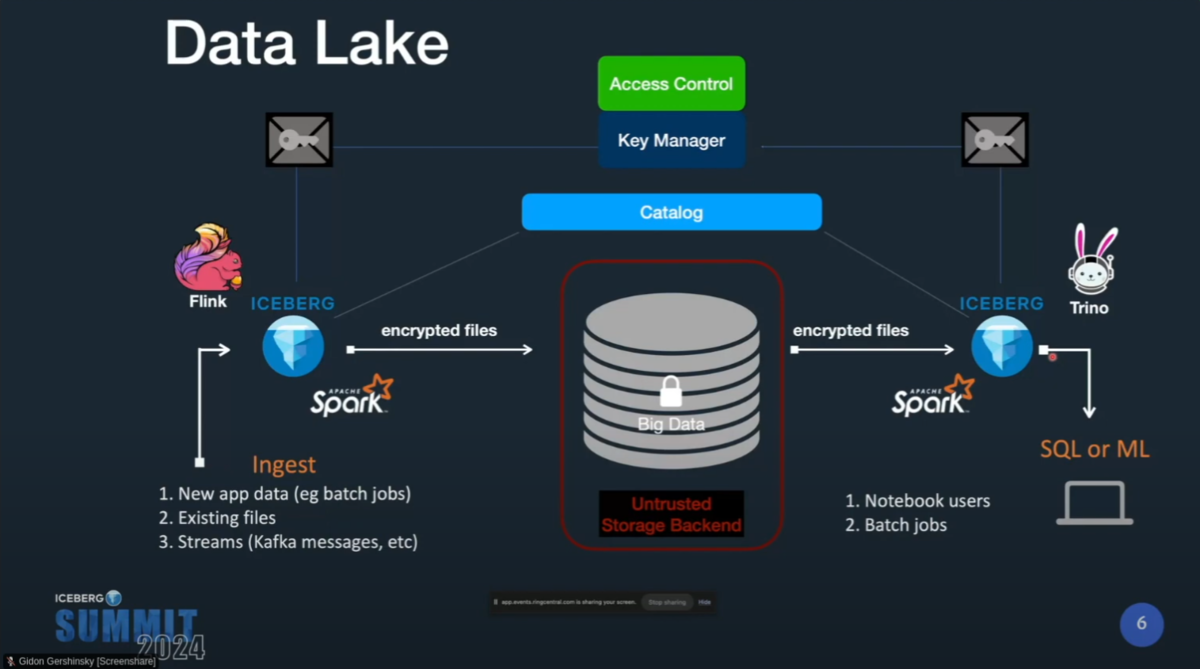
データの取り込み時にSparkやFlinkが Key Manager から暗号鍵を取得して暗号化してIcebergテーブルをストレージへ送信し、Trinoなどがテーブルを参照する際は同様にKey Managerから鍵を取得して復号する流れ。
Data at Rest におけるデータ保護の目的は以下の二点である。
- 機密性の確保(keep the data confidential)
- 暗号化によってデータが悪意ある攻撃者に漏洩しないようにする
- 改竄の防止(keep the data tamper-proof)
- 暗号署名と一意なIDによって、データが改竄されない(改竄されたらわかる)ようにする
ここでの「データ」とは、Iceberg における data file, manifest file, manifest list, metadata fileを指す。
(筆者注:Iceberg Tableを構成するファイルについて詳しくはこちらの記事をご参照ください )
https://bering.hatenadiary.com/entry/2023/09/24/175953

Iceberg の built-in 暗号化エンジン
Icebergはクライアントサイドの暗号化に関して以下を実現している。(一部は現在開発中)
- 暗号化と改竄防止を実現する仕組みをライブラリに内包
- 様々なクラウド、ストレージで共通的に機能する
- 様々なストレージをパラレルに利用できる
- あるストレージのテーブルを、都度復号、抽出、暗号化することなく、単にファイルの移動だけで別の場所へ移行できる
- (筆者注:暗号化の文脈では問題なくても、ファイルを移動すると各ファイルのパスが変わってメタデータが壊れるので、単純にファイルを移動するだけでは移行できないのでは?)
- 暗号鍵へのアクセス権を持つユーザに対して、簡単にテーブルを共有できる
(前提としてクライアントサイドの暗号化なので、暗号化前のデータと暗号鍵はストレージ側からは見えない)

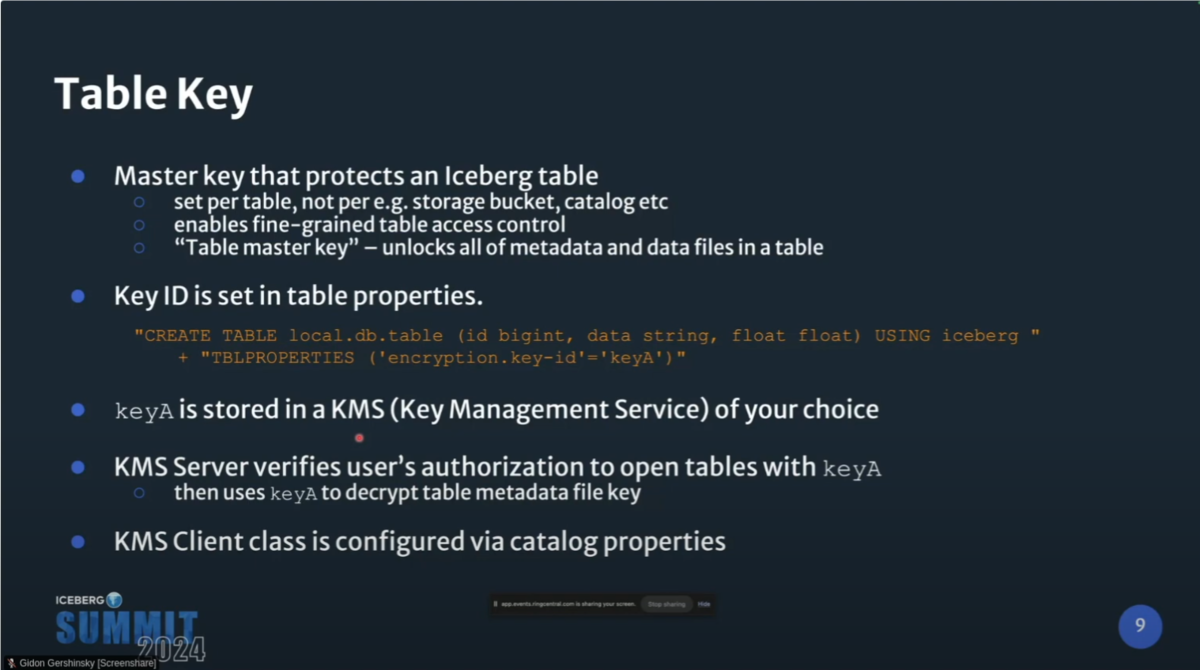
Table Key
Iceberg Tableにはテーブルごとにマスターキーを設定でき、マスターキーを起点としてIceberg Tableを構成する各ファイルを復号できる仕組みになっている。
マスターキーのIDはtable propertyで設定する。プロパティで指定するのは、使用しているKey Management Service(KMS)の鍵の名前。
Key Management Serviceがユーザの暗号鍵へのアクセスを認可して鍵を取得し、その鍵によってIceberg Tableを復号する。
ここで、使用するKMSの実装はカタログのプロパティで指定できる。
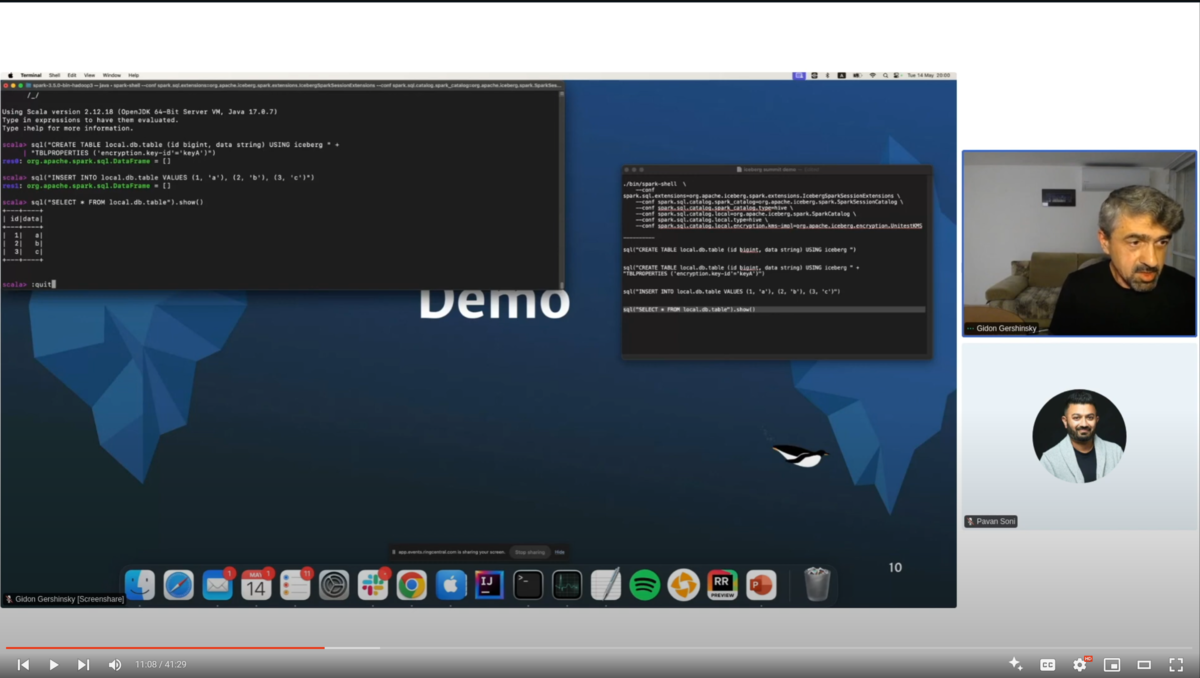
デモ
Table Keyを指定する場合としない場合で、各ファイルにどう違いが出るか(どう暗号化されるか)がライブデモで解説されているので、youtubeの動画をぜひご覧ください。(7:40頃~)
開発状況
Iceberg Tableの暗号化に関わるPRは以下の通り。

(筆者注:本記事執筆時点(2024/9/21)では#7770, #5544 は依然活発に開発が進行中)
IcebergのTable暗号化は全体的にMVP(minimum viable product)の段階であり、今後改善の余地が大いにある。現状では以下の制約がある。
- サポートしているエンジンはSparkのみ
- FlinkとTrinoに関しては現在開発中
- ParquetとAvroのみサポート
- ORCは末サポート
- Parquetファイルのカラムレベルで使用する暗号鍵を変えることはできない
- Hive Catalog のみサポート
- REST Catalogのサポートを現在開発中

Deep Dive
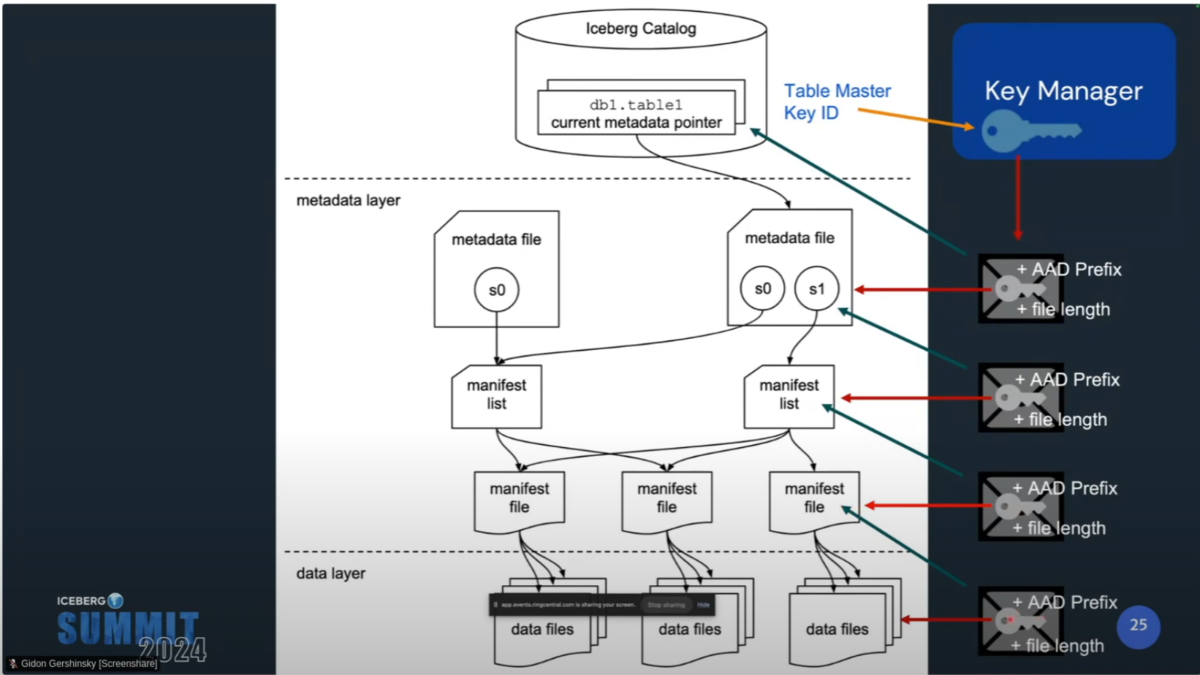
Icebergテーブルを構成する各レイヤーは複数の鍵で暗号化され、それらは階層的に管理される(Envelope Encryption)。これによって効率的なテーブルアクセスや、改竄防止が実現する。
- data fileを暗号化し、鍵(data key)をmanifest fileに保存する
- manifest fileを暗号化し、鍵(manifest key)をmanifest listに保存する
- manifest listを暗号化し、鍵(manifest list key)をmetadata fileに保存する
- metadata fileを暗号化し、その鍵(metadata key)をKMSのマスターキー(table master key)で暗号化し、KMSに保存する
- KMSのメタデータをCatalogに保存する
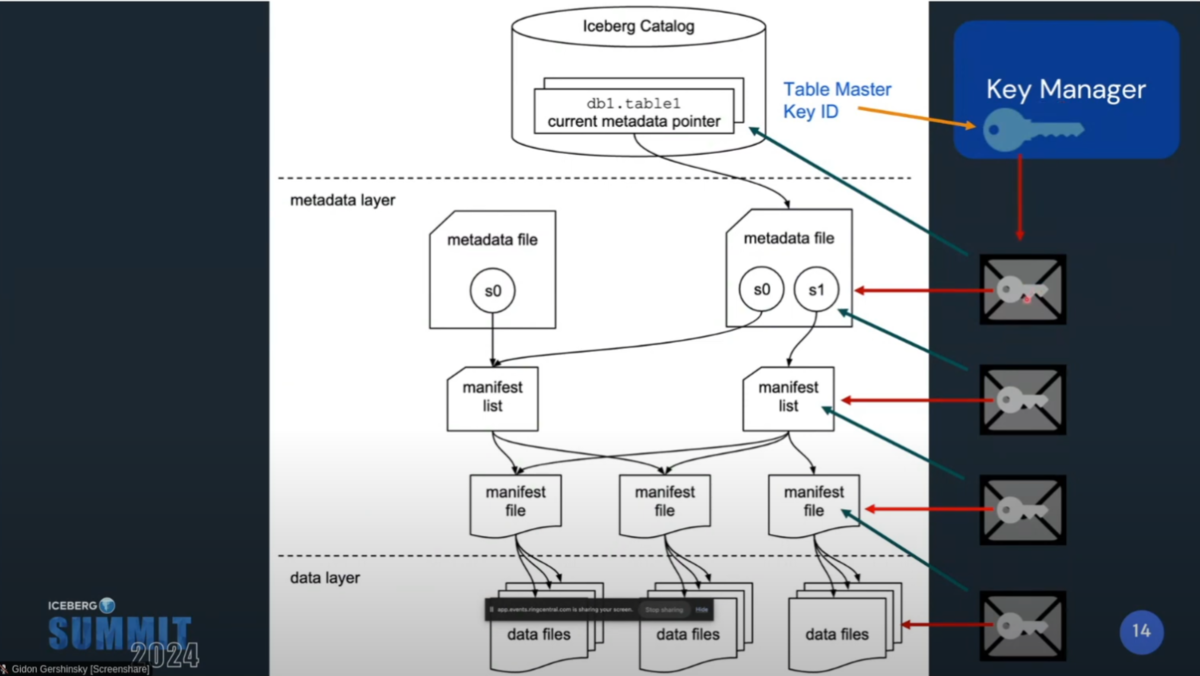

マスターキーはプロダクショングレードなKMSに保管される必要がある。パブリッククラウドが提供するKMSや、OSSのKMSソフトウェアなど。
(筆者注:OSSではvaultやkeycloakが有名ですかね)
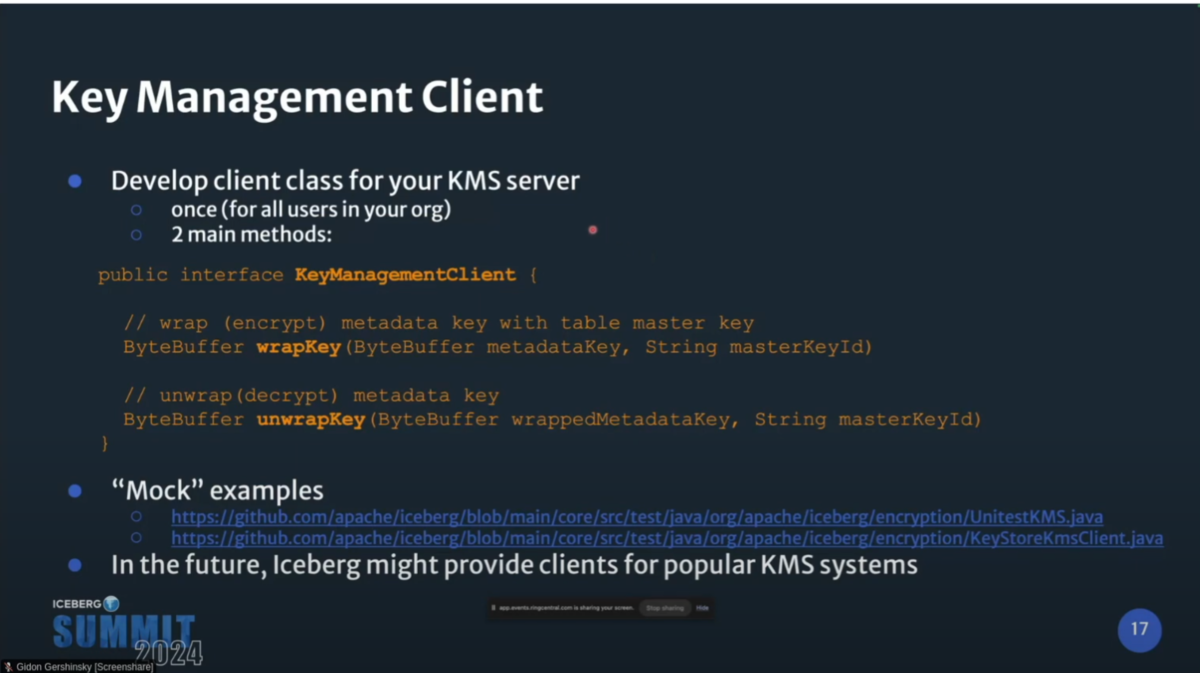
Iceberg KMS Clientインターフェースを実装するclassがあれば、どのようなKMSでもサポートできるようになっている。

KMSのクライアントクラスは以下のような実装となる。主要な関数はwrapKeyとunwrapKeyの2種類だけ。
(筆者注:現在ではKmsClientインターフェースはDeprecatedであり、KeyManagementClientインターフェースの使用が推奨されている)
Icebergプロジェクトはいくつかの"Mock"実装を公開している。
将来的には、Icebergプロジェクトが主要なKMS用のクライアントを公開するかも。
Parquetの暗号化では、Parquet Modular Encryption(PME)を採用している。
(筆者注:PMEはParquetファイルのモジュールを別個に独立して暗号化することで、効率的なファイルアクセスを実現したり、モジュールごとに異なる鍵を使用するといったことを実現する)
PMEによって、Parquet全体を暗号化しつつ、カラムレベルのプロジェクション、predicate pushdown、圧縮、エンコードなどParquetの機能を使うことが出来る。
つまり、暗号化がクエリエンジンの性能に与える影響を緩和出来る。

改竄防止の観点では、Iceberg Tableを構成するファイルの内容が改竄されていないことと、置き換えられていないことを保証しなければならない。そのためにAES GCMを採用している。
筆者注:Galois/Counter Mode(GCM)は認証付き暗号の一つで、データ保護とメッセージ認証機能を提供する。
wikiより
GCMには鍵 K、平文 P (暗号化されるデータ)、関連データ(associated data. 暗号化せず認証だけされるデータ) A が与えられ、平文から暗号文 C が計算され、C と A から認証タグ T が計算される。 鍵 K を知っている受信者が A, C, T を受け取ったならば、受信者は暗号文を復号して平文 P を得ることができ、また認証タグ T をチェックすることで、暗号文や関連データが改ざんされていないことを確認できる。
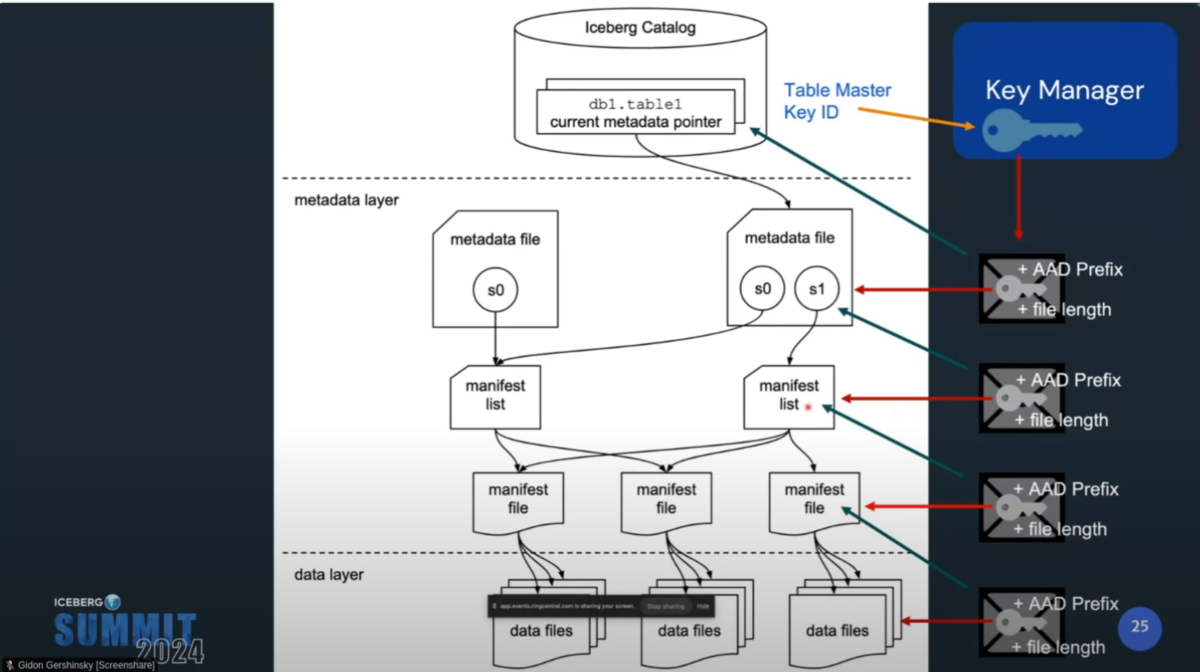
Icebergでは、Parquetの各モジュールがmodule AAD(ファイルレベルのユニークID(AAD prefix)と各モジュールのユニークID(AAD suffix)を結合したもの)によって署名される。その上で、Maenifest FileはData Fileの暗号鍵とファイルレベルのユニークID(AAD prefix)をkey metadataとして保持する。

Avroに関してはネイティブな暗号化機構がないため、Iceberg独自にAvroやJSONなどでGCMを使えるようにする「AES GCM Stream file format extension」を開発した。
Avroの各blockはGCMで署名と暗号化される。AADにはファイルのユニークID(AAD prefix)とblock sequence number(AAD suffix)を使用し、Manifest fileにファイルのレベルのユニークID(AAD prefix)と暗号鍵、ファイル長をkey metadataとして保管する。
これによってAvroの暗号化と改竄防止が実現する。


Manifest fileとmanifest listのAvroについても、AES GCM Streamによって暗号化、改竄防止される。

Metadata Fileを構成するJSONについてもAES GCM Streamで暗号化、改竄防止する。ここで、Metadata FileのMetadata keyはKMSのテーブルマスターキーによって暗号化される。
Metadata FileのKey metadataは暗号化されたmetadata keyと、AAD prefixで構成され、カタログに保管される。
(Key metadata自体は機密情報を露出しない。ただし、これ自体も改竄から保護される必要があるが、殆どの場合それを管理するカタログはストレージから独立しているため、ストレージのリスクから保護するシナリオでは問題にならない)

以上を踏まえて、AADの情報は以下のように管理される。
暗号化によるパフォーマンスへの影響
AES GCMはハードウェアレベルで実装されており高速である。(Gigabyte per sec)
Metatada keyの暗号化に必要なKMSとの通信はIcebergのテーブル構成上頻繁には発生せず、その他の各ファイルの暗号化は(KMSではなく)ローカルで完結するため、KMSとの通信を最小限に抑えることでレイテンシを抑えられる。
(筆者注:これ、KMSへの負荷を抑えられる意味でもとてもいい機構だな...)
従って、理論的にはIcebergの暗号化のオーバーヘッドは小さいと考えられる。今後、ベンチマークを実施しようとしている。



今後の展望
- Iceberg Table Encryptionを構成する残る2PRを完成させる
- FlinkとTrinoのサポート
- より幅広いカタログのサポート
- パフォーマンスベンチマーク
- Parquetのカラムレベルで異なるマスターキーを使えるようにする
- ORCのサポート

QA(サマリ)
Q1:キーローテーションはサポートされる?また、サポートされるとして、それはテーブル全体を再度復号化、暗号化することになる?
A1:マスターキーに関しては、ほとんどのKMSはキーローテーションをサポートするので、それを使えば良い。各ファイル自体の暗号鍵をローテーションする必要がある場合は、マスターキーのローテーション後にprocedureでrewriteすることになる。
Q2:Icebergや、Iceberg Table EncryptionはFedRAMP準拠ですか?
A2:まずFedRAMPのどの要件の話をしているかを確認しなければならない。オフラインで話しましょう
Q3:Icebergに他の暗号化機構を持ち込むことは出来る?
A3:コントリビュート待ってるよ
Q4:これらの暗号化機構はクエリエンジン間で透過的ですか?
A4:現状はSparkしかサポートしてないけど、仕組みとしては透過的に出来るようになっている。だからTrinoやFlinkについても透過的になっていくだろう
Q5:どのKMSがサポートされますか?KMS喉の機能がサポートされますか
A5:Custom Classを実装すれば、どのようなKMSでも使えるし、拡張できるので、全ては開発者次第だ
Q6:カラムレベルで違うマスターキーを設定できるようにする計画はある?
A6:Yes
Q7:統計情報に機微情報が含まれる場合はどうすれば?
A7:そのためにTable全体を暗号化出来るようにしてあるので大丈夫
Q8:どのカタログがサポートされる?
A8:今はHive Metastoreだけです。自前でカスタムすれば、様々なカタログで動かせます
Q9:Puffinもサポートされる?
A9:Puffinの暗号化は今後の改善ポイントの1つ