
Distributed Computing Advent Calendar 2025 の記事です。
私は2025年の初頭にOpenSearchというOSSに出会いました。それは検索技術というものに全く触れたことがなかった私にとって衝撃的な体験で、すっかりOpenSearchにハマってしまい、この1年は暇を見つけては触っていました。
ではOpenSearchが何故それほど面白いのか、自身の整理と皆さんへの布教を兼ねて書いてみようと思います。
私はAWS社の人間ですが、本記事は年の瀬に個人の趣味で書いており、基本的にOSSのOpenSearchの話しかしません。
- そもそもOpenSearchとは
- ユースケースの幅広さがおもろい
- 検索がおもろい
- スケーラビリティの探究がおもろい
- プロジェクトの広がりと進化がおもろい
- OSSコントリビューションがおもろい
- コミュニティがおもろい
- まとめ
そもそもOpenSearchとは
OpenSearchはオープンソース(Apache-2.0 license)の検索・分析スイートです。2021年にElasticsearch 7.10からforkする形で誕生しました。
様々な構造のデータへの全文検索やベクトル検索、集計分析などが可能で、Webサービスの検索バックエンドからデータ分析、オブザーバビリティ、生成AIのナレッジベースまで多様なユースケースで活用できます。
github.com
2024年にOpenSearchプロジェクトの管理はAWS から Linux Foundation 傘下の OpenSearch Software Foundation へ移管されました。現在はAWSだけでなく、UberやByteDance, SAPなど多様な組織が開発を主導しています。プロジェクトを舵取りするTechnical Steering Committeeは11社15名で構成されています。
もちろん、所属する組織に関係なく、誰もが改善を提案したり、コントリビューションできます。
bering.hatenadiary.com
実行環境の選択肢としては、AWS の Amazon OpenSearch Service が有名ですが、それ以外にもOCI Search with OpenSearch や Canonical の OpenSearch for the enterprise、Managed OpenSearch by Aivenなどがあります。
また、セルフホストで運用している組織も複数あり、LINEやCERNなど複数の事例があります。
bering.hatenadiary.com
bering.hatenadiary.com
それでは、私が思う OpenSearch の面白さをご紹介します。
ユースケースの幅広さがおもろい
The Definitive Guide to OpenSearchの序文で、OpenSearchは"Swiss Army knife"(十特ナイフ)と表現されています。
この比喩がまさに言い得て妙で、OpenSearchは本当に様々な場面で活躍します。
- Eコマース: 商品検索、閲覧履歴に基づくレコメンデーション
- メディア/エンタメ: 動画・音楽・書籍の検索、視聴履歴に基づくコンテンツ推薦
- 旅行サービス: フライト・ホテルの条件検索、旅行先のレコメンデーション
- 金融: 取引履歴の検索、支出パターンの分析
- ヘルスケア: 検査結果や処方履歴など健康記録の検索
- 求人: 求人検索、スキルや経験に基づくマッチング
- 製造: 部品番号や仕様での在庫検索
- 位置情報サービス: 近隣店舗やスポットの検索、配達パートナーのマッチング
- 天文学: 星や銀河など膨大な観測データの検索・分析
検索の手法も多彩です。転置インデックスを用いた高速な全文検索はもちろん、ベクトル検索によるセマンティック検索にも対応しています。セマンティック検索では、クエリとドキュメントの「意味的な近さ」で検索できるため、キーワードが完全一致しなくても関連するドキュメントを見つけられます。例えば「一人暮らし向けの簡単な作り置きレシピ」というクエリで、「単身者」「時短」といった表現を含むレシピもヒットする、といった具合です。全文検索とベクトル検索を組み合わせたハイブリッド検索も可能で、ユースケースに応じて柔軟に使い分けられます。
さらに、OpenSearchはログ分析やオブザーバビリティの分野でも活躍しています。OpenSearchは大量のログやトレース、メトリクスをリアルタイムで処理・分析できます。システムのトラブルシューティングやセキュリティ分析はもちろん、クリックストリーム分析やIoTセンサーデータの分析など、ビジネスインサイトの抽出にも活用されています。
そして最近注目されているのが、生成AIのナレッジベース(RAG)としての活用です。ベクトル検索機能を活かして、LLMに与えるコンテキストを効率的に検索・取得できます。検索エンジンとしての成熟した機能と、ベクトルDBとしての機能を兼ね備えています。
OpenSearchに取り組んでいると、こうした幅広いユースケースに触れることができ、大変面白いというわけです。
先日、OpenSearchConというOpenSearchコミュニティのお祭りが東京で開催されており、そこで扱われるセッションのトピックの多様さに感心したのを覚えています。
検索がおもろい
これはOpenSearchに限った話ではありませんが、これまで検索技術に触れてこなかった筆者にとって「検索」の技術的な面白さも衝撃的でした。
「検索」は私たちの日常に溶け込んでおり、当たり前の行為として扱われています。
しかし、技術的な視点から「検索」を考えると、それが案外自明ではなく、複雑で奥行きのある処理であることに気づかされます。
まず、検索は本質的に「Relevance(関連性)」を扱う技術です。データベースのクエリのように「条件に合致するか否か」の二値で判定するのではなく、「どれくらい関連しているか」という濃淡を扱います。
ここで重要なのは、「関連性」には唯一の正解がないということです。「渋谷 ランチ」と検索したユーザーが本当に求めているものは何でしょうか。安くて早い店かもしれないし、おしゃれでインスタ映えする店かもしれない。一人で静かに食べられる店を探しているのかもしれないし、会食に使える個室のある店かもしれません。同じクエリでも、ユーザーによって、あるいは同じユーザーでもその時の状況によって「関連性が高い」と感じる結果は異なります。
つまり検索とは、不完全な手がかり(クエリ)から、ユーザーの真の意図を推測し、最適な情報を届けようとする営みです。この本質的な曖昧さと向き合い続けるところに、検索技術の難しさと面白さがあります。
ここで興味深いのは、「良い検索」の定義がコンテキストによって変わることです。例えばQ&Aサイトであれば、ユーザーの疑問に対する正確な回答に素早く辿り着けることが「良い検索」でしょう。検索結果の1位に答えがあることが理想です。
一方、ECサイトでは少し事情が異なります。検索クエリに完全一致する商品だけでなく、ユーザーが気づいていないけれど興味を持ちそうな商品をあえて提示する、つまり「推薦」としての役割も求められます。「青いTシャツ」と検索したユーザーに対して、青いTシャツだけでなく、合わせやすいパンツや、似たテイストの別の色のTシャツを混ぜることで、購買体験が向上するかもしれません。
ニュースサイトであれば、単純な関連性だけでなく「鮮度」も重要な要素になります。1年前の記事より今日の記事を優先したいケースが多いでしょう。動画サイトであれば、検索結果にユーザーの視聴履歴や嗜好を反映させるパーソナライゼーションも「良い検索」の要素になります。
このように、同じ「検索」という機能でも、求められる振る舞いがドメインによってまったく違うわけです。この奥深さが、検索技術の面白いところだと感じています。
そして、検索システムを構築しようとすると、驚くほど多様な技術領域が交差していることに気づきます。テキストをどう解析し正規化するかという自然言語処理、大量のデータから高速に候補を絞り込むためのデータ構造とアルゴリズム、ユーザーの意図を汲み取り結果を並べ替えるための機械学習、ベクトル検索を導入するならモデルの選定や全文検索との組み合わせ方、検索体験を形作るUIの設計、そしてユーザー行動を分析して改善につなげるサイクル。これらが「検索」という一つの体験の中で絡み合っています。検索システムは作って終わりではなく、継続的に育てていくものなのです。
このように、検索は多様な領域が交差する、まさに総合格闘技のような世界です。こうした難題に向き合うことは、ITエンジニアにとって、大変に刺激的ではないでしょうか。
OpenSearchはこれらの営為を支える一連の仕組みを提供しています。
スケーラビリティの探究がおもろい
「良い検索」は複雑で奥行きのある行為であるわけですが、それらを現実世界に適用する上では、「膨大なデータに対して」「高速に」「コスパよく」「適切な信頼性を備えたインフラで」「安全に」提供することがしばしば求められます。つまり、非機能要件にも目を向ける必要があるわけです。
これがOpenSearchとそれが扱う問題空間をより面白くしています。
OpenSearchは膨大なドキュメントを扱うための様々な仕組みを備えており、数十億規模の事例も決して珍しくはありません。
まず、クエリを高速化するための工夫について考えてみましょう。OpenSearchではインデックスを複数のシャードに分割し、クラスタ内の複数ノードに分散配置できます。クエリは各シャードで並列に実行され、結果がマージされて返されます。シャードの数やサイズをどう設計するか、クラスタのノード数やスペックをどうサイジングするかが、検索性能を大きく左右します。それ以外にも、高速化のための検討ポイントは数多くあります。インデックスのマッピング設計、クエリの書き方の最適化、クエリキャッシュやリクエストキャッシュの活用など、レイヤーごとにチューニングの余地があります。データ量やクエリパターン、レイテンシ要件を踏まえて最適な構成を探っていくのは、パズルを解くような面白さがあります。
検索だけでなく、データの投入(インデクシング)の効率化も重要なテーマです。リアルタイムにログを取り込み続ける用途では、毎秒数十万件のドキュメントを捌く必要があるかもしれません。OpenSearchではバルクAPIの活用、リフレッシュ間隔の調整、レプリカ数の一時的な削減など様々なチューニングが検討できるほか、Segment Replicationによってデータの投入をより少ないリソースで、より高速に実現する仕組みもあります。
コストの最適化も避けて通れないテーマです。たとえばベクトル検索では、高次元のベクトルデータがストレージとメモリを大量に消費します。ここで活躍するのがベクトルの量子化です。OpenSearchでは多様なコスト最適化手法が検討でき、32ビット浮動小数点を16ビットや8ビット、さらにはバイナリに圧縮することでメモリ使用量を削減できます。コスト効率と精度を両立するための高度なアプローチとして、Disk-based vector searchのようなテクニックも利用可能です。
信頼性の確保についても、シャードのレプリカをどう配置するか、ノード障害時にサービスを継続できるか、データの耐久性をどう担保するか。サービスの要件に応じて、様々なことを考えなければなりません。
OpenSearchはこうした要件に応えるための仕組みを広汎に備えており、最近ではRemote-backed storageと呼ばれるインデックスデータをAmazon S3などのオブジェクトストレージに保存する仕組みを使用することで、柔軟なスケールが実現できるようになっています。また、インデクシングと検索の負荷が互いに影響し合うのを避けたい場合には、それぞれの計算リソースを分離して独立にスケールさせる仕組みも利用できます。
www.youtube.com
セキュリティの観点では、データへのアクセスコントロールや暗号化、監査ログの運用などを考える必要があり、OepnSearchではセキュリティプラグインをはじめとする仕組みがそれらを支えます。
加えて、OpenSearchのクラスターは時に複数のユーザーやシステムの集合に利用されることもあるでしょうから、性能や信頼性、セキュリティなど様々な論点でマルチテナント戦略も重要になってきます。
bering.hatenadiary.com
このように、「良い検索」を実現する機能面の探究と、それを支える非機能面の探究の両輪によって、OpenSearchが一層面白くなるというわけです。
プロジェクトの広がりと進化がおもろい
OpenSearchは多様なユーザーによって利用されており、同時に様々なバックグラウンドを持つ開発者がコントリビューションしています。
結果として、OpenSearchプロジェクトにはコアとなる検索エンジンとしての機能だけでなく、幅広いプラットフォームの広がりがあり、興味深い機能が日々追加されています。
まず、OpenSearchプロジェクトのGithubに目を向けると、全体のコアとなるOpenSearchとOpenSearch-Dashboardsを含めて、なんと141ものリポジトリが存在しています。
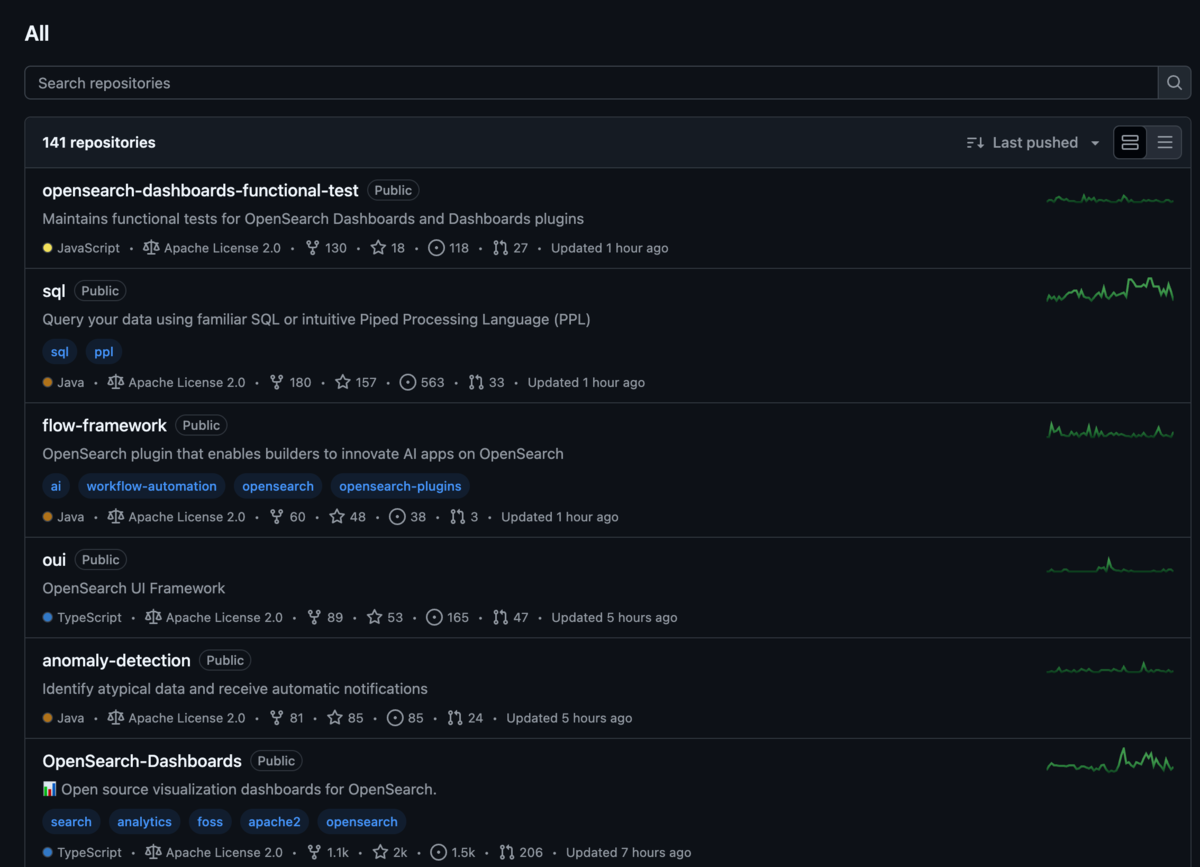
その中には、OpenSearchをSQL/PPLで分析するためのエンジンを提供するsqlやデータの取込みを簡単にするための仕組みであるData Prepper、SparkなどのHadoopエコシステムからOpenSearchを操作するためのopensearch-hadoop、負荷試験ツールであるopensearch-benchmark
、k8s operatorのopensearch-k8s-operator
などなど、非常に幅広いコードベースが含まれています。
これはさながら1つの国のようで、それぞれの分野のコミュニティにユーザーや専門家が属し、日夜改良を重ねているわけです。
そんなOpenSearchの様々な側面を探訪するのは、きっと愉快な旅になることでしょう。
こうした広がりを持つプロジェクトだからこそ、刺激的な新機能が次々に生まれてきます。その中には、OpenSearchの従来の仕組みや考え方を改革し、新しい活用法を切り開くものも少なくありません。
たとえば、セグメントに対する並列での検索を可能にするConcurrent segment searchやGPUによってベクトルのインデクシングや検索を高速化するGPU Acceleration、Kafkaなどからのプルベースでのデータ取込みを可能にするPull-Based Ingestion、Apache DataFusionによって集計クエリを高速化する取り組み、検索精度の評価を行うためのSearch Relevance Workbenchなどです。
(*私の知識がクラスタ最適化にやや偏っているため検索系の例が少なめですが、そちらも様々な新機能があります!)
OpenSearchはfork前のElasticsearchも含めて非常に歴史の長いソフトウェアである一方で、決して変化を止めたわけではなく、今も変わり続けているのです。この流れは、Linux Foundationへの移管以降加速しているようにも感じます。おそらく、AWSが管理するOSSであった頃よりも幅広い組織がユーザーとなり、貢献しているために、その進化もより速く、より多様になっているということなのでしょう。
こうした多様で日々変化するプラットフォームに触れ、進化の過程を目撃する面白さも、OpenSearchに触れ合う醍醐味の一つです。
OSSコントリビューションがおもろい
OpenSearchはOSSであり、誰もがコミュニティに貢献できます。
新機能の追加に向けたコード貢献はもちろん、不具合のissueでの報告や、 学びをブログやイベントなどで発表することも立派な貢献です。
ここまで述べた通り、OpenSearchには多様な側面があり、様々なユースケースや技術スタックが関係するため、多くの人がそれぞれの形で貢献できる余地があると思います。
私もこの1年で5件のPRをOpenSearchへ送り、マージされました。
最初は比較的土地勘があったopensearch-hadoopの改善やバグ修正から始めました。これらを通じて、OpenSearchプロジェクトにおけるコード貢献の流れを掴みました。
github.com
github.com
github.com
最近ではSearchable Snapshotについて調査していく中でバグを発見して修正しました。
github.com
他にもOpenSearchConでの発表をきっかけにISMの_search API統合の開発などに取り組んでいます。
github.com
このように、活発に進化するOpenSearchの成長に自分自身が関与できることも大変面白いところです。
OSSへの貢献に興味がある方は、ぜひ以下のガイド記事をチェックしてみてください。
bering.hatenadiary.com
zenn.dev
コミュニティがおもろい
OpenSearchは世界各地にユーザーグループがあり、東京にも「OpenSearch Project Tokyo ユーザーグループ」があります。
www.meetup.com
各ユーザーグループでは定期的にミートアップが開催されており、東京ユーザーグループ初のミートアップは2026年2月5日に開催予定です。(ぜひご参加ください!)
www.meetup.com
また、年に数回、世界各地で「OpenSearchCon」と呼ばれるカンファレンスが開催されており、ここではOpenSearchのユーザーやOSS開発者が世界中から集合し、実践的な活用や、今後の機能拡張について語り合っています。
12月には日本初のOpenSearchCon Japan 2025が東京で開催されました。
www.youtube.com
私もOpenSearchCon North America 2025とOpenSearchCon Japan 2025に運よくCFPを通すことができ、登壇してきました。
www.youtube.com
www.youtube.com
当日の様子(写真)はこんな感じです
Japan 2025: OpenSearchCon Japan 2025 | Flickr
North America 2025: OpenSearchCon North America 2025 | Flickr
こうしたカンファレンスの醍醐味は、世界中の開発者やユーザーと直接交流できることです。セッションの合間のネットワーキングや懇親会では、様々なバックグラウンドの人々と顔を合わせ、それぞれが抱える課題や工夫について話を聞くことができます。そうした生の知見は、ドキュメントやブログだけでは得られない貴重なものです。
OpenSearchConはCFP(Call for Proposals)で登壇者を募集しているので、OpenSearchを使っている方はぜひ応募を検討してみてください。大規模な本番運用の話である必要はありません。自分なりの工夫や学び、あるいはハマりどころの共有でも、同じ課題に取り組む誰かにとっては価値ある情報になります。私自身、最初は「こんな内容で通るだろうか」と不安でしたが、思い切って出してみたことで貴重な経験を得ることができました。
コミュニティに参加し、世界中のエンジニアと繋がれることもまた、OpenSearchの面白いところです。
まとめ
本記事では、OpenSearchの面白さを自分なりに整理してみました。
振り返ってみると、私にとってのOpenSearchの魅力は大きく二つあるのだと思います。
まず、ユースケースと技術の両面で、汲めども尽きぬ幅広さと奥深さがあることです。検索のバックエンドから分析やオブザーバビリティ、RAGまで多様な領域で活用でき、それを支える技術も全文検索からベクトル検索、分散システムの設計まで多岐にわたります。どこを掘っても新しい発見があり、飽きることがありません。
そして、活発なコミュニティに関与できること。世界中から多様なバックグラウンドを持つ開発者が集まり、日々プロジェクトを進化させています。issueの報告、PR、ブログの執筆、カンファレンスでの登壇など、自分なりの形でその成長に関われるのはOSSならではの醍醐味です。
もしこの記事を読んで少しでも興味を持っていただけたなら、ぜひOpenSearchに触れてみてください。