datatech-jpで開催中のFundamentals of Data Engineering (English Edition)読書会に向けた、「Chapter 11.The Future of Data Engineering」のまとめ。
以下は基本的には本文の要約であり、★マークがついている部分は私のコメントや付加情報である。
全体のあとがき/エピローグ的なChapter
データエンジニアリングの未来への洞察が語られる(同書が刊行されたのは2022年6月22日)
- Introduction
- データエンジニアリングのライフサイクルはなくならないだろう
- 複雑性は低下し使いやすいデータツールが台頭するだろう
- クラウドスケールのデータOSと相互運用性が進展するだろう
- データエンジニアリングは「エンタープライズ的」になるだろう
- 肩書きと責任は変化していくだろう
- Modern Data Stackを超えて、Live Data Stackへ向かうだろう
- Conclusion
Introduction
- 本書は、データエンジニアリングの変化が速いため、人々の知識が追いついていない事への課題認識から生まれた(既存のデータエンジニア、データエンジニアリングのキャリアに興味がある人、技術管理者、データエンジニアリングが自社にどのようにフィットするかをよりよく理解したい経営者)
- データ・エンジニアリングは日々変化している
- 私たちは、テクノロジーが疲れるほどのスピードで変化し続けていることを痛感している
- 数年前には、データ・エンジニアリングという分野や職種すら存在しなかった
- 本書の構成について考え始めたとき、筆者は友人たちから「これほど急速に変化している分野についてよくも書けるものだ!」という反発を受けた
- そこで本書では、今後数年間役に立つと思われる大きなアイデアに焦点を当て、データエンジニアリングのライフサイクルの連続性とその底流を紹介した
- 誰も未来を予知することはできないが、筆者は過去、現在、そして現在のトレンドについて優れた視点を持っている
- この最終章では、現在進行中の開発に関する考察や荒唐無稽な将来の推測を含め、将来についての筆者の考えを紹介する
データエンジニアリングのライフサイクルはなくならないだろう
- データサイエンスが注目されている一方で、データエンジニアリングは急速に台頭し、成熟しつつある
- 進歩の中心は、データエンジニアリングのライフサイクルにある
複雑性は低下し使いやすいデータツールが台頭するだろう
- シンプルで使いやすいツールは、データエンジニアリングへの参入障壁を下げ続けている
- データエンジニアの不足を考えると、これは素晴らしいこと
- 簡素化の傾向は今後も続く
- データエンジニアリングは特定の技術やデータサイズに依存するものではないし、大企業だけのものでもない
- ビッグデータ技術は、SaaS型マネージド・サービスの並外れた成功の犠牲者(Big data is a victim of its extraordinary success.)
- クラウドは、OSSの利用に大きな変化をもたらしている
- 2010年代初頭でさえ、OSSを使用するには、コードをダウンロードして自分でデプロイするのが一般的だった
- 現在では、多くのOSSデータツールが、プロプライエタリなサービスと直接競合するマネージドクラウドサービスとして提供されている
- Linuxは、すべての主要なクラウドのサーバーインスタンスにあらかじめ設定され、インストールされている
- AWS LambdaやGoogle Cloud Functionsのようなサーバーレス・プラットフォームでは、Python、Java、Goのような言語を使用して、イベント駆動型のアプリケーションを数分でデプロイできる
- Apache Airflowを使用したいエンジニアは、GoogleのCloud ComposerまたはAWSのマネージドAirflowサービスを採用できる
- マネージドKubernetesを使えば、拡張性の高いマイクロサービス・アーキテクチャを構築できる
- ★ただし、マネージドサービスの土台となっている技術への理解は依然として重要だと思う。Airflowにしても、Sparkにしても、仕組みを理解していなければ正しく開発、運用するのは難しい。OSSを土台としないSnowflakeなどの製品でも同じ
- 多くの場合、マネージドなOSSは、プロプライエタリ・サービスの競合と同じくらい使いやすい
- 高度に専門化されたニーズを持つ企業は、マネージドなOSSを導入し、基礎となるコードをカスタマイズする必要があれば、後でセルフマネージドなOSSに移行することもできる
- ★見方を変えると、必要になった時に適宜カスタイマイズができるケイパビリティがあることが差別化のポイントになるのではという気もする。マネージド / セルフマネージドのゼロイチではなく、カスタムモジュールを導入出来る製品も多い
- ★どこまでデータ基盤/技術を抽象化して扱うかは深遠な議論だと思う。本質的なビジネスに関わる領域に集中する観点でクラウドプロバイダのマネージドなソリューションを使い倒すのは良いことではある。一方で、Uber,Twitter,RiotGamesやJPMC, Nasdaq,Netflix,Meta等々の取り組みを見ていると、既存のソリューションの限界を自社オリジナルの技術で突破することで高度な問題を解決し、更にはそれらの技術がOSSとして業界の次のスタンダードになっていたりもする。鍵は背景となるビジネスのスケールだろうか
- もう一つの大きなトレンドとして、既製品のデータ・コネクタの人気が高まっている(執筆時点では、FivetranやAirbyteなどが人気)
- データツールの分野で競争が激化し、データエンジニアの数が増加しているため、データツールの複雑さは減少し続ける一方で、さらに多くの機能と特徴が追加されていく
- より多くの企業がデータに価値を見出す機会を見出す中、このような単純化はデータエンジニアリングの実践を成長させる
クラウドスケールのデータOSと相互運用性が進展するだろう
- 原文は「The Cloud-Scale Data OS and Improved Interoperability」
- クラウドネイティブなデータODという概念の進化の次のフロンティアは、より抽象度の高いレベルで起こるだろう
- ★Benn Stancilによれば、The data OSとは、データソース、ツールの差分を吸収して、相違を解決するレイヤーを指す概念。パソコンや携帯電話のハードウェアがOSによって抽象化されていることになぞらえて「Data OS」と呼んでいる
★Bennは「Data OS」を実現し得る仕組みとしてdbtを挙げている
To extend the OS analogy, in this world, dbt is Android; the data is my phone’s hardware. dbt exposes the state of that hardware—schema information, the lineage of its tables, the latency of the data within them—to everything that uses it. Just as Android abstracts away the peculiarities of each device it runs on, dbt sands down the differences between BigQuery, Redshift, and others, providing a single language for interacting with all of them. Similar to how Android links apps together, dbt serves as a communications bus that, for example, pushes queries between a “production” environment in Census and a “development” environment in Mode. In the same way that mobile operating systems provide developers easy access to phones’ physical capabilities, dbt offers its own helper functions and syntactic sugar (e.g., what dbt enables with Jinja8) that shortcut and standardize common interactions with data.
Extend these ideas far enough, and entire apps could live inside dbt, doing everything from running on-the-fly tests against in incoming queries to finding and merging duplicative datasets across every tool and database in the stack. The data OSより
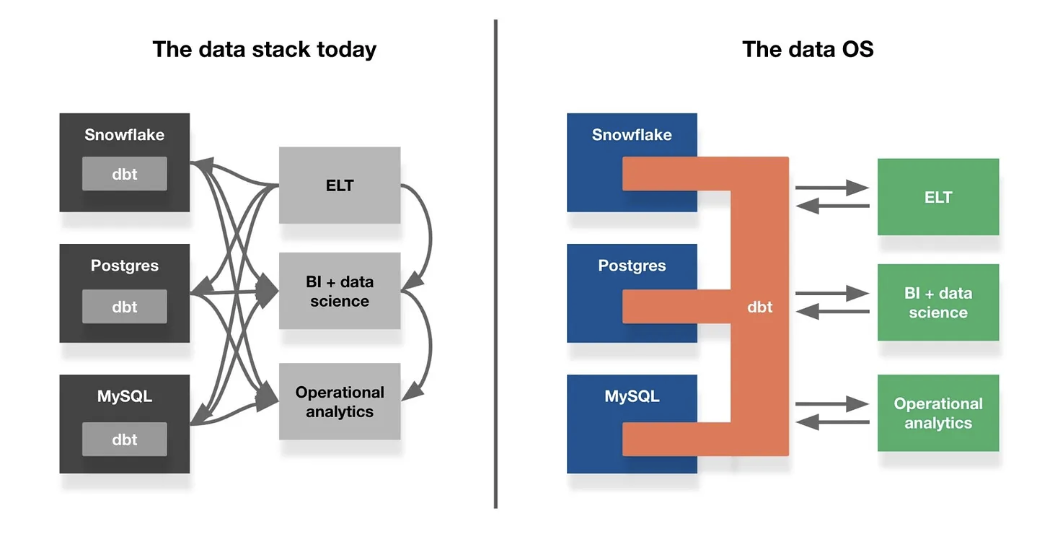
- 身近なOSのたとえ
- あらゆるデバイス(スマートフォン、ノートパソコン、アプリケーション・サーバー、スマート・サーモスタット等)は必要不可欠なサービスを提供し、タスクやプロセスをオーケストレーションするOSに依存している
- アプリケーションプロセスがサウンドやグラフィックスのハードウェアに直接アクセスすることはない
- オペレーティング・システムのサービスにコマンドを送り、ウィンドウを描いたり、サウンドを再生したりする
- これらのコマンドは、標準的なAPIに対して発行される。仕様書は、オペレーティングシステムのサービスとどのように通信するかをソフトウェア開発者に指示する
- OSはこれらのサービスを提供するためにブート・プロセスを編成し、各サービス間の依存関係に基づいて正しい順序で各サービスを開始する
- OSがサービスを監視して維持し、障害が発生した場合は正しい順序でサービスを再起動する
- データエンジニアリングはデータ相互運用性の標準を中心にまとまっていくだろう
- データAPIエコシステムのもう一つの重要な要素は、スキーマとデータ階層を記述するメタデータカタログ
- メタデータは、アプリケーションやシステム間、クラウドやネットワーク間のデータ相互運用性において重要な役割を果たし、自動化と簡素化を促進する
- 現在、この役割はレガシーなHive Metastoreによってほぼ満たされている
- 私たちは、この役割を担う新規参入者が現れることを期待している
- ★もしかしてOpen Table Formatの話か????: データレイクの新しいカタチ:Open Table Formatの紹介
- クラウド上のデータサービス群を管理する足場としてのデータ・オーケストレーション・プラットフォームも大幅に改善されるだろう
- Apache Airflowは、最初の真にクラウド指向のデータ・オーケストレーション・プラットフォームとして登場し、大幅な機能強化の入り口に立っている
- Airflowは、その巨大なマインドシェアを基盤に、機能を拡大していくだろう
- DagsterやPrefectのような新規参入企業は、オーケストレーション・アーキテクチャを一から再構築することで対抗するだろう
- 次世代のオーケストレーションプラットフォームでは、データ統合(data integration)とデータ認識(data awareness)が強化される
- オーケストレーション・プラットフォームはデータカタログやリネージと統合され、その過程でデータ認識(data awareness)が大幅に向上する
- オーケストレーション・プラットフォームは、(Terraformに似た)IaC機能と(GitHub ActionsやJenkinsのような)コード・デプロイ機能を構築するだろう
- エンジニアはパイプラインをコーディングし、それをオーケストレーション・プラットフォームに渡すことで、自動的にビルド、テスト、デプロイ、モニタリングができるようになる
- エンジニアはインフラの仕様をパイプラインに直接書き込むことができるようになり、足りないインフラやサービス(Snowflakeデータベース、Databricksクラスタ、Amazon Kinesisストリームなど)はパイプラインの初回実行時にデプロイされる
- 例えば、ストリーミング・パイプラインや、ストリーミング・データの取り込みとクエリが可能なデータベースなど
- ★2024/2現在、インフラレイヤも含めた包括的なデータ基盤のIaCはツール面でも実践面でも発展途上であるように思う
- ★JPMCが部分的にそれらしいことやっていたな:J.P.Morgan Asset Managementのデータ分析 / MLプラットフォーム「AM IQ」についてのメモ
- 過去において、ストリーミングDAGの構築は、継続的な運用負担が大きい非常に複雑なプロセスであった(第8章参照)
- Apache Airflowは、最初の真にクラウド指向のデータ・オーケストレーション・プラットフォームとして登場し、大幅な機能強化の入り口に立っている
- データ・エンジニアにとって、これらの抽象化の強化は何を意味するか?
データエンジニアリングは「エンタープライズ的」になるだろう
- データツールの簡素化とベストプラクティスの出現と文書化は、データエンジニアリングがより "エンタープライズ的 "になることを意味する
- ★3 Data Engineering Experts Share Their Thoughts on Where Data Is Headed(medium有料記事)によれば、Ternary Data社CEOのJoseph Reisが「Data engineering is becoming more “enterprisey.”」と言っている
- エンタープライズという言葉から、糊のきいた青いシャツとカーキパンツに身を包んだ顔の見えない委員会、果てしないお役所仕事、常にスケジュールが遅れ予算が膨れ上がるウォーターフォール管理型の開発プロジェクトといったカフカ的な悪夢を思い浮かべる人もいるだろう
- イノベーションが死滅するような魂のない場所を想像する人もいるかもしれない
- 私たちが話しているのはこのようなことではなく、大企業が行っているようなデータ管理、オペレーション、ガバナンスなどの「退屈だが重要なこと」に取り組みやすくなっているということだ
- 私たちは今、「エンタープライズ向け」データ管理ツールの黄金時代を生きている
肩書きと責任は変化していくだろう
- データエンジニアリングのライフサイクルがすぐになくなることはないが、ソフトウェアエンジニアリング、データエンジニアリング、データサイエンス、MLエンジニアリングの境界はますます曖昧になっていく
- (筆者を含めて)多くのデータサイエンティストは、有機的なプロセスを経てデータエンジニアへと変貌を遂げる。「データサイエンス」を行うことを任務としながらも、仕事を行うためのツールが不足しているため、データエンジニアリングライフサイクルに対応するシステムの設計と構築の仕事を引き受けるのだ
- 抽象化が進むにつれて、データ・サイエンティストはデータの収集と加工に費やす時間が減っていくだろう
- データエンジニアリングライフサイクルの低レベルのタスク(サーバーの管理、設定など)に費やす時間が減ることを意味し、「エンタープライズ的な」データエンジニアリングがより普及するだろう
- この傾向はデータサイエンティストにとどまらない
- データがあらゆるビジネスのプロセスに密接に組み込まれるようになると、データとアルゴリズムの領域で新たな役割が生まれるだろう
- 一つの可能性は、MLエンジニアリングとデータエンジニアリングの中間に位置する役割だ
- クラウドのマネージドなMLサービスのり弁性が高まるにつれて、MLはアドホックな探索やモデル開発から運用のディシプリンへとシフトしつつある
- ★業務システム/サービスの開発部署、データ分析(基盤)部署、ML(基盤)部署がサイロ化していて、各々は優れたケイパビリティを持っているのに有機的に価値を出せていない勿体ない状況をよく観測する。。一方でデータの利活用で目覚ましい成果を挙げている企業はそれらが有機的に統合されてるように見えていて、それを実現する組織や技術、プロセスを探求したい
- この溝をまたぐMLにフォーカスする新しいエンジニアは、アルゴリズム、ML技術、モデル最適化、モデルモニタリング、データモニタリングに精通する
- 彼らの主な役割は、モデルを自動的に訓練し、パフォーマンスを監視し、よく理解されているモデルタイプについてMLプロセスを完全に運用するシステムを作成または利用することになる
- また、データパイプラインや品質の監視も行うようになり、現在のデータエンジニアリングの領域と重なる
- MLエンジニアは、より研究に近く、あまり理解されていないモデルタイプに取り組むため、より専門的になるだろう(ML engineers will become more specialized to work on model types that are closer to research and less well understood.)
- ★この一文イマイチ言いたいことが分からなかった。より高度なことをやるようになるよって意味なのかな
- ソフトウェアエンジニアリングとデータエンジニアリングが交差する分野も、肩書きが変化する可能性がある
- 従来のソフトウェア・アプリケーションとアナリティクスを融合させたデータ・アプリケーションは、このトレンドを牽引するだろう
- ソフトウェア・エンジニアは、データ工学をより深く理解する必要があるだろう
- ストリーミング、データ・パイプライン、データ・モデリング、データ品質などの専門知識を身につけることになる
- 私たちは、現在普及している「壁越しに放り投げる」アプローチから脱却することになるだろう
- データエンジニアはアプリケーション開発チームに統合され、ソフトウェア開発者はデータエンジニアリングスキルを習得する
- アプリケーションのバックエンドシステムとデータエンジニアリングツールの間に存在する境界線も低くなり、ストリーミングやイベント駆動型アーキテクチャによる深い統合が実現するだろう
Modern Data Stackを超えて、Live Data Stackへ向かうだろう
- 率直に言うと、モダン・データ・スタック(MDS)はそれほどモダンではない
- モダン・データ・スタックが強力なデータツールの品揃えを大衆に提供し、価格を引き下げ、データアナリストがデータスタックをコントロールできるようにしたことには拍手を送りたい
- とはいえ、モダン・データ・スタックは基本的に、古いデータウェアハウスのやり方を最新のクラウドやSaaSの技術を使って再パッケージ化したものだ
- 世界はデータウェアハウスをベースとした内部向けの分析やデータサイエンスの利用を超え、次世代リアルタイム・データベースを用いてビジネス全体やアプリケーションをリアルタイムで強化する方向に進んでいる
- 何がこの進化を後押ししているのだろうか?
- 多くの場合、アナリティクス(BIとオペレーション・アナリティクス)は自動化に取って代わられるだろう
- 現在、ほとんどのダッシュボードやレポートは、いつ、何をするのかという質問に答えている
- 自問自答してみよう。"いつ、何を質問している場合、次にどのようなアクションを取ればいいのか?"と
- もしその行動が反復的であれば、それは自動化の候補である
- 発生したイベントに基づいてアクションを自動化できるのに、なぜレポートを見てアクションを起こすかどうかを判断するのか?
- ただ、それはこれよりもずっと先のことだ
- ★LLMやAgentの進化によって加速していきそうな気もする
- TikTok、Uber、Google、DoorDashのような製品を使うと、なぜ魔法のように感じるのだろうか?
- 短いビデオを見たり、乗り物や食事を注文したり、検索結果を見つけたりするのは、ボタンをクリックするだけのように見えるが、その裏では多くのことが起こっている
- これらの製品は真のリアルタイム・データ・アプリケーションの一例であり、ボタンをクリックするだけで必要なアクションを提供する一方で、裏では極めて高度なデータ処理とMLを極小のレイテンシーで実行している
- 現在、このレベルの洗練されたテクノロジーは、大手テクノロジー企業のカスタムメイドのテクノロジーに囲い込まれているが、モダンデータスタックがクラウドスケールのデータウェアハウスとパイプラインを大衆に提供したのと同様に、この洗練さとパワーは民主化されつつある
- ★国際的な超巨大企業が内製しているようなテクノロジーが広まっていくというわけか
- データの世界はまもなく "ライブ "になる
The Live Data Stack
- リアルタイム・テクノロジーの民主化は、モダン・データ・スタックの後継となるライブ・データ・スタックへのアクセスを可能にし、普及させる
- 図11-1に示すライブ・データ・スタックは、アプリケーション・ソース・システムからデータ処理、ML、そしてその逆までのデータ・ライフサイクル全体をカバーするストリーミング・テクノロジーを使用することで、リアルタイム分析とMLをアプリケーションに融合する
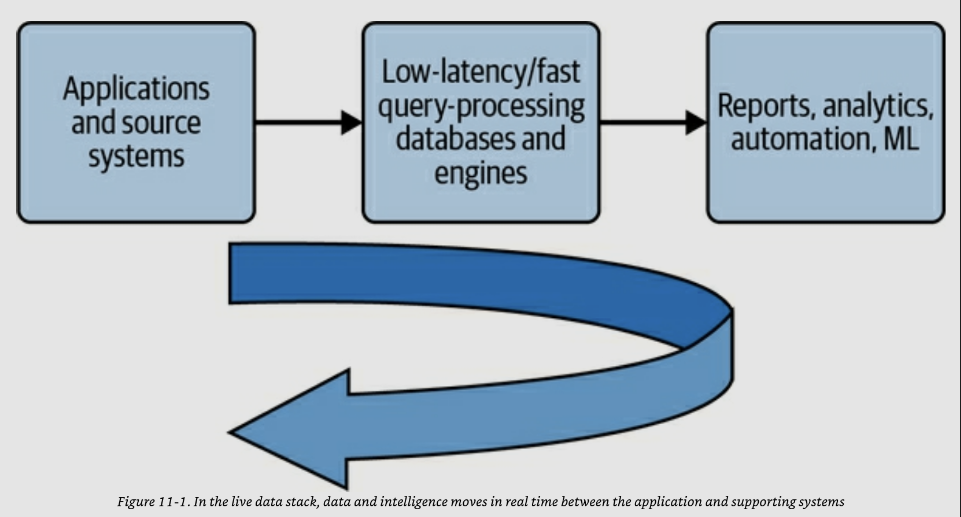
- ★金融業界の市場取引系だと市場のストリーミングデータからリアルタイムにアルファを推論して、取引エンジンへフィードバックしていくようなニーズはとてもありそう
- モダンデータスタックがクラウドを活用し、オンプレミスのデータウェアハウスとパイプライン技術を大衆にもたらしたように、ライブ・データ・スタックは、エリートハイテク企業で使用されているリアルタイム・データ・アプリケーション技術を、使いやすいクラウドベースのサービスとして、あらゆる規模の企業に提供する
- これにより、より優れたユーザー体験とビジネス価値を創造するための新たな可能性の世界が開かれる
ストリーミング・パイプラインとリアルタイム分析データベース
- モダンデータスタックは、データを境界のあるものとして扱うバッチ技術に限定している
- 対照的に、リアルタイム・データ・アプリケーションは、データを境界のない連続的なストリームとして扱う
- ストリーミング・パイプラインとリアルタイム分析データベースは、モダンデータスタックからライブ・データ・スタックへの移行を促進する2つのコア・テクノロジーである
- ストリーミング・テクノロジーは当分の間、著しい成長を続けるだろう
- ストリーミング・パイプラインや自動化、リアルタイム分析が可能なダッシュボードと組み合わせれば、まったく新しいレベルの可能性が開ける
- ストリームの台頭とともに、データ変換の未来への回帰(back-to-the-future moment)が予想される
- データウェアハウスやデータレイクは、大量のデータを収容し、アドホックなクエリを実行するのには適しているが、低レイテンシーでのデータ取り込みや、急速に移動するデータに対するクエリにはあまり最適化されていない
- 2000年代初頭以来、本格的なイノベーションが起きていないデータモデリングも、革新の機が熟していると思われる分野だ
データとアプリケーションの融合
- 次の革命は、アプリケーション層とデータ層の融合だと予想する
- 現在、アプリケーションはある領域に置かれ、モダンデータスタックは別の領域に置かれている
- さらに悪いことに、データは分析にどのように使用されるかを無視して作成されている
- その結果、システム同士が会話できるようにするために、たくさんの「ガムテープ」が必要になっている
- このパッチワークのようなサイロ化されたセットアップは、厄介で得体が知れない
- 近い将来、アプリケーション・スタックはデータ・スタックとなり、その逆もまた然りとなるだろう
- アプリケーションは、ストリーミング・パイプラインとMLによって、リアルタイムの自動化と意思決定を統合する
- データエンジニアリングのライフサイクルは必ずしも変わらないが、ライフサイクルのステージ間の時間は大幅に短縮されるだろう
- ライブ・データ・スタックのエンジニアリング経験を向上させる新しいテクノロジーやプラクティスにおいて、多くのイノベーションが起こるだろう
- OLTPとOLAPが混在するユースケースに対応するように設計された新しいデータベース技術に注目してほしい
- feature storesはMLのユースケースでも同様の役割を果たすかもしれない
- 現在、アプリケーションはある領域に置かれ、モダンデータスタックは別の領域に置かれている
アプリケーションとMLの間の緊密なフィードバック
- 我々が期待しているもうひとつの分野は、アプリケーションとMLの融合だ
- 今日、アプリケーションとMLは、アプリケーションとアナリティクスのようにバラバラのシステムになっている
- ソフトウェア・エンジニアと、データ・サイエンティストやMLエンジニアは別々の場所で仕事をする
- MLは、人間が手作業で処理できないほど大量のデータが大量に生成されるシナリオに適している
- データのサイズと速度が大きくなるにつれ、これはあらゆるシナリオに当てはまる
- 動きの速い大量のデータと、洗練されたワークフローやアクションは、MLの候補となる
- データのフィードバックループが短くなるにつれて、ほとんどのアプリケーションがMLを統合すると予想される
- データの動きがより速くなるにつれて、アプリケーションとMLの間のフィードバックループはより緊密になるだろう
- ライブ・データ・スタックのアプリケーションはインテリジェントで、データの変化にリアルタイムで適応できる
- これにより、アプリケーションがより賢くなり、ビジネス価値が高まるというサイクルが生まれる
ダークマター・データと...スプレッドシートの台頭?
- これまで、動きの速いデータと、アプリケーション、データ、MLがより密接に連携することでフィードバックループが縮小することについて話してきた
- 一方で、今日のデータの世界で、特にエンジニアが広く無視していることを取り上げる必要がある
- 最も広く使われているデータプラットフォームとは、地味なスプレッドシートだ
- データ分析のかなりの部分はスプレッドシートで実行され、本書で説明するような洗練されたデータシステムに入ることはない
- 多くの組織では、スプレッドシートが財務報告、サプライチェーン分析、さらにはCRMを扱っている
- スプレッドシートは、複雑な分析をサポートするインタラクティブなデータアプリケーションである
- pandas(Pythonデータ分析ライブラリ)のような純粋にコードベースのツールとは異なり、スプレッドシートは、ファイルを開いてレポートを見る方法を知っているだけのユーザーから、高度な手続き的データ処理をスクリプト化できるパワーユーザーまで、あらゆるユーザーがアクセスできる
- これまでのところ、BIツールはデータベースと同等の対話性をもたらすことができなかった
Conclusion
- 私たちは、
- 我々の予言のいくつかの側面は、比較的確実に実現しつつある
- マネージドなツールによる簡素化と”エンタープライズ的”なデータエンジニアリングの台頭は日々進行している
- ライブ・データ・スタックの出現の兆しが見えるが、これは個々のエンジニアにとっても、彼らを雇用する組織にとっても、大きなパラダイム・シフトを伴う
- ただ、リアルタイムデータへの流れは中短期的には停滞し、ほとんどの企業は基本的なバッチ処理に焦点を当て続けるだろう
- きっと、私たちが完全に特定できていない他のトレンドが存在するのだろう
- テクノロジーの進化は、テクノロジーと文化の複雑な相互作用を伴い、どちらも予測不可能である
- データエンジニアリングは広大なトピックであり、個々の領域について技術的に深く掘り下げることはできなかったが、現職のデータエンジニア、将来のデータエンジニア、そしてこの分野に隣接して働く人々が、流動的な領域で自分の進むべき道を見つけるのに役立つ、旅行ガイドのようなものを作成することに成功したことを願っている
- 私たちは、あなた自身が探求を続けることを勧める
- その上で、テクノロジーを採用し、それぞれの役割の中で(indivisual contributorとして、リーダーとして、チーム内で、テクノロジー組織全体...etc)専門知識を身につける必要がある
- その際、データエンジニアリングの大きな目標を見失ってはならない。つまり、ライフサイクルに集中し、社内外の顧客にサービスを提供し、ビジネスに貢献し、より大きな目標を達成するのだ
- 将来については、皆さんの多くが次に来るものを決定する役割を果たすことになるだろう
- 最後に、皆さんのキャリアがエキサイティングなものになることを祈っている。私たちがデータエンジニアリングの仕事を選び、コンサルタントをし、この本を書くことにしたのは、単にそれが流行していたからではなく、それが魅力的だったからだ。私たちがこの分野で働く喜びを少しでもお伝えできたなら幸いである