AWS Analytics Advent Calendar 2024 2 日目のエントリです。.
 .
.
はじめに
現在開発中の Apache Iceberg Table Spec v3 では、以下の機能が追加されます。
- New data types: nanosecond timestamp(tz), unknown
- Default value support for columns
- Multi-argument transforms for partitioning and sorting
- Row Lineage tracking
- Binary deletion vectors
本記事では、Iceberg 1.7.0 で追加された Row Lineage を解説します。
Iceberg Table Spec とは?
Iceberg Table Spec は、Iceberg テーブルがテーブルフォーマットとしてどのように扱われ、どのように振る舞うかを定義する規約です。Spark や Trino 等の各種クエリエンジンが Table Spec に従って Iceberg テーブルを読み書きすることで、エンジンを横断して共通的な ACID トランザクションや、タイムトラベル等を実現できます。
Table Spec にはバージョンがあり、最新は v3 です。ただし、Spec v3 はまだ活発に策定が進んでいる段階で、現時点では殆ど全てのクエリエンジンは v2 までをサポートしています。従って、Icebergの利用者にとって実務的には v2 が最新ということになります。Table Spec のバージョンは、前方互換性が失われるタイミングでインクリメントされる方針となっています。
一義的にはTable Spec の記載内容が Iceberg の仕様であると言えます。しかし、Table Specは規約に過ぎないので、それらの仕様が何処まで/どのようにサポートされるかは各ソフトウェア次第である点に注意が必要です。実際にはSpark や Trino などの主要なソフトウェアが Iceberg をサポートするためのライブラリは Iceberg プロジェクト側で開発しており、それぞれのコミュニティと活発に仕様の擦り合わせをしているため、サポートを完全に個々のソフトウェア側に放任しているわけではありません。それでも、それぞれのライブラリの開発状況には濃淡がありますし、各ソフトウェアの特性に依存した仕様が存在し得る点については留意が必要です。
Table Spec v3 についても仕様は固まりつつあるものの、それを実際のソフトウェアから使用するにはまだ様々な開発が必要な段階です。
Row Lineage
概要
v3 Spec に追加された Row Lineage は Iceberg に行レベルのリネージを追加するもので、基本的な考え方は、テーブルの各行に一意の識別子と、その行のバージョンを示すマーカーを付与することです。
従来、Iceberg はトランザクションレベルの変更までしか追跡できませんでしたが、Row Lineage によって、テーブルの行レベルの変更が追跡可能になります。これは様々な機能を実現するための前提となる仕組みと言えます。Row Lineage を活用することで、それを基盤として CDC サポートの拡充や、マテリアライズドビューの実装、詳細な監査機能が提供可能になることなどが期待されています。
Row Lineage のプロポーザル:Row Lineage Proposal - Google ドキュメント.
Iceberg Table Spec での Row Lineage の仕様:Spec - Apache Iceberg™.
仕組み
Row Lineageの基本的な仕組みを説明します。
有効化
Row Lineage はテーブルレベルで適用有無を設定できます。Row Lineage が有効化されたテーブルにはrow-lineage: true を設定されます。Row Lineage が無効なテーブルに新規に Row Lineage を設定することもできますが、行レベルで追跡できるのは有効化後の変更のみです。
Row Lineage は Equality Delete を含むテーブルには適用できません。(原理的に実現できない)
主要なエンジンでEquality Deleteを採用しているのはFlinkのみです。
Equality Delete のサポートをめぐる議論はこちらもご参照ください。
https://lists.apache.org/thread/6428zy09626nx05pvx8txwr2s2fqfp9b
Row Lineage を支えるアーキテクチャ
Row Lineage も他の多くの仕組みと同様に、Icebergのツリー状のメタデータ構造によって実現されます。 Iceberg の基本的なメタデータ構造が知りたい方は、Table Specを読むか、以下のスライド、記事をご参照ください。
以下は Iceberg のメタデータ構造の各レイヤーで、Row Lineage がどう追跡されるかを示す図版です。空のテーブルに初めてレコードが 100 行書き込まれた時点の状態を示しています。
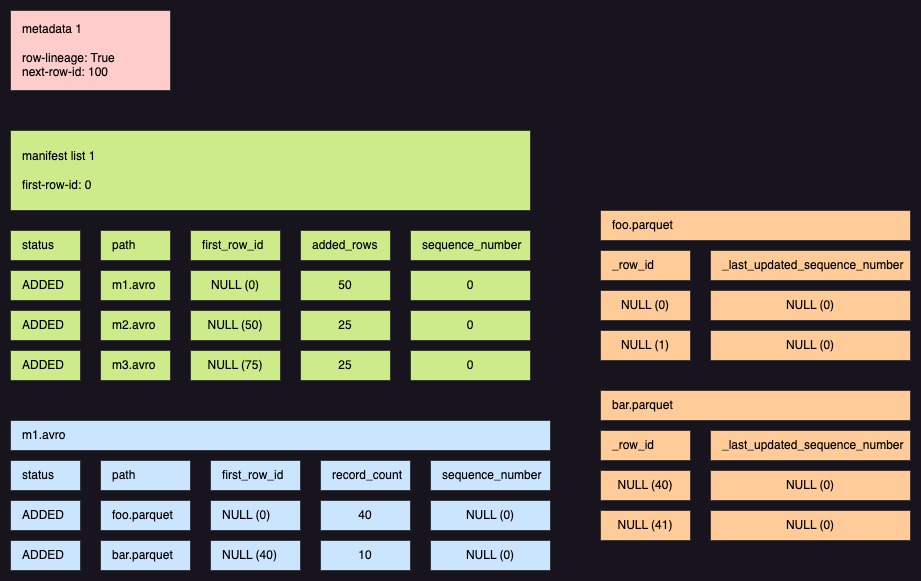
metadata.
metadata は、next-row-id フィールドを管理します。これはテーブル全体の最新の row id を示しており、新たなレコードを書き込む際は、next-row-idを参照して id を採番します。
manifest list.
manifest list は、Snapshot ごとに、Snapshotを構成するmanifest file の最初の row id を first_row_idとして保持します。manifest list の Snapshot 構造は、そのmanifest file が追加した行の総数を added_rowsとして保持するので、これらによってmanifest file が何行のレコードを扱っているかを把握できます。
図版ではfirst-row_idがNULL(数値)となっていますが、これは「継承による値の割り当て」に基づく挙動です。レコードの書き込みが行われた時点では、first_row_idの値には NULL が設定され、テーブルのリーダーがメタデータのnext-row-idと manifest list のadded_rowsから算出して、実際のfirst_row-idを括弧内の値で読み替えます。
「継承による割り当て」は Row Lineage 全体に共通するコンセプトであり、パフォーマンスの最適化に役立ちます。各種 id や sequence 番号をメタデータツリーを通じて値を継承できるようにすることで、明示的な値を指定せずにmanifest list, metadata file, data file を書き込めるようになるため、コミットの競合時に各ファイルを作り直さずに使いまわせるようになるためです。
Snapshotを構成するmanifest file ごとに設定されるsequence_number は、 manifest file が追加された時点でのシーケンス番号です。
manifest file
manifest file は、それが管理するdata file ごとに、最初の行の row idをfirst_row_idとして保持します。manifest file が追加された時点ではNULLが設定され、リーダーがmanifest file のfirst_row_idとmanifest fileのrecord_countから継承して算出します。
また、sequence_number は manifest file が追加された時点での シーケンス番号です。追加された時点ではテーブル内の各行を一意に識別するmanifest file のsequence_numberから継承して算出します。
data file .
data file は各行にテーブル内の各行を一意に識別する row_id を保持します。行が新規に追加された時点ではNULLが設定され、リーダーがmanifest fileの first_row_id から継承して算出します。
行が新しいファイルにコピーされる際は既存の値を明示的に書き込みます。
加えて、data file は各行を最後に更新したコミットのシーケンス番号 _last_updated_sequence_number を保持します。行が新規に追加された時点ではNULLが設定され、リーダーがmanifest fileの sequence_number から継承して算出します。既存のレコードを変更なしでコピーする場合は既存の値を保持します。
以上を踏まえて、1枚目のテーブルに行の追加と変更を行った時点でのメタデータ構造の図版がこちらです。
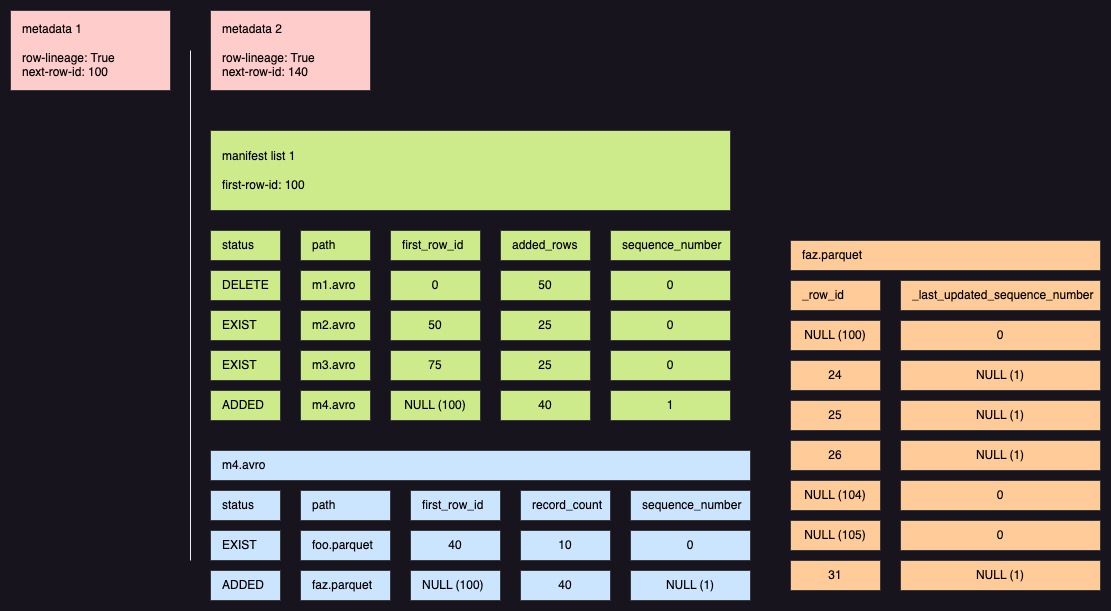
まとめ
本エントリでは、Apache Iceberg Table Spec v3の新機能である「Row Lineage Tracking」を紹介しました。v3 specをサポートするライブラリの実装や、それらを活用する各種機能の成熟までにはもう少し時間がかかりそうですが、その仕組みのイメージとポテンシャルにワクワクしていただけたなら幸いです!