J.P.Morgan Asset ManagementのAWS re:Invent 2023での登壇「One data platform for reporting, analytics, and ML」の視聴メモ
エントリ内の情報や図版は特に断りがない限り、youtube上の当該発表を基にしている
概要
J.P.Morgan Asset Management
- J.P.Morgan Asset Managementは世界最大級の金融機関であるJ.P.Morgan Chaseのアセットマネジメント事業を担っており、世界最大級の資産運用会社
- 運用規模は2.9兆ドル
- 機関投資家、リテールの仲介業者、資産家など世界中に顧客がいる
- 「Data and our culture around data are critical for our business」
AM IQ
- データ分析とMLを統合したプラットフォーム
- 社内外の様々なソースから様々な構造のデータを収集し、クレンジングし、正規化し、モデル化し、利用するための一連の機能を提供する
- 全体で5PB規模で、毎日数億レコードがingestされ、数十億レコードが生成され、600以上のアプリケーション、ダッシュボード、レポートにフィードされる
- 元々、J.P.Morgan Asset Management社内には用途やユーザごとに様々なプラットフォームが乱立しており、データのやり取りなどが非効率であったため新しい基盤を作ろうとなった
- We needed a platform that can let us insert data super fast into the platform, transport it, transform it, and also ultra fast on extracting data.
- 営業とマーケティング向けに構築され、その後組織全体の他のユーザ向けに拡大された
- 事業に関わるすべての人がAM IQに支えられながら仕事をしている
- 例えば営業は、顧客との関係を築き、顧客をカバーし、顧客に代わって投資する。そのため顧客の情報を調べたり、日々の売上を見たり、アジェンダの準備をしたり、日々の電話を準備したり、新しい機会を見つけたり、リスクを管理したりといった目的でデータを利用する
- 例えばマーケティングチームは、リードナーチャリングや、マーケーティングのROIを分析したり、市場の分析や顧客ごとにパーソナライズしたコンテンツの作成などにデータを利用する (*マーケーティングの世界では、潜在顧客を見込み客(リード)に育てる活動をリードナーチャリングというらしい)
- 例えば顧客は、ポートフォリオの確認や、投資機会の発見、リスク管理などにデータを利用する
- 従って、組織全体のすべての人が一貫したプラットフォームを通じてデータを利用できる必要があった
- すべてのクラウドサービスを利用できるわけではない:JPMCはアメリカの世帯の半分にサービスを提供しており、30万人の従業員を擁する非常に社会的責任の大きい企業であり、かつ規制の厳しい金融業界の企業であるため、利用できるサービスや機能に制約があるため、それと折合いを付けながら作った(この辺りは日本も海外もあまり変わらない)
AM IQを支える組織
約60人のエンジニアリングチームで開発、運用しており、インフラやツールを管理する「Core Engineer」、データの収集、整理、最適化などデータを準備すると共に、ビジネス部門と密接に協力してデータの解釈を手助けする「Data Engineer」、データからインサイトを導き、アルゴリズムやモデルを開発する「Data Scientist」、データをユーザやクライアント端末に届けるためのアプリケーション開発を行う「application developer」で構成される。
AM IQの活用例
営業先レコメンドエンジン
営業担当者が最適なタイミングで最適な製品やソリューションを顧客に提案できるように、提案先のレコメンデーションリストを毎朝提供する。
このツールが導入される以前、営業担当者は毎朝数時間かけて様々なレポートや顧客状況、市場データに目を通し、手作業で整理してその日の営業計画を立てていた。このツールによって、より効率的に、より多くの時間を顧客と過ごすことができている。
レコメンドエンジンの入力としてはニュース、市場データ、製品ごとのパフォーマンスなどの様々なデータが用いられており、これらからシグナルを生成する。シグナルにはクライアントの好みはなにか、クライアントの行動は何かといったシンプルなものから、協調フィルタリング、パターン認識、統計分析、センチメント分析など複雑なものまで様々なものがあり、これらが重み付けされ、リストに統合されることで営業担当者向けのレコメンドリストが完成する。
営業担当者はリストに対してリアルタイムでフィードバックを提供することができ、レコメンドエンジンの継続的な改善に役立てられている。
AM IQのアーキテクチャ
全体像
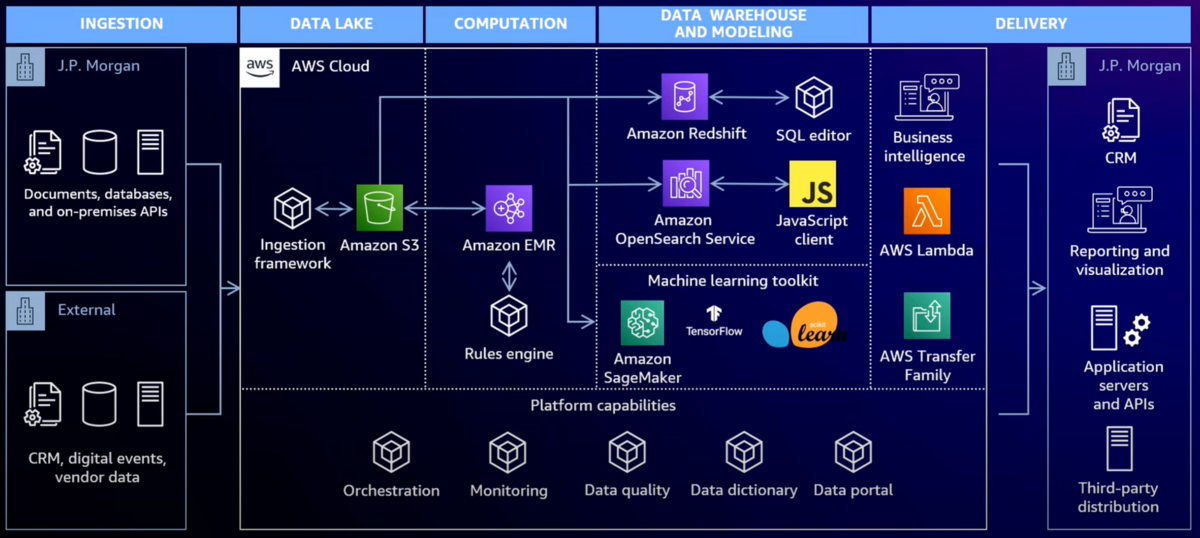
クラウド上のコンポーネントのうち、色のついていない箱は内製したもの。内製の理由は、クラウドサービスのネイティブな機能の枠を越える要件があったのと、既存の社内システムや運用との統合を図る必要があったため。
Data Ingestion
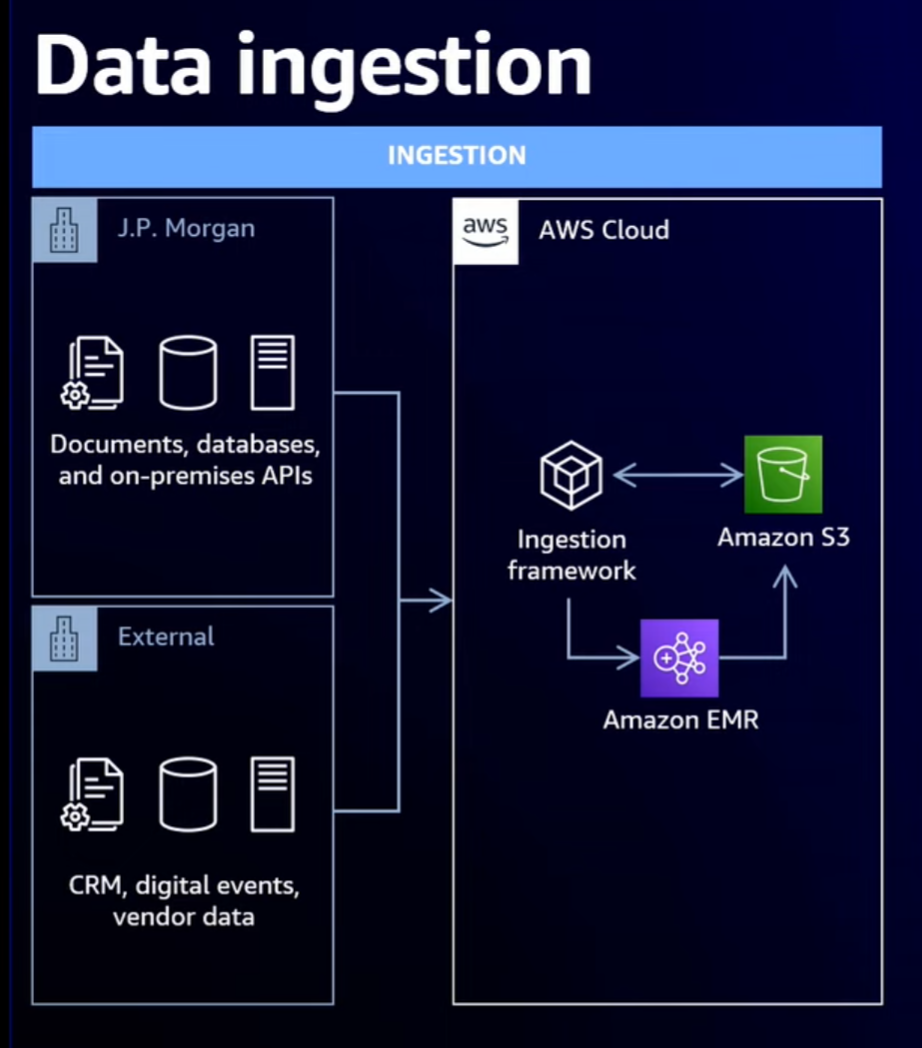
- ソースデータとして多様なファイル形式をサポートしており、CSVやExcelに加えて、COBOLやバイナリなどの難解なものもサポートしている。これらは取り込み時にParquetに変換される
- 社内外にデータソースがあり、API経由でアクセスできるものもあれば、ファイルとして送られてくるものもある。また、特に外部のデータソースについて、認証メカニズムやファイアウォールを考慮する必要がある
- 上記の多様なデータソースの操作と、データソースアクセスの複雑性の両面を抽象化するため、データエンジニアがローコードでデータ取り込みJobを開発可能なインジェスト・フレームワークを開発した
- PySparkベースのパイプラインでそれぞれのデータの変更履歴を追えるようにしている
- データの履歴は規制要件への対応や、MLモデルのトレーニング、業務効率化などに使用される

- データの正規化や品質管理に関して様々な工夫をしている
- 空白文字の削除、空白文字の取引、特殊文字の削除などの自動化
- MLによるデータ型の自動予測
- MLによるデータの異常検知
- 余計なprefixの削除(ここ何を意味しているのか分からなかった....)
Data Transformation
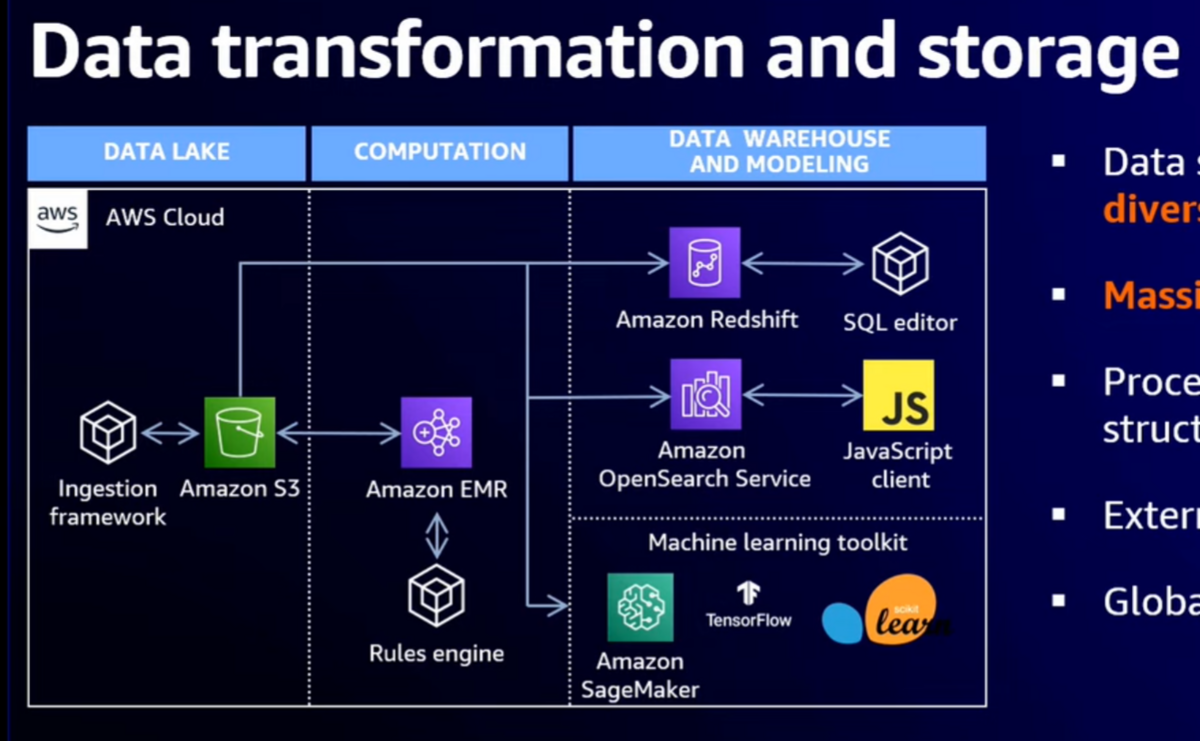
- EMRで処理したデータはS3に蓄積され、Redshift, OpenSearch, SageMakerから参照される
- これらは何れもS3を軸としているため、コンポーネント間のデータ連携が円滑である利点があった
- また、データへの変更を常にS3に対して実施するようにしたことで、一貫性の問題に対処するとともに、コスト効率を最適化できた
- Redshift, OpenSearch, SageMakerをサポートすることで、様々なデータアクセスのユースケースを幅広くカバーできている
- EMRで数千のJobを実行する中で、数%の故障は常に発生する。これらに対応するため、リトライ実装を工夫したり、サーバ障害を自動検知してクラスタを自動リサイズするような工夫を各所に取り入れている
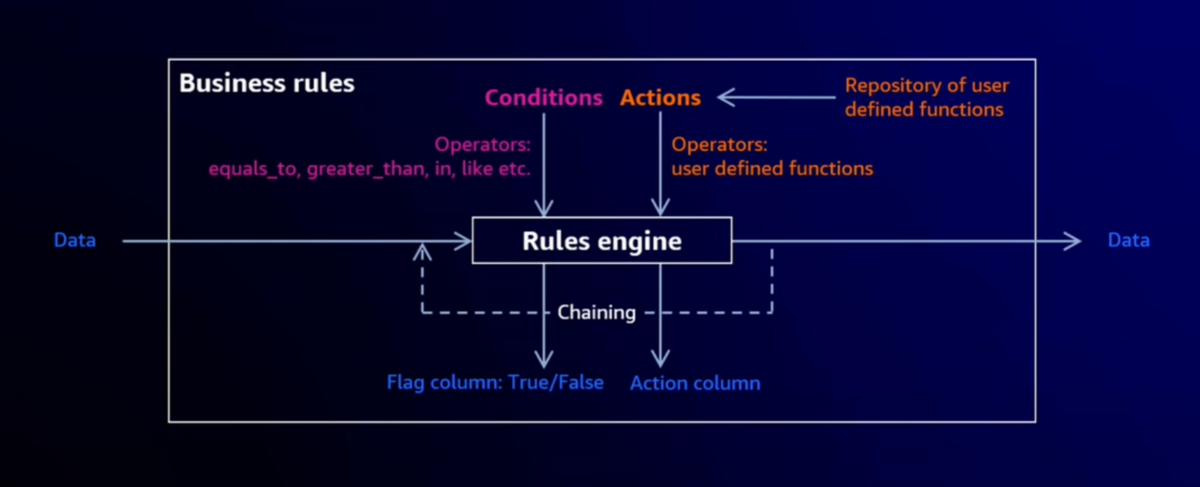
- OSSをベースに、普遍的に需要があるデータ変換を設定やUIで指定し、パイプライン実行できる仕組みを作った。これによってリリースサイクルを経ることなく、データエンジニアやビジネスユーザがパイプラインを構築、実行できるようになった(ここ具体的にどのようなルールエンジンなのか分からなかった)
Data distribution and sharing
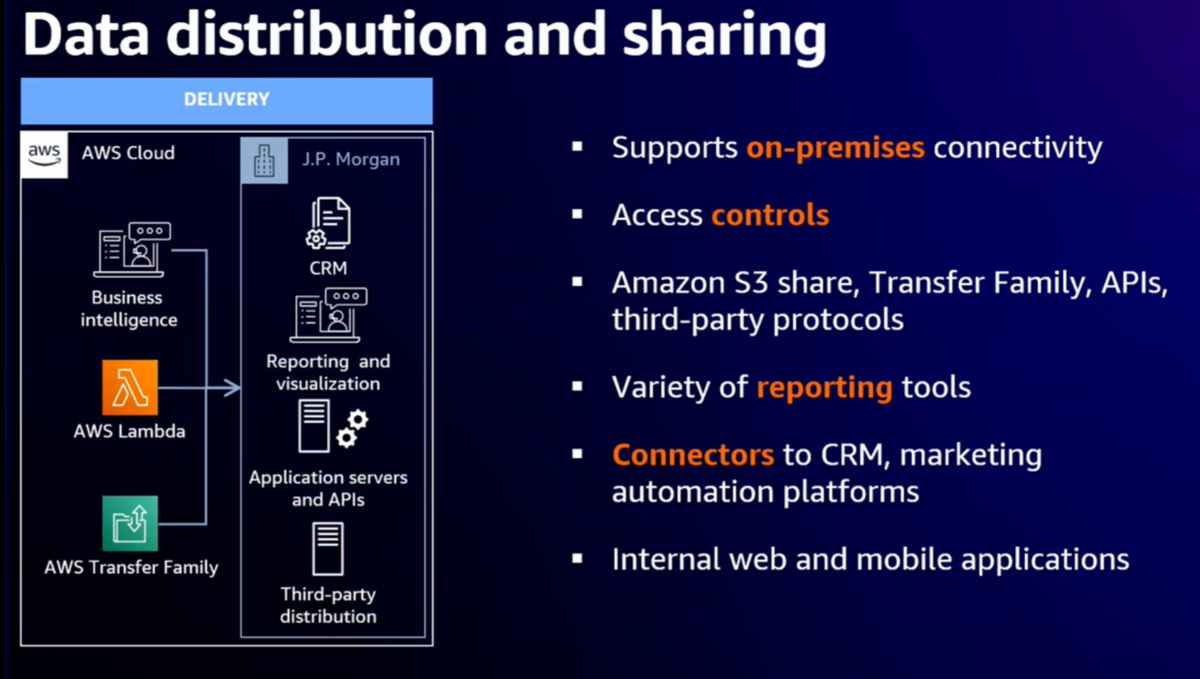
- レポーティングツールはRedshiftに接続し、モバイルアプリ、ウェブアプリはOpenSearchに接続している
- S3やTransfer Familyを介してファイルベースでのデータ送信もできるようになっている
プラットフォームの社内向け展開

JP Morgan Chaseは巨大な企業グループなので、似たようなことをやりたいチームは他にも存在している。そこで、これらの基盤をIaCに固め、独自のフレームワーク群をバンドルして社内向けに配布している。これによって、何処の部署でも簡単に同じプラットフォームを構築することができ、例えば富裕層を顧客とするプライベート・バンク部門などで利用されている。