はじめに
今日のビッグデータを扱うアプローチとして、HDFSやS3などにデータを蓄積して、Hive Metastore等でテーブルとして抽象化し、TrinoやSpark等のエンジンから操作するアーキテクチャが広く実践されている。これは手軽で便利である一方で、データ基盤が大規模化、複雑化するに従って様々な課題が出てくる。
- 同時読み取り/書き込みの独立性を担保できない
- テーブル変更後に過去の状態が復元できない
- テーブルを構成するファイル/パーティションの増加に従ってテーブル操作が遅くなる
- スキーマ変更への追従が大変
- レコードレベルの読み取り/書き込みが遅い
- パーティションを活かすには、クエリ実行者がテーブルの物理構造を把握している必要がある
こうした課題へのアプローチとして、Apache Iceberg, Apache Hudi, Delta LakeなどのOpen Table Format(OTF)と呼ばれる技術への注目が高まっている。本エントリでは、「Icebergとは何か」について基本的な考え方から出発して、少しDeep Diveした仕組みまでを紹介する。
従来の課題やOTF登場の背景の詳細については以下エントリを参照して欲しい。
bering.hatenadiary.com
概要
Apache Iceberg(アイスバーグ)とは
iceberg.apache.org
Apache Icebergは2017年にNetflixが開発したApache License 2.0のテーブルフォーマットで、巨大かつ複雑なテーブルをSpark、Trino、Flink、Presto、Hive、Impalaなどから効率良く扱える仕組みを提供する。Netflixは2018年時点でS3上に60ペタバイトのデータレイクを保持しており、これらのデータを多様なエンジンから一元的かつ効率良く扱う必要に迫られてIcebergが開発された。開発の背景は以下の動画で詳しく語られている。
www.youtube.com
個人はもちろん、多様な企業が開発に参加しており、Appleなどが積極的にコントリビュートしている点は興味深い。
 ]
]
[重要] Icebergの本質はTable Specである
最初に留意すべき点として、IcebergはStorage EngineでもCompute Engineでもなく、Table Specである点が挙げられる。つまり、Iceberg自体はテーブルフォーマットの仕様に過ぎず、それ自体が特定のソフトウェアやプロセスを指すものではないということだ。
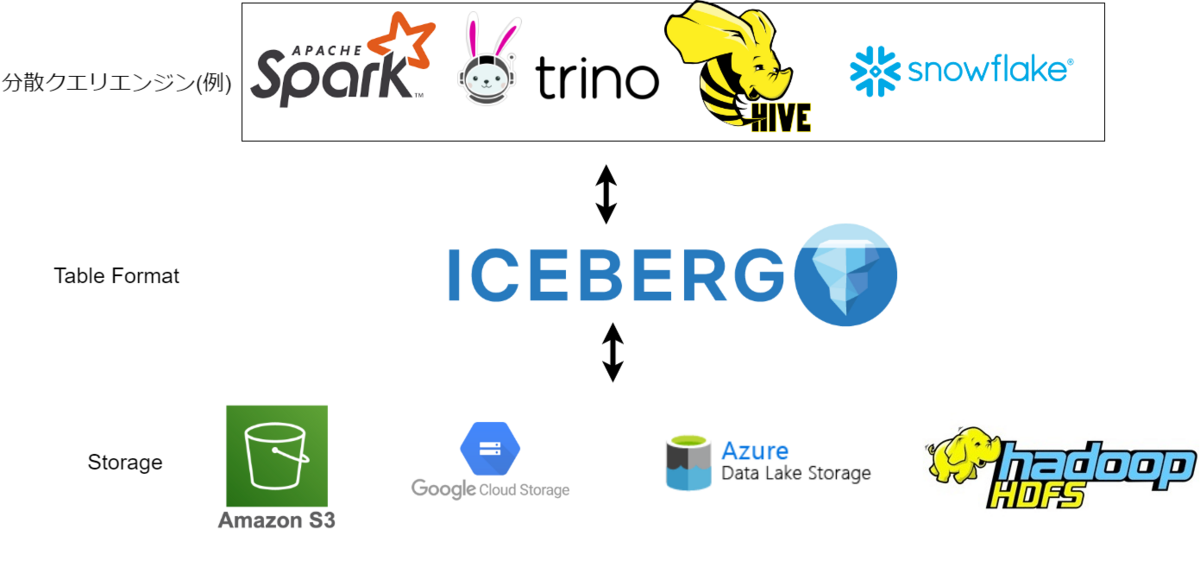
つまり、実際にIceberg Tableを扱うのはSparkやTrino, Hiveなどのエンジンであって、各エンジンがIcebergのTable Specに従ってデータ/メタデータを書き込み/読み取りすることでIcebergを実現する。Iceberg Table Specは以下に定義されており、ここに書いてあることが一義的な「Icebergの仕組み/機能」ということになる。
iceberg.apache.org
ただし、それらをどこまで/どのように実現するかはエンジン側のサポート、実装次第であるため、Iceberg Table Specに書いてあることが必ずしも各エンジンで使用できるとは限らない点に注意しなければならない。例えば、TrinoはCopy on Write Modeをサポートしていない。従って、Icebergを理解/検討する上ではIceberg Specと、利用しようとしているエンジンの仕様の両方を把握しておく必要がある。 本エントリではIcebergの様々なConfigurationを紹介するが、それらもエンジンによってサポートの有無が異なり、場合によっては細かい挙動が異なる可能性もある点を留意いただきたい。
なお、Apache IcebergプロジェクトではIceberg テーブルを扱うためのcore Java libraryを開発&提供している。
github.com
Javaに加えて、go、python、Rust実装ライブラリも開発が進んでいる。
別の観点で近年の面白い傾向として、従来内部的なTable Formatをクローズに扱ってきたSnowflakeやAmzon RedshiftなどのDWH製品が、Iceberg Tableへのクエリをサポートするようになってきている。つまり、All in OneなDWH製品でありつつも、テーブルデータのレイヤーに関してはオープンなものにしておいて、他のエンジンからの相互乗り入れが可能になりつつある。これは文字通り「Open Table Format」が目指す未来の一端を示していて、新しいデータ基盤アーキテクチャへの可能性を秘めているのではないかと感じる。
www.snowflake.com
aws.amazon.com
Table Spec バージョン
2023/9/24現在、バージョン1系とバージョン2系の2つのメジャーバージョンがあり、後方互換性が失われる変更が入る時点でインクリメントされることになっている。バージョン1と2でいくつか大きくレベルアップしている点があるため、今から使い始めるなら特別な理由がない限り2系を使用するのが良いだろう。
Icebergハンズオン
これからApache Icebergを学びたい人向けの実践的なハンズオンを以下で公開している。コンテナが動く端末が1台あればクイックに始められる内容にしてあるので、ぜひチェックして欲しい。
Icebergの特徴
同時書き込み時の整合性担保
楽観的並行性制御によって、複数のReader, Writerが並列して読み取り/書き込みを実施する場合でも、一貫性を担保できる。具体的には、書き込み時に事前にテーブルロックは実施することはせず、一連の書き込み処理が完了後、対象のメタデータの更新時に競合を確認し、発生していない場合のみコミット、発生している場合は再試行を行う。(テーブル操作のライフサイクルの項を参照) Isolationレベルとしては、SERIALIZABLEとSNAPSHOTがサポートされている。また、悲観的並行性制御についても将来的なサポートが予定されている。
読み取り一貫性、Time Travelクエリ、Rollback
Iceberg Tableの更新では、古い物理データを削除せず、新しいバージョンのデータとメタデータ(snapshot)を生成する形になる。従って、ユーザがテーブルに対してクエリを実施する場合、ある特定の断面のデータが参照されることを保証することが出来る。言い換えるならば、継続的にテーブルが更新されている場合であっても整合性の取れたデータを参照できる。
また、過去の断面をimmutableに保持することで、過去のある時点/ある断面に対するTime Travelクエリが可能になる。また、Tableの状態を過去のある時点にRollbackできる。
Schema Evolution
テーブルへのカラムの追加や削除、カラムの名前の変更、カラムのデータ型の変更などの操作は、論理的なメタデータを変更するのみで、物理的なデータに影響を与えない。つまり、スキーマ変更に伴って新しいスキーマのテーブル(物理データ)を新規に作成する必要はなく、新旧のスキーマのデータが入り混じったテーブルをシームレスに操作できる。
サポートされるスキーマの変更は以下の通り。
- Add - テーブルまたはネストされた構造体に新しいカラムを追加
- Drop - 既存のカラムをテーブルまたは入れ子構造体から削除
- Rename - ネストされた構造体の既存の列やフィールドの名前を変更
- Update - 列、構造体フィールド、マップ・キー、マップ値、またはリスト要素の型を拡張
- Reorder - 入れ子構造体の列またはフィールドの順序を変更
Hidden Partitioning
Icebergでは、テーブルを構成するファイルの物理的な構造に基づいてパーティション構造を参照するのではなく、メタデータを元にパーティション構造を把握する。従って、ユーザのクエリを解釈する際に特定のロジックに基づいて実行計画を立てることが出来るため、結果としてユーザがテーブルの物理構造をあまり意識せずパーティショニングの恩恵を受けることができる。また、パーティショニング用に追加のカラムを作成する必要がないため、結果的にデータサイズを小さくできる。
例えば、時刻情報としてtimeカラムを持つhogeテーブルをPARTITIONED BY months(time)として定義した場合、データは月(months)ベースでパーティション管理される。一方で、ユーザはこれらの設定を知っている必要はなく、単にtimeをwhere句に指定するだけで内部的にパーティショニングの恩恵を受けることが出来る。
SELECT * FROM hoge WHERE time BETWEEN '2023-09-01 00:00:00' AND '2023-09-31 00:00:00';
Hidden Partitioningの種類
時間
タイムスタンプ型のカラムに対して、years,months,days,hoursを指定する。
truncate[W]
カラムの切り捨てられた値に基づいてテーブルを分割する。例えばtruncate(name, 1)とした場合、nameカラムの1文字目の値によってパーティショニングが行われる。
bucket[N]
hash関数によって、指定された数のバケットにレコードを分散する。例えば、bucket(20, prefecture)とした場合、prefectureの値ごとに20のバケットに分散してデータを格納する。(いわゆるバケッティング) これはカーディナリティの高い(ユニークな値が多い)カラムに向いている。
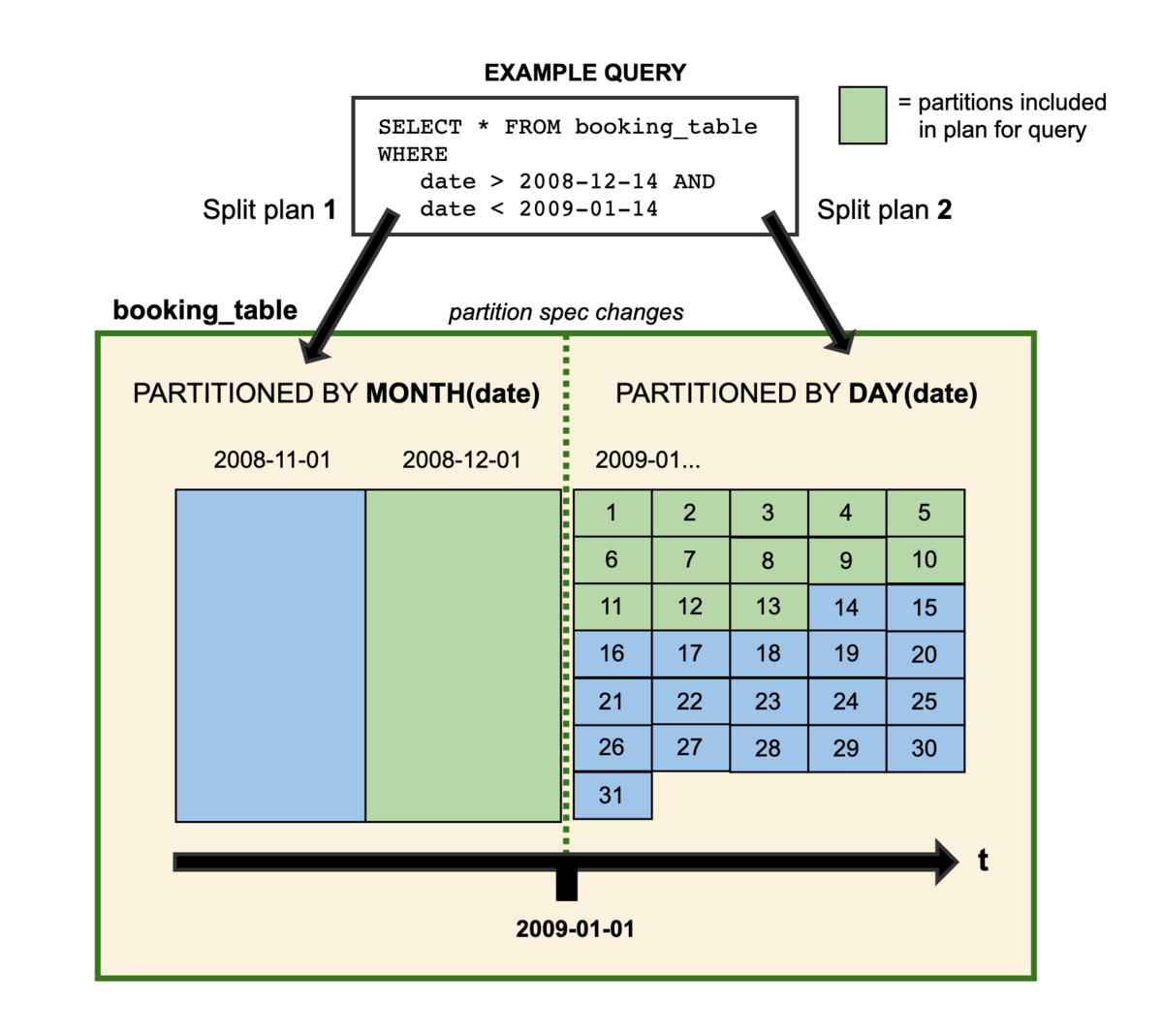
Partition Evolution
Icebergはパーティションスキームのバージョン情報をメタデータとして管理するため、テーブルのパーティション方式をテーブルを作り直さずに途中で変えることが出来る(古いデータは変更されない)。例えば、元々month単位でパーティションしていたテーブルを途中からday単位でパーティションするように変更する、という運用が可能になる。エンジンは新旧のパーティション方式に対して別々にプランニングを行い、最後に全体的な実行計画を作成する。
Sort Order Evolution
既存のテーブルのSort順を途中で変更することが出来る。これもSchema Evolutionと同じく論理的なメタデータを変更するのみで、物理的なデータに影響を与えない。
クエリ性能の最適化
メタデータの工夫によって、実行計画とデータ参照の両面で性能を最適化することで、レコードレベルの読み取り/書き込み/更新/削除であっても、性能を最適化出来る。
ユースケース
以下記事の「従来のデータレイクの技術的課題とユースケースの要請」の項をお読みください。 bering.hatenadiary.com
Icebergのアーキテクチャ
Icebergのtableは3つのレイヤーで構成される。

Iceberg Catalog
現在の最新断面のメタデータが格納されているmetadata fileのロケーションをポイントする。Reader, Writerは最初にIceberg Catalogを参照して、それを起点にmetadata fileの木構造を下っていく。
Iceberg Catalogの選択肢
Catalogに求められる基本的な要件はテーブルパス(例えば "db1.table1")をテーブルの現在の状態を持つmetadata fileのロケーションにマッピングすることであるため、その実装としてはオブジェクトストレージ、Hive Metastore, Nessieなど多様な選択肢を検討できる。ただし、同時書き込みが発生した場合の整合性の確保、つまりreader,writerがある時点において同じ状態のtableを参照できることを保証するためには、metadataのポインタをAtomicに更新できなければならず、構成によってはそれが保証されないリスクがある点には注意が必要である。
また、Icebergカタログをサポートするソフトウェアによってはより高度な機能を実現するものもある。例えばNessieは複数のテーブル、SQLステートメントでもトランザクションの一貫性を確保することが出来る。また、Dremio ArcticやTabularのIceberg CatalogはTableのComapactionなどのメンテナンスを自動化する仕組みを提供する。
metadata layer
Icebergの根幹を成すツリー構造のメタデータで、個々のデータとそれらのメタデータ、オペレーションを追跡する。metadata files,manifest lists,manifest filesの3種類がある。IcebergはこれらのメタデータによってTimetravelクエリやSchema Evolutionなどを実現する。metadata layerのファイル群はData Layerと同じように、HDFSのような分散ファイルシステムや、Amazon S3, Azure Storage, Google Cloud Storageなどのスケーラブルなオブジェクトストレージに保管する。
metadata files
ある時点でのIcebergのメタデータの集合を管理する。テーブルのスキーマ、パーティション、スナップショット、現在のスナップショット情報などが含まれる。Icebergテーブルが変更されるたびに新たなmetada fileが生成される。
metadata fileのフィールド一覧(クリックして展開)
| v1 | v2 | フィールド | データ型 | 説明 |
|---|---|---|---|---|
| required | required | format-version | integer | フォーマットのバージョン番号(整数)。現状は1か2。テーブルのバージョンがサポートされているバージョンより高い場合、実装は例外をスローしなければならない。 |
| optional | required | table-uuid | string | テーブルの作成時に生成される、テーブルを識別するUUID。実装は、メタデータをリフレッシュした後にテーブルのUUIDが期待されるUUIDと一致しない場合に例外をスローしなければならない。 |
| required | required | location | string | テーブルのベースパス。これはwriterがdata files, metadatafiles, table meta datadata filesの格納場所を決定するために使用される。Ex. "s3://bering-labo/iceberg-labp/test_tables/deals" |
| required | last-sequence-number | 64-bit signed integer | テーブルのスナップショットの順序をトラックするのに用いるシーケンス | |
| required | required | last-updated-ms | 64-bit signed integer | テーブルが最後に更新されたunixエポックからのミリ秒単位のタイムスタンプ。各table metadata fileは、書き込みの直前にこのフィールドを更新する必要がある。 |
| required | required | last-column-id | integer | テーブルのカラムIDの中で最も大きいもの。Schema Evolution時に常に未使用のIDが割り当てられるようにするために使用される。 |
| required | schema | テーブルの現在のスキーマ (v2 ではDeprecatedで、schemasと current-schema-id を代わりに用いる。 | ||
| optional | required | schemas | array | スキーマのリストで、schema-idで管理する。ex. [{ "type": "struct", "schema-id": 0, "fields": [ { "id": 1, "name": "deal_id", "required": false, "type": "long" }, { "id": 2, "name": "category", "required": false, "type": "string" }, ] }] |
| optional | required | current-schema-id | integer | 現在のテーブルスキーマのID |
| required | partition-spec | array | テーブルの現在のパーティション仕様。Writerが書き込み時にパーティショニングするために使用する。ただし、Readerは別途manifest fileに格納された仕様を使用するため、読み取り時は使用しない。v2 ではDeprecatedで、partition-specs とdefault-spec-id を代わりに用いる。 | |
| optional | required | partition-specs | array | パーティション仕様のリスト。 |
| optional | required | default-spec-id | integer | Writerがデフォルトで使用する現時点のパーティション仕様のID |
| optional | required | last-partition-id | integer | 最も大きなパーティション仕様のID。Schema Evolution時に、パーティションフィールドに常に未使用のIDが割り当てられるように使用する。 |
| optional | optional | properties | map | テーブルプロパティのマップ。これは読み書きに影響する設定を制御するために使用されるもので、任意のメタデータ付与に使用することは想定されていない。 |
| optional | optional | current-snapshot-id | 64-bit signed integer | 現在のテーブルスナップショットのID。refsのmainブランチの現在のIDと同じでなければならない。 |
| optional | optional | snapshots | array | 有効なスナップショットのリスト。有効なスナップショットとは、すべてのdata fileがファイルシステムに存在するスナップショットを指す。Data fileは、それがリストされていた最後のスナップショットがガベージコレクションされるまで、ファイルシステムから削除してはいけない。 |
| optional | optional | snapshot-log | array | タイムスタンプとスナップショットIDのペアのリストで、テーブルの現在のスナップショットの変更をエンコードする。current-snapshot-idが変更されるたびに、新しいエントリが last-updated-msと新しいcurrent-snapshot-idで追加されなければなりません。スナップショットが有効なスナップショットのリストから期限切れになると、期限切れになったスナップショットのエントリは、snapshot-logから安全に削除することができる。 |
| optional | optional | metadata-log | array | メタデータ変更をエンコードするための、タイムスタンプとmetadata fileパスのペアのリスト。 |
metadata fileの例(クリックして展開)
{
"format-version" : 2,
"table-uuid" : "69c64178-80ad-4a24-adec-65e8d6633390",
"location" : "s3://bering-iceberg-labo/test",
"last-sequence-number" : 0,
"last-updated-ms" : 1695365659317,
"last-column-id" : 4,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "deal_id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "category",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "deal_amount",
"required" : false,
"type" : "decimal(10, 2)"
}, {
"id" : 4,
"name" : "deal_ts",
"required" : false,
"type" : "timestamp"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"write.object-storage.enabled" : "true",
"write.object-storage.path" : "s3://bering-iceberg-labo/test/data"
},
"current-snapshot-id" : -1,
"refs" : { },
"snapshots" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
}
manifest lists
テーブルのスナップショットに対応する全てのmanifest fileのリストで、manifest fileに対応する構造体が入っている。これには追跡対象のdata fileの場所、所属するパーティション、パーティション列の上限、下限などの情報が含まれる。
manifest listのフィールド一覧(クリックして展開)
| v1 | v2 | フィールドid | フィールド | データ型 | 説明 |
|---|---|---|---|---|---|
| required | required | 500 | manifest_path | string | manifest fileのロケーション |
| required | required | 501 | manifest_length | long | manifest fileのバイト長 |
| required | required | 502 | partition_spec_id | int | マニフェストの書き込みに使用されるパーティション仕様の ID。partition specs にリストされている必要がある。 |
| 517 | content | int | マニフェストによって追跡されるファイルの種類。データまたは削除ファイルのいずれか。0: data, 1: deletes | ||
| 515 | sequence_number | long | マニフェストがテーブルに追加されたときのシーケンス番号。 | ||
| 516 | min_sequence_number | long | マニフェスト内のすべてのライブデータまたは削除ファイルの最小データ シーケンス番号。 | ||
| required | required | 503 | added_snapshot_id | long | manifest fileが追加されたスナップショットのID |
| optional | required | 504 | added_files_count | int | ステータスが ADDED (1) であるマニフェスト内のエントリの数。 |
| optional | required | 505 | existing_files_count | int | ステータスがEXISTING (0)であるマニフェスト内のエントリの数。NULLの場合、非ゼロと見なされる。 |
| optional | required | 506 | deleted_files_count | int | ステータスがDELETED (2)であるマニフェスト内のエントリの数。NULLの場合、非ゼロと見なされる。 |
| optional | required | 512 | added_rows_count | long | マニフェスト内のすべてのファイルのうち、ステータスが ADDED である行の数。NULLの場合、非ゼロと見なされる。 |
| optional | required | 513 | existing_rows_count | long | マニフェスト内のすべてのファイルのうち、ステータスがEXISTINGである行の数。NULLの場合、非ゼロと見なされる。 |
| optional | required | 514 | deleted_rows_count | long | マニフェスト内のすべてのファイルのうち、ステータスが DELETED である行の数。NULLの場合、非ゼロと見なされる。 |
| optional | optional | 507 | partitions | list<508: field_summary> | spec 内の各パーティション・フィールドのフィールドサマリーのリスト。リストの各フィールドは、manifest fileのパーティション仕様のフィールドに対応する。 |
| optional | optional | 519 | key_metadata | binary | 暗号化のためのキーメタデータ |
| v1 | v2 | フィールドid | フィールド | データ型 | 説明 |
|---|---|---|---|---|---|
| required | required | 509 | contains_null | boolean | マニフェストに、フィールドに NULL 値を持つパーティションが少なくとも 1 つ含まれているかどうか。 |
| optional | optional | 518 | contains_nan | boolean | マニフェストがフィールドに NaN 値を持つパーティションを少なくとも 1 つ含むかどうか。 |
| optional | optional | 510 | lower_bound | bytes | パーティションフィールドの非 null、非 NaN 値の下限値、またはすべての値が null または NaNの場合は null。 |
| optional | optional | 511 | upper_bound | bytes | パーティション・フィールドの非 null、非 NaN 値の上限値、またはすべての値が null または NaNの場合は null。 |
manifest files
manifest filesはdata layerの各ファイル(data files, delete files, puffin files)を追加の統計情報と併せて追跡する。クエリエンジンはmanifest fileの内容を元に読み込み対象のファイルをプルーニングして、クエリ効率を向上する。Hiveテーブルとの違いとして、Icebergは統計情報をカタログではなくmanifest filesで、データファイルのサブセットに対する小さなバッチで書き込むことで統計情報の更新を軽量化する。これによって、Icebergに最新かつ正確な統計情報を持たせて、クエリ効率改善に活用できる。
data layer
ツリー構造の末端を構成するdata layerはdata files, delete files, puffin filesで構成される。これらはHDFSのような分散ファイルシステムや、Amazon S3, Azure Storage, Google Cloud Storageなどのスケーラブルなオブジェクトストレージに保管される。
data files
data filesはtableのデータそのもので、Apache Parquet, Apache ORC, and Apache Avroでの形式がサポートされている。ファイル形式は選択可能で、大規模なOLAP分析にはParquet、低レイテンシなストリーム処理にはAvroを用いる、といった使い分けが可能である。
Parquet/カラムナーフォーマットの説明は以下に詳しい。
カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜 - Retty Tech Blog
delete files
※delete filesはIceberg v2でのみサポートされる。 delete filesは、Merge on Read方式のテーブルで、データセットのどのレコードが論理的に削除された状態にあるかについての情報を提供する。delete filesには削除されたレコードをポイントする方式によってpositional delete filesとequality delete filesの2種類がある。これらはMerge on Readでテーブルの更新と削除を実行する場合にのみ使用される。
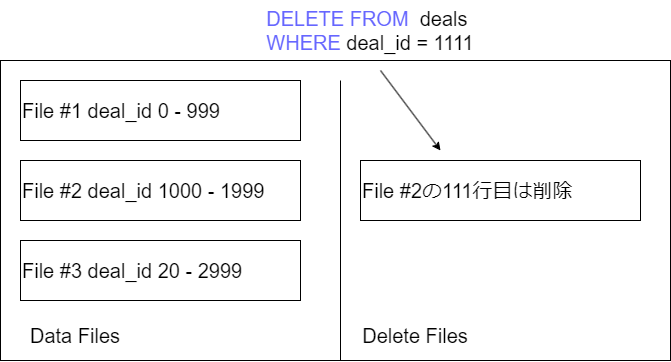
positional delete files
ファイルパスとファイル内の行番号の地点によって削除状態にあるレコードを特定する。
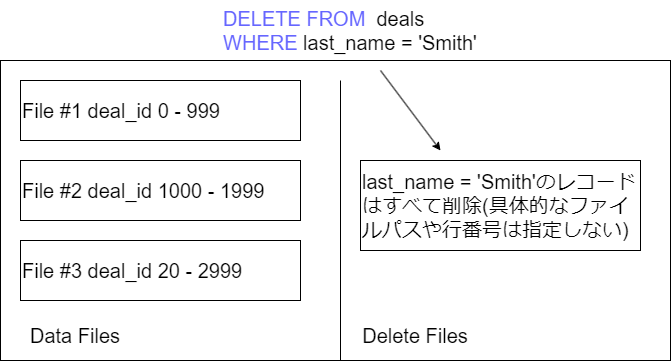
equality delete files
テーブルの特定のカラムの値で削除状態にあるレコードを特定する。ユニークではない値を示す場合は1つのequality delete filesによって複数のレコードがフィルタリング=削除される場合もある。
Puffin Files
クエリパフォーマンスの向上に使用される統計情報とインデックスのデータ。data files, metadata filesの統計情報と併せて利用される。Theta sketch がサポートされている。
テーブル操作のライフサイクル
代表的なDDLとDML実行時にIcebergがどのようにテーブルを管理しているかを観察する。ここではエンジンとしてAmazon Athena、Iceberg Catalogの保管場所としてGlue DataCatalog、Metadata Layer, Data Layerの保管場所としてAmazon S3を使用するため、使用するエンジンによっては構文が異なる可能性がある。ただし、スタックが異なっていたとしてもIceberg が管理するデータ、メタデータの変遷は同じであるはずであるため、それらを理解するうえでは問題ないはずだ。
CREATE TABLE
CREATE TABLE deals (
deal_id BIGINT,
category STRING,
deal_amount DECIMAL(10, 2),
deal_ts TIMESTAMP
)
LOCATION "s3://bering-iceberg-labo/test/"
TBLPROPERTIES ('table_type'='ICEBERG')
metadata file生成
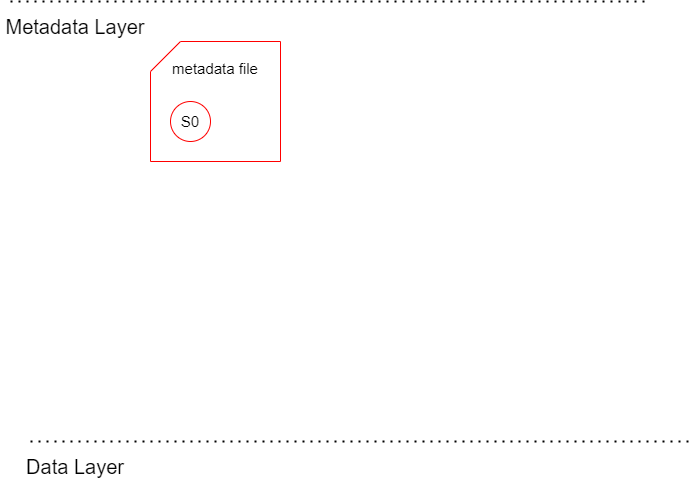
クエリエンジンがS3上にmetadata fileが作成する。
:~$ aws s3 ls s3://bering-iceberg-labo/test/metadata/ 2023-09-22 15:54:20 1233 00000-c9b34d68-e09b-48e3-9a34-5bc4d3d758dd.metadata.json
ファイルの中身は以下のようになっている(クリックして展開)
{
"format-version" : 2,
"table-uuid" : "69c64178-80ad-4a24-adec-65e8d6633390",
"location" : "s3://bering-iceberg-labo/test",
"last-sequence-number" : 0,
"last-updated-ms" : 1695365659317,
"last-column-id" : 4,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "deal_id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "category",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "deal_amount",
"required" : false,
"type" : "decimal(10, 2)"
}, {
"id" : 4,
"name" : "deal_ts",
"required" : false,
"type" : "timestamp"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"write.object-storage.enabled" : "true",
"write.object-storage.path" : "s3://bering-iceberg-labo/test/data"
},
"current-snapshot-id" : -1,
"refs" : { },
"snapshots" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
}
カラムやデータ型などのスキーマ情報が格納されていることが分かるだろう。今の時点ではスキーマを定義したのみで実際のデータは格納されていないため、snapshotsは空になっている。
Icebeg Catalogによるポイント
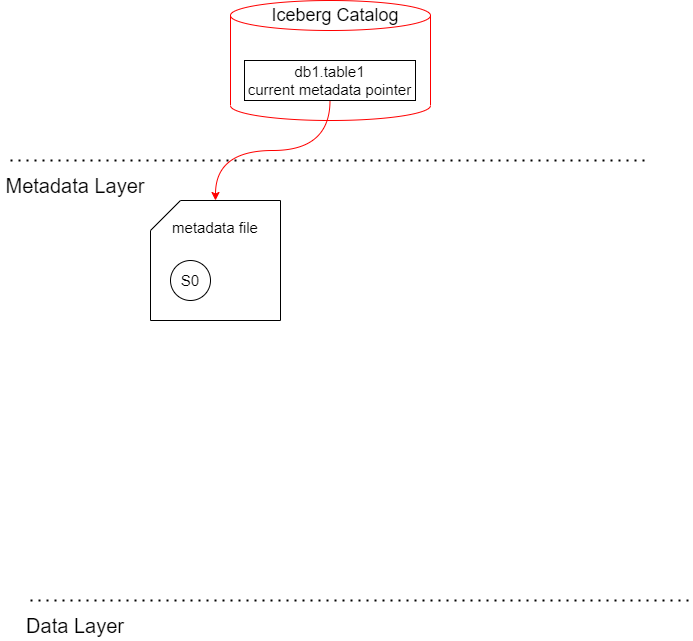
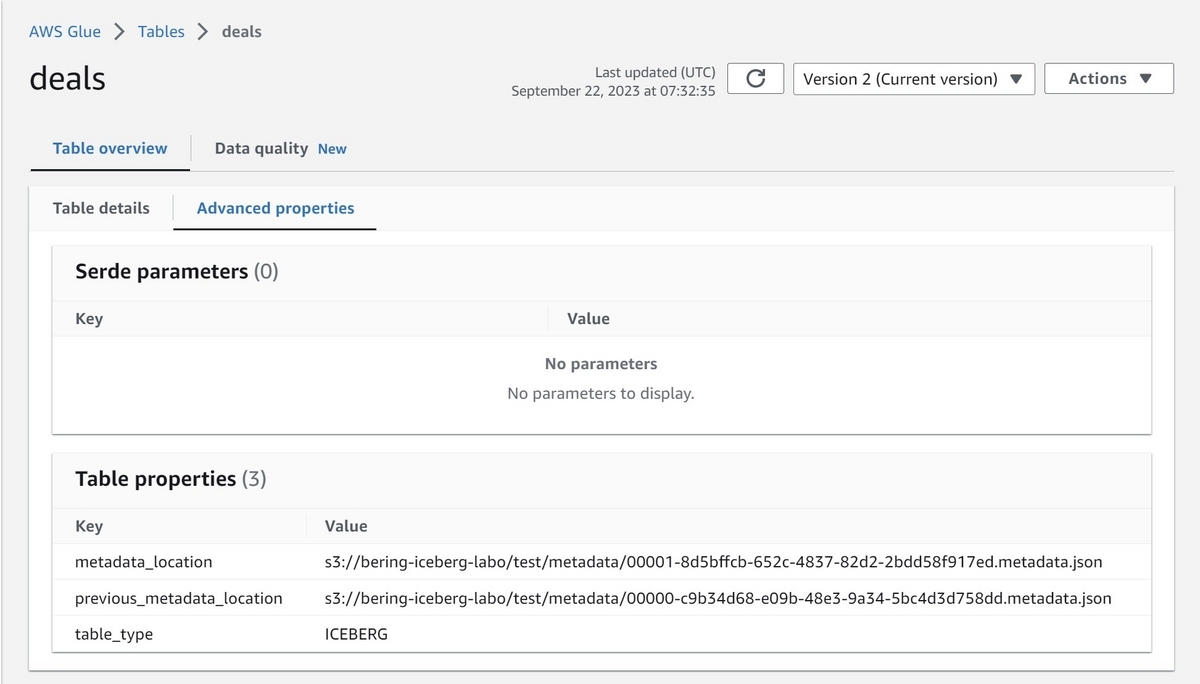
クエリエンジンがIceberg Catalogを更新して、先程のmetadata file(00000-c9b34d68-e09b-48e3-9a34-5bc4d3d758dd.metadata.json)を現在の状態としてポイントする。
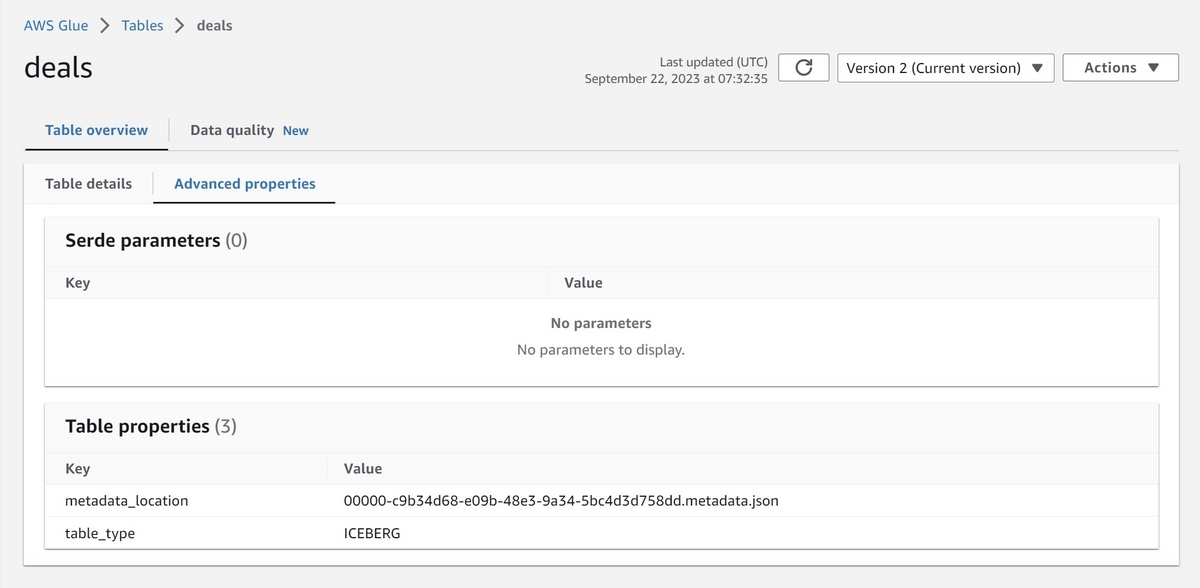
以下はGlue DataCatalogのコンソール画面で、metadata_locationプロパティに現在のmetadataとして00000-c9b34d68-e09b-48e3-9a34-5bc4d3d758dd.metadata.jsonがポイントされていることが分かる。
Insert
INSERT INTO deals VALUES ( 1000, 'fx', CAST('11.11' as DECIMAL(10,2)), CAST('2023-09-22 16:25:00' as timestamp) )
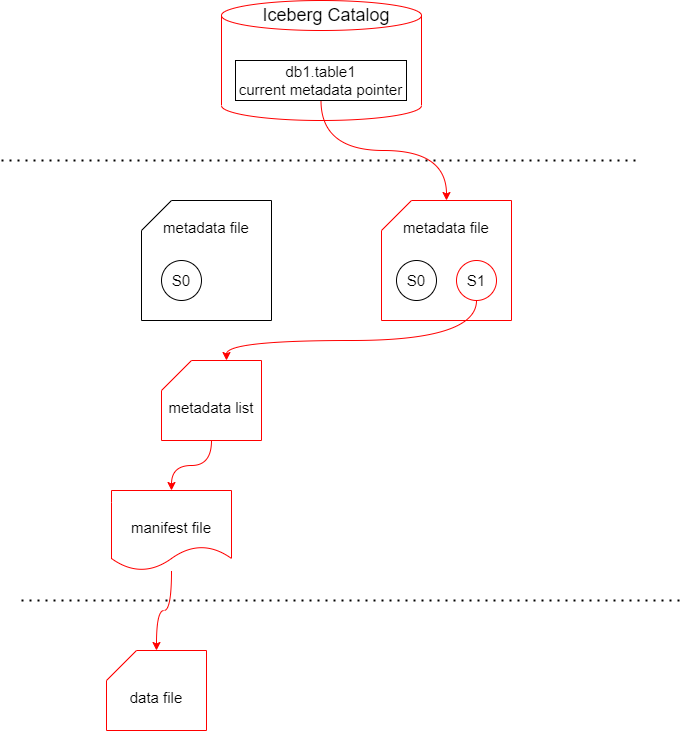
metadata fileの特定
クエリエンジンは最初にIceberg Catalogにリクエストを行い、現在のmetadata fileの場所を特定する。その後metadata fileを読み取り、現在のtable schema情報やpartitioning情報を知る。
レコードの書き込み
その後、metadata file情報に基づいてレコード情報をParquet(デフォルト)形式で書き込む。
s3://bering-iceberg-labo/test/data/fxz1hg/20230922_073230_00041_4pvqa-fce37eb0-7b90-42e5-91be-e416b0c10788.parquet
manifest fileの作成
レコードを書き込んだ後、クエリエンジンはavroでmanifest fileを作成する。manifest fileには実データが存在するファイルのパスに加えて、カラムの最大/最小値などの統計情報が保存される。
s3://bering-iceberg-labo/test/metadata/525de136-b642-41f6-a201-d583c8d0217a-m0.avro
manifest fileの例(クリックして展開)
{"status":1,"snapshot_id":{"long":2877118002610799455},"sequence_number":null,"file_sequence_number":null,"data_file":{"content":0,"file_path":"s3://bering-iceberg-labo/test/data/fxz1hg/20230922_073230_00041_4pvqa-fce37eb0-7b90-42e5-91be-e416b0c10788.parquet","file_format":"PARQUET","partition":{},"record_count":1,"file_size_in_bytes":698,"column_sizes":{"array":[{"key":1,"value":44},{"key":2,"value":42},{"key":3,"value":44},{"key":4,"value":44}]},"value_counts":{"array":[{"key":1,"value":1},{"key":2,"value":1},{"key":3,"value":1},{"key":4,"value":1}]},"null_value_counts":{"array":[{"key":1,"value":0},{"key":2,"value":0},{"key":3,"value":0},{"key":4,"value":0}]},"nan_value_counts":{"array":[]},"lower_bounds":{"array":[{"key":1,"value":"è\u0003\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"fx"},{"key":3,"value":"\u0004W"},{"key":4,"value":"\u0000¯Ê\fõ\u0005\u0006\u0000"}]},"upper_bounds":{"array":[{"key":1,"value":"è\u0003\u0000\u0000\u0000\u0000\u0000\u0000"},{"key":2,"value":"fx"},{"key":3,"value":"\u0004W"},{"key":4,"value":"\u0000¯Ê\fõ\u0005\u0006\u0000"}]},"key_metadata":null,"split_offsets":null,"equality_ids":null,"sort_order_id":{"int":0}}}
manifest listの作成
次に、manifest fileをトラックするためのmanifest listが作られる。これにはmanifest fileのロケーション、追加/削除されたレコードやファイルの数、統計情報が格納される。
s3://bering-iceberg-labo/test/metadata/snap-2877118002610799455-1-525de136-b642-41f6-a201-d583c8d0217a.avro
manifest listの例(クリックして展開)
{"manifest_path":"s3://bering-iceberg-labo/test/metadata/525de136-b642-41f6-a201-d583c8d0217a-m0.avro","manifest_length":6850,"partition_spec_id":0,"content":0,"sequence_number":1,"min_sequence_number":1,"added_snapshot_id":2877118002610799455,"added_data_files_count":1,"existing_data_files_count":0,"deleted_data_files_count":0,"added_rows_count":1,"existing_rows_count":0,"deleted_rows_count":0,"partitions":{"array":[]}}
metadata fileの作成
次に、新しいmetadata fileが作成される。新しいmetadata fileには、manifest fileのロケーション情報、スナップショットIDなどが保存される。
s3://bering-iceberg-labo/test/metadata/00002-d7f408f8-27ab-4ad1-83e5-7ef710d32412.metadata.json
metadata fileの例(クリックして展開)
{
"format-version" : 2,
"table-uuid" : "69c64178-80ad-4a24-adec-65e8d6633390",
"location" : "s3://bering-iceberg-labo/test",
"last-sequence-number" : 1,
"last-updated-ms" : 1695367955187,
"last-column-id" : 4,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "deal_id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "category",
"required" : false,
"type" : "string"
}, {
"id" : 3,
"name" : "deal_amount",
"required" : false,
"type" : "decimal(10, 2)"
}, {
"id" : 4,
"name" : "deal_ts",
"required" : false,
"type" : "timestamp"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"write.object-storage.enabled" : "true",
"write.object-storage.path" : "s3://bering-iceberg-labo/test/data"
},
"current-snapshot-id" : 2877118002610799455,
"refs" : {
"main" : {
"snapshot-id" : 2877118002610799455,
"type" : "branch"
}
},
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 2877118002610799455,
"timestamp-ms" : 1695367954467,
"summary" : {
"operation" : "append",
"trino_query_id" : "20230922_073230_00041_4pvqa",
"added-data-files" : "1",
"added-records" : "1",
"added-files-size" : "698",
"changed-partition-count" : "1",
"total-records" : "1",
"total-files-size" : "698",
"total-data-files" : "1",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "s3://bering-iceberg-labo/test/metadata/snap-2877118002610799455-1-525de136-b642-41f6-a201-d583c8d0217a.avro",
"schema-id" : 0
} ],
"statistics" : [ {
"snapshot-id" : 2877118002610799455,
"statistics-path" : "s3://bering-iceberg-labo/test/metadata/20230922_073230_00041_4pvqa-2a17c4d1-45d2-42c0-a904-d6384ebbb28f.stats",
"file-size-in-bytes" : 943,
"file-footer-size-in-bytes" : 823,
"blob-metadata" : [ {
"type" : "apache-datasketches-theta-v1",
"snapshot-id" : 2877118002610799455,
"sequence-number" : 1,
"fields" : [ 1 ],
"properties" : {
"ndv" : "1"
}
}, {
"type" : "apache-datasketches-theta-v1",
"snapshot-id" : 2877118002610799455,
"sequence-number" : 1,
"fields" : [ 2 ],
"properties" : {
"ndv" : "1"
}
}, {
"type" : "apache-datasketches-theta-v1",
"snapshot-id" : 2877118002610799455,
"sequence-number" : 1,
"fields" : [ 3 ],
"properties" : {
"ndv" : "1"
}
}, {
"type" : "apache-datasketches-theta-v1",
"snapshot-id" : 2877118002610799455,
"sequence-number" : 1,
"fields" : [ 4 ],
"properties" : {
"ndv" : "1"
}
} ]
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1695367954467,
"snapshot-id" : 2877118002610799455
} ],
"metadata-log" : [ {
"timestamp-ms" : 1695365659317,
"metadata-file" : "s3://bering-iceberg-labo/test/metadata/00000-c9b34d68-e09b-48e3-9a34-5bc4d3d758dd.metadata.json"
}, {
"timestamp-ms" : 1695367954467,
"metadata-file" : "s3://bering-iceberg-labo/test/metadata/00001-8d5bffcb-652c-4837-82d2-2bdd58f917ed.metadata.json"
} ]
}
楽観的実行制御とIceberg Tableの更新
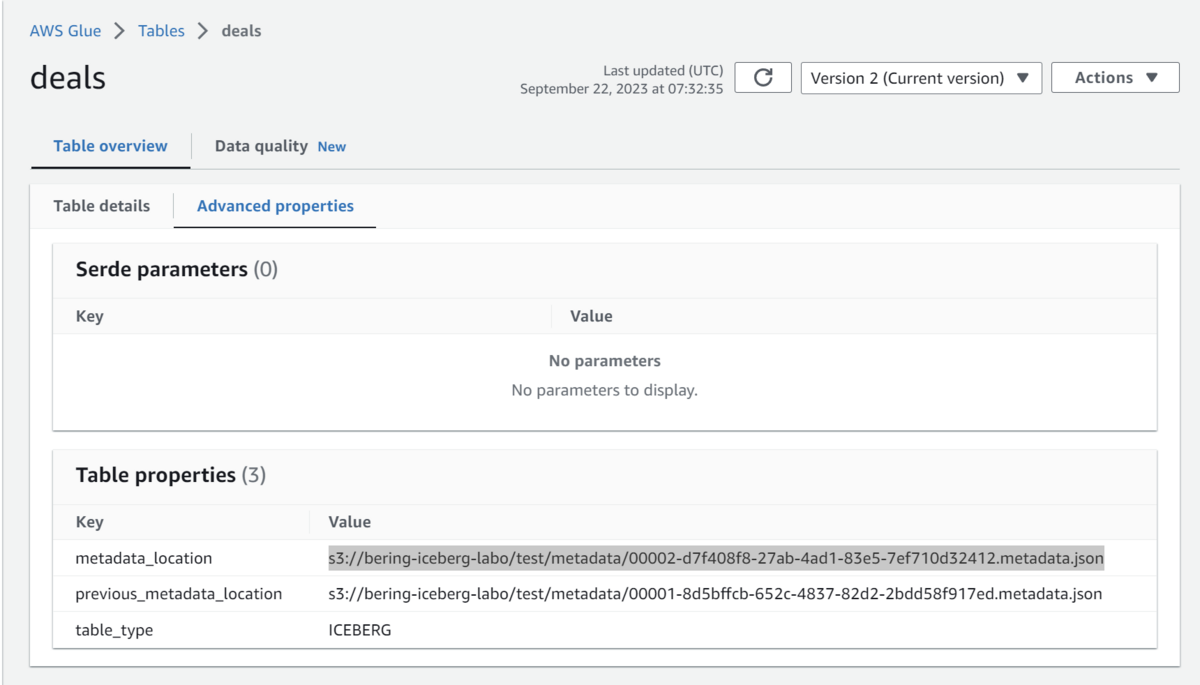
最後に、クエリエンジンはIceberg Catalogを確認して、一連のINSERT処理が始まって以降にSnapshotの断面が更新されていないことを確認して、同時書き込みによる独立性が確保されていることを保証する。確認できたら、Iceberg Tableがポイントするmetadata fileを更新する。もし自分以外のwiterによってSnapshotの断面が更新されていた場合は再試行を行う。
以下はGlue DataCatalogのコンソール画面で、metadata_locationプロパティに現在のmetadataとして00002-d7f408f8-27ab-4ad1-83e5-7ef710d32412.metadata.jsonがポイントされていることが分かる。
追加でレコードをINSERTした場合、同じ流れで新しいmeta dataとdata file(parquet)が生成される。(既存のファイルが書き換えられるわけではない)
INSERT INTO deals VALUES ( 1001, 'fx', CAST('11.11' as DECIMAL(10,2)), CAST('2023-09-23 16:25:00' as timestamp) )
:~$ aws s3 ls s3://bering-iceberg-labo/test/data/WRO7YA/ 2023-09-23 13:56:20 698 20230923_045616_00021_ardi3-b2325728-f308-4fca-9383-77feeb1641de.parquet
SELECT
SELECT *
FROM deals
WHERE deal_ts BETWEEN cast('2023-01-01' as timestamp) AND cast('2023-12-31' as timestamp)
metadata fileの特定
クエリエンジンは最初にIceberg Catalogにリクエストを行い、現在のmetadata fileを特定する。
metadata fileの参照
次にmetadata file(00002-d7f408f8-27ab-4ad1-83e5-7ef710d32412.metadata.json)を読み取り、現在のtable schema情報やpartitioning情報を把握する。
"schemas": [
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "deal_id",
"required": false,
"type": "long"
},
{
"id": 2,
"name": "category",
"required": false,
"type": "string"
},
{
"id": 3,
"name": "deal_amount",
"required": false,
"type": "decimal(10, 2)"
},
{
"id": 4,
"name": "deal_ts",
"required": false,
"type": "timestamp"
}
]
}
],
加えて、クエリエンジンはmetadata fileの"current-snapshot-id"と"snapshots"から、現在のスナップショットの断面を把握する。これによって参照すべきmanifest listを特定できる。
"current-snapshot-id": 2877118002610799455,
"snapshots": [
{
"sequence-number": 1,
"snapshot-id": 2877118002610799455,
"timestamp-ms": 1695367954467,
"summary": {
"operation": "append",
"trino_query_id": "20230922_073230_00041_4pvqa",
"added-data-files": "1",
"added-records": "1",
"added-files-size": "698",
"changed-partition-count": "1",
"total-records": "1",
"total-files-size": "698",
"total-data-files": "1",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "s3://bering-iceberg-labo/test/metadata/snap-2877118002610799455-1-525de136-b642-41f6-a201-d583c8d0217a.avro",
"schema-id": 0
}
],
manifest listの参照
クエリエンジンはmanifest listを参照して、クエリが参照するべきmanifest fileとパーティション仕様を特定する。
{"manifest_path":"s3://bering-iceberg-labo/test/metadata/525de136-b642-41f6-a201-d583c8d0217a-m0.avro","manifest_length":6850,"partition_spec_id":0,"content":0,"sequence_number":1,"min_sequence_number":1,"added_snapshot_id":2877118002610799455,"added_data_files_count":1,"existing_data_files_count":0,"deleted_data_files_count":0,"added_rows_count":1,"existing_rows_count":0,"deleted_rows_count":0,"partitions":{"array":[]}}
manifest fileの参照→datafileの参照
クエリエンジンはmanifest fileを開き、クエリが参照するべきdata file(実データ)のparquetが存在する場所を特定する。その上で、data fileを参照してデータを得る。
manifest fileの例(クリックして展開)
{
"status": 1,
"snapshot_id": {
"long": 2877118002610799455
},
"sequence_number": null,
"file_sequence_number": null,
"data_file": {
"content": 0,
"file_path": "s3://bering-iceberg-labo/test/data/fxz1hg/20230922_073230_00041_4pvqa-fce37eb0-7b90-42e5-91be-e416b0c10788.parquet",
"file_format": "PARQUET",
"partition": {},
"record_count": 1,
"file_size_in_bytes": 698,
"column_sizes": {
"array": [
{
"key": 1,
"value": 44
},
{
"key": 2,
"value": 42
},
{
"key": 3,
"value": 44
},
{
"key": 4,
"value": 44
}
]
},
"value_counts": {
"array": [
{
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
},
{
"key": 3,
"value": 1
},
{
"key": 4,
"value": 1
}
]
},
"null_value_counts": {
"array": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
},
{
"key": 4,
"value": 0
}
]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [
{
"key": 1,
"value": "è\u0003\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 2,
"value": "fx"
},
{
"key": 3,
"value": "\u0004W"
},
{
"key": 4,
"value": "\u0000¯Ê\fõ\u0005\u0006\u0000"
}
]
},
"upper_bounds": {
"array": [
{
"key": 1,
"value": "è\u0003\u0000\u0000\u0000\u0000\u0000\u0000"
},
{
"key": 2,
"value": "fx"
},
{
"key": 3,
"value": "\u0004W"
},
{
"key": 4,
"value": "\u0000¯Ê\fõ\u0005\u0006\u0000"
}
]
},
"key_metadata": null,
"split_offsets": null,
"equality_ids": null,
"sort_order_id": {
"int": 0
}
}
}
チューニングと運用上のポイント
各種Configuration
Icebergにはテーブルの振る舞いや性能面をチューニング可能な様々なConfigurationがあるため、一通りDocを眺めておくことをオススメする。
iceberg.apache.org
Copy-On-WriteとMerge-On-Read
IcebergのテーブルにはCopy-On-Write(CoW)とMerge-On-Read(MoR)の2つのモードがあり、それぞれの特性とトレードオフがある。 ※Copy-On-WriteとMerge-On-ReadはIceberg v2でのみサポートされる
Copy-On-Write(CoW)
data fileの行が1つでも更新または削除されると、data fileに変更分を反映して書き直した新しいファイルが新しいスナップショットの場所に置かれる。
CoWのテーブルは、削除されたファイルや更新されたファイルの参照が不要であるため、読み取り性能が出やすい。一方で、テーブルを更新するたびに都度データファイル全体の書き換えが発生するため、書き込み性能は出づらい。また、ごく僅かな変更であってもテーブルの全量をコピーする形になるため、データサイズが大きくなりがちである。
Merge-On-Read(MoR)
MoRではデータファイル全体を書き換える代わりに、書き込み時点では更新、削除の差分のみを追跡する。つまり、レコードを削除する場合は削除レコードを先述のdelete fileで管理して、更新する場合は古いレコードをdelete fileで管理した上で、更新されたレコードのみを含む新しいデータファイルが作成される。その上で、Readerがテーブルを読むとき、その時点までの更新差分を取り込んだ新しいファイルを作成する(=Merge on Read)。MoRでは書き込みの性能が出やすい一方で、読み取り時の負荷は高まる。これはストリームパイプラインなどでの小さなレコードを連続的に書き込む場合に有効である。
Copy-On-WriteとMerge-On-Readの設定
Icebergでは、テーブル毎、delete, update, mergeそれぞれのオペレーションについて、以下のConfigurationでCopy-On-WriteとMerge-On-Readのどちらを使用するかを指定できる。
- write.delete.distribution-mode
- write.update.distribution-mode
- write.merge.distribution-mode
不要なSnapshot, meta data, data fileの管理
Icebergでは、書き込みのたびにテーブルの新しいスナップショットが作成される。これらはTime Travelクエリなどに便利である一方で、際限なく蓄積していくとデータ、メタデータ共に肥大化していく。従って、これらのデータを適切なライフサイクルで管理していくことが重要になる。
スナップショットの「期限切れ」処理
expireSnapshotsによって、特定の時刻やスナップショットよりも古いスナップショットのメタデータとdata filesを削除できる。 当然ながら、スナップショットを削除した場合、そのスナップショットを再度参照することはできなくなるため、その点は慎重に運用設計が必要になる。
古いmetadataの削除
ストリーミングによって書き込まれるような、頻繁に更新が行われるテーブルでは、その度にメタデータファイルが作成されるため、定期的なクリーニングを検討する必要がある。Icebergはテーブルへの書き込み時に古いメタデータを削除させるライフサイクルを設定することができ、挙動をwrite.metadata.delete-after-commit.enabledとwrite.metadata.previous-versions-maxプロパティで管理できる。
write.metadata.delete-after-commit.enabled: 古いメタデータを削除するかどうかwrite.metadata.previous-versions-max: 保持する古いメタデータのバージョンの数
orphan filesの削除
orphan filesとはどのメタデータ(snapshot)にも紐づかない、孤立したdata filesのことで、タスクやジョブの失敗などによって発生する可能性がある。このようなorphan filesは[deleteOrphanFiles ](https://iceberg.apache.org/javadoc/1.3.0/org/apache/iceberg/actions/DeleteOrphanFiles.html)によって削除できる。
※orphan filesの削除対象はデフォルトでは作成から3日以上経ったものが対象となっており、設定で変更可能である。ただし、削除対象に、個々の書き込みが完了するよりも短い間隔を指定した場合、書き込み中のdata fileがorphan filesと誤認され、データが破損する恐れがあるため、慎重に設定しなければならない。
Compaction
継続的にテーブルを更新していくと、テーブルを構成するファイルが徐々に増えていくため、クエリ性能に影響を与える。そこで、テーブルを構成するファイルを統合して最適化することをCompactionという。 具体的なCompactionオペレーションのコマンドやサポートされる方式はエンジンによって異なるため、IcebergのDocに纏められている、各エンジンの解説を確認して欲しい。
エンドユーザが都度手動でCompactionオペレーションを行うのは恐らく現実的ではないので、Compaction作業を自動化することがポイントになる。具体的には、データ取り込み処理の終了後や、一定周期等でAirflowなどのオーケストレーションを用いてCompaction処理を実行させる運用を検討する。
オブジェクトストレージ上でのprefix分散
データレイク/Icebergのテーブルをオブジェクトストレージに配置する場合の考慮点として、同一prefixに対するリクエスト数のクウォータを意識する必要がある。例えばAmazon S3では、同一プレフィックスに対して1秒あたり5,500 回以上の GET/HEAD リクエストがスロットリングされる。Apache Icebergは物理的なファイルと論理的なテーブルが分離されているため、プレフィックスを分散して書き込むことで性能を最適化出来る。具体的にはテーブルのプロパティとしてwrite.object-storage.enabledをtrueに設定することで、プレフィックスを分散した書き込みが実現する。
write.object-storage.enabled=falseの場合
s3://bucket/table/column=hoge/file1.parquet s3://bucket/table/column=hoge/file2.parquet s3://bucket/table/column=hoge/file3.parquet s3://bucket/table/column=moge/file4.parquet s3://bucket/table/column=moge/file5.parquet s3://bucket/table/column=moge/file6.parquet
write.object-storage.enabled=trueの場合(prefixの値は適当)
s3://bucket/441232/table/column=hoge/file1.parquet s3://bucket/221332/table/column=hoge/file2.parquet s3://bucket/312123/table/column=hoge/file3.parquet s3://bucket/233232/table/column=moge/file4.parquet s3://bucket/443423/table/column=moge/file5.parquet s3://bucket/323423/table/column=moge/file6.parquet
さいごに
本エントリでは、Apache Icebergの基本的な仕組みや考え方を解説した。実際にはまだまだカバーできていないトピックがあるので、随時更新していきたい。また次回は、エンジンごとのIcebergサポート状況の調査や、より個別の仕組みにフォーカスした調査記事をまとめていきたい。
参考
Apache Iceberg - Apache Iceberg
Apache Iceberg: The Definitive Guide [Book]
Comparison of Data Lake Table Formats | Dremio Blog
Lakehouse Strategies: Copy-on-Write vs. Merge-on-Read
Data lake Table Formats — Hudi vs Iceberg vs Delta Lake | by Dinesh Shankar | Medium