はじめに
Open Table Formatは次世代のデータレイクの基盤となり得る技術で、徐々に導入事例(末尾に列挙)が増えてきているものの、日本での認知度は発展途上な印象がある。本記事ではOpen Table Format登場の背景を紹介する。執筆にあたって、Apache Iceberg: An Architectural Look Under the CoversとAWSにおける Hudi/Iceberg/Delta Lake の 使いどころと違いについてを特に参考にした。
Open Table Formatとは?
Open Table Formatとは、従来のデータレイクの技術的な課題&ユースケースの要請に応える形で登場した、データレイクに最適化されたテーブルフォーマットを指す概念で、上手く活用することでクエリプランニング、実行性能の最適化、効率的なUpdateやDelete、タイムトラベルクエリ、スキーマの変化への追従などを実現できる。
これらの技術を指す用語について業界のコンセンサスは定まっておらず、「Open Table Format」や「Data Lake Format」など人/組織によって様々な呼称が見られるが、本エントリでは取り敢えず「Data Lake Table Format」と呼称することにする。
2023/9/18追記: 「Open Table Format(OTF)」がメジャーになってきている気がするので、記事中の記載を「Data Lake Table Format」から変更した
従来のデータレイクの技術的課題とユースケースの要請
本エントリにおける"データレイク"とは?
前提として、ここでのデータレイク(Data Lake)は(James Dixonの原義)と直接的に同じではなく、大量の(非)構造化データをHDFSやS3などの分散ファイルシステムに蓄積して、Apache SparkやTrino, Apache Flinkなどから活用するアーキテクチャ全般を指している。その限りにおいては、「本来的な意味での」データレイクでなくても良い。
AWSに慣れている人向けに表現するなら、S3にデータを保存して、AWS Glue DataCatalog(Hive Metastore)でメタデータを管理して、AWS Glue(Apache Spark)でETLして、Amazon Athena(Trino)でクエリする、といった感じの構成がシンプルかつ代表的だと思う。
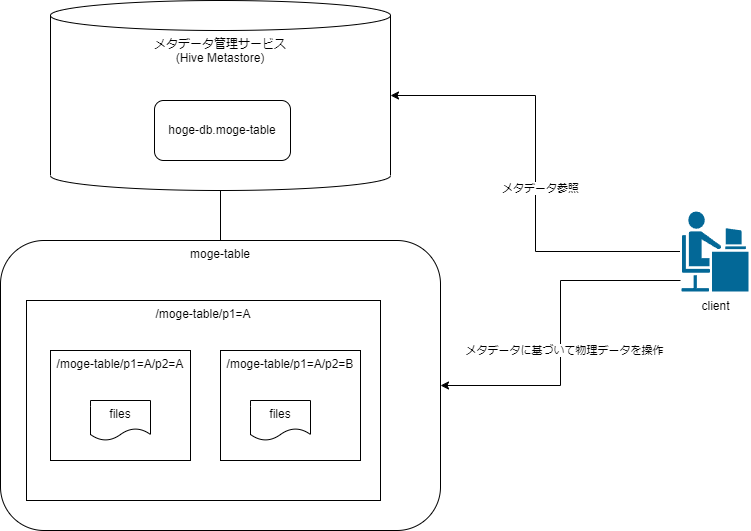
重要なのは、データレイク上のデータは論理的なテーブル(table)で管理される点だ。例えばS3に以下のようなファイルがあるとする。
:~$ aws s3 ls s3://hoge/hoge-table/ 2021-01-11 23:57:40 0 2021-01-11 23:58:21 3832812 moge.json
:~$ head moge.json
{"id":1,"name":"Mary","year":1880,"gender":"F","count":7065}
{"id":2,"name":"Anna","year":1880,"gender":"F","count":2604}
{"id":3,"name":"Emma","year":1880,"gender":"F","count":2003}
{"id":4,"name":"Elizabeth","year":1880,"gender":"F","count":1939}
{"id":5,"name":"Minnie","year":1880,"gender":"F","count":1746}
{"id":6,"name":"Margaret","year":1880,"gender":"F","count":1578}
{"id":7,"name":"Ida","year":1880,"gender":"F","count":1472}
{"id":8,"name":"Alice","year":1880,"gender":"F","count":1414}
{"id":9,"name":"Bertha","year":1880,"gender":"F","count":1320}
{"id":10,"name":"Sarah","year":1880,"gender":"F","count":1288}
クライアントがこのデータを直接扱おうとすると、データが存在する場所(ここではS3のパス)やファイル形式、圧縮形式、カラム情報などを都度意識して処理を決めなければならず大変煩雑になる。そこで、物理データから解釈できる論理的なテーブル「hoge-table」を定義するメタデータを作成し、メタデータを管理する何らかのサービス(例えばGlue Data Catalog)に保存しておく。
hoge-tableのメタデータ例(クリックで展開)
{
"Name": "hoge-table",
"DatabaseName": "default",
"Owner": "hadoop",
"CreateTime": "2023-07-17T01:31:04.000Z",
"UpdateTime": "2023-07-17T01:31:04.000Z",
"LastAccessTime": "1970-01-01T00:00:00.000Z",
"Retention": 0,
"StorageDescriptor": {
"Columns": [
{
"Name": "id",
"Type": "int",
"Comment": "from deserializer"
},
{
"Name": "name",
"Type": "string",
"Comment": "from deserializer"
},
{
"Name": "year",
"Type": "int",
"Comment": "from deserializer"
},
{
"Name": "gender",
"Type": "string",
"Comment": "from deserializer"
},
{
"Name": "count",
"Type": "int",
"Comment": "from deserializer"
}
],
"Location": " s3://hoge/hoge-table/",
"InputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"OutputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",
"Compressed": false,
"NumberOfBuckets": -1,
"SerdeInfo": {
"SerializationLibrary": "org.openx.data.jsonserde.JsonSerDe",
"Parameters": {
"serialization.format": "1",
"paths": "count,gender,id,name,year"
}
},
"BucketColumns": [],
"SortColumns": [],
"Parameters": {},
"SkewedInfo": {
"SkewedColumnNames": [],
"SkewedColumnValues": [],
"SkewedColumnValueLocationMaps": {}
},
"StoredAsSubDirectories": false
},
"PartitionKeys": [],
"TableType": "EXTERNAL_TABLE",
"Parameters": {
"sizeKey": "3832812",
"objectCount": "1",
"EXTERNAL": "TRUE",
"recordCount": "3657",
"transient_lastDdlTime": "1689557464",
"averageRecordSize": "1048",
"compressionType": "none",
"classification": "json",
"typeOfData": "file"
},
"CreatedBy": "hogehoge",
"IsRegisteredWithLakeFormation": false,
"CatalogId": "826964323461",
"IsRowFilteringEnabled": false,
"VersionId": "0",
"DatabaseId": "9506b95428894c859c1584c874b654b8"
}
これによって、クライアント(以下ではAmazon Athena / Trino)はmoge.jsonのデータ形式などの詳細を「知らなくても」、論理テーブル「hoge-table」を指定するだけでクエリを実行できる。
 また、クエリ効率を向上する手段として、データを日付や国、地域などのカラムの値単位でフォルダにまとめておくパーティショニングという手法もある。
以下の例では、year カラムでパーティショニングされている。このデータに対してWHERE句でyearの値を限定することで、スキャン対象のデータを削減し、実行時間の削減、マシンリソースの節約が可能になる。
また、クエリ効率を向上する手段として、データを日付や国、地域などのカラムの値単位でフォルダにまとめておくパーティショニングという手法もある。
以下の例では、year カラムでパーティショニングされている。このデータに対してWHERE句でyearの値を限定することで、スキャン対象のデータを削減し、実行時間の削減、マシンリソースの節約が可能になる。
$ aws s3 ls s3://athena-examples/flight/parquet/ PRE year=1987/ PRE year=1988/ PRE year=1989/ PRE year=1990/ PRE year=1991/ PRE year=1992/ PRE year=1993/ :~$ aws s3 ls s3://athena-examples/flight/parquet/year=1987/ 2016-11-24 10:08:08 18481599 000008_0
SELECT * FROM flights WHERE year = 1991
これらのテーブル抽象化手法の源流には2009年にFacebookが作ったApache Hiveがあるが、現在では多くのソフトウェアがこの方式に適応しており、データレイクを構成する上でのデファクト的なデザインになっている。
従来のデータレイクの技術的課題
以下に従来のデータレイクの代表的な課題を挙げる。
課題①レコードレベルの変更が非効率
テーブルに対して数行のupsert, deleteを実施する場合でも大量のファイルの中から該当部分を発見して削除や更新を行う必要があり、処理コストが高い。
また、細かい単位で連続してレコードが書き込まれる場合に小さなファイルが沢山作成されるため、読み取り性能が劣化する。
課題②同時書き込み、読込みの独立性を確保できない
同一のテーブルに対して異なるプロセスが同時に書き込み、読み込みを実施した場合に不整合が生じる可能性がある。例えばプロセスAがカラムaの値に基づいてテーブルを更新している間にプロセスBがカラムaを更新してしまうとか、プロセスAがテーブルに複数の操作から成るトランザクション処理を実施している間にプロセスBが中途半端な状態のテーブルを読み込んでしまう、といった状態が発生する。
課題③テーブルを編集すると過去の断面が復元できない
データレイク上のデータの実体はparquetなどのファイルに過ぎないので、テーブルが変更されると過去のある時点の断面を参照出来ない。
課題④テーブルを構成するファイルが増えるとテーブル操作が高コスト化する
テーブルを構成するファイルが非常に多い場合、テーブルに紐づくファイルのリストを取得してクエリを計画する時間が長期化する。
例えばNetflixの日次40万ファイルで構成されるテーブルでは、Explainだけで10分近くかかっていたらしい。

youtu.be
課題⑤スキーマ変更への追従が大変
上流システムの都合などでテーブルのスキーマ定義が変更された場合、都度メタデータを更新しなければ正しくスキーマを認識できず、適切にテーブルを操作できない。
課題⑥効率よくクエリを実行するにはユーザがテーブルの物理構造を把握する必要がある
ユーザがテーブルのフルスキャンを避けて効率よくクエリを実行するには、対象のテーブルを構成するファイルの構成を把握している必要がある。
例えば「2023-07-17」のような形式で格納される「trade_date」カラムを持つテーブルがあったとする。この日付を細かくパーティショニングしたい場合はtrade_dateを「year」「month」「day」に切り分けて階層化することになる。
/year=2023/month=01/day=01/... /year=2023/month=01/day=02/... /year=2023/month=01/day=03/... /year=2023/month=02... /year=2023/month=03... /year=2024...
これらのパーティションを活かすには、以下のようなクエリでyear, month, dayを絞る必要がある。
SELECT * FROM hoge_table WHERE year= '2023' and month = '01' and day = '01' ;
しかしユーザとしてはそんなことは意識せず、trade_dateを指定して以下のようなクエリを打ちたくなるはずだ。しかしこれではパーティショニングが活かせない。つまり、ユーザがテーブルの物理構造を把握しなければならないのだ。
SELECT * FROM hoge_table WHERE trade_date= '2023-07-17';
(ちなみにAmazon Athenaの場合、この問題はParition Projectionで部分的に解決できる)
ユースケースの要請
上記の課題は、例えば次のようなユースケースで問題になる。(AWSにおける Hudi/Iceberg/Delta Lake の 使いどころと違いについてより)
ストリームデータの処理
- ストリームの性質上、読み込みと書き込み両方の性能を確保したい
- データの保存間隔を小さくすると、小さいファイルが沢山作られるため読み込み性能が劣化する vs データの保存間隔を伸ばすと、リアルタイム性が損なわれる
- (ストリーム処理で発生しがちな)重複データをケアするため、upsertによって重複を排除したい
- 様々な事情で遅れて届いたメッセージを適切にハンドリングしたい
- 上流システム側での変更に伴うスキーマ変更に追従したい
CDC
- 更新を継続的に反映するため、ターゲットテーブルに対して連続したupsertが必要になる
- CDCによってテーブルが継続的に更新される一方で、テーブルの参照者が「あるタイミング」の断面を一貫して参照できるようにしたい
個人情報保護法対応
- 決まった時間内に特定の個人情報を含むレコードを削除する必要がある
- データ削除中でも、テーブル参照者が一貫した断面を参照できるようにしたい
※Yahooは個人情報保護法対応に伴うレコード削除に対応するためData Lake Table Formatの一つであるApache Hudiを採用した事例を公開している techblog.yahoo.co.jp
データサイエンス
- データサイエンスでは実験の再現性を確保するため、「ある瞬間の断面」を再現できるようにしたい場面がある
- ここで、データレイクのデータは継続的に更新されていく一方で、あるタイミングで実施した実験、分析を再現できる必要がある
Data Lake Table Formatの登場
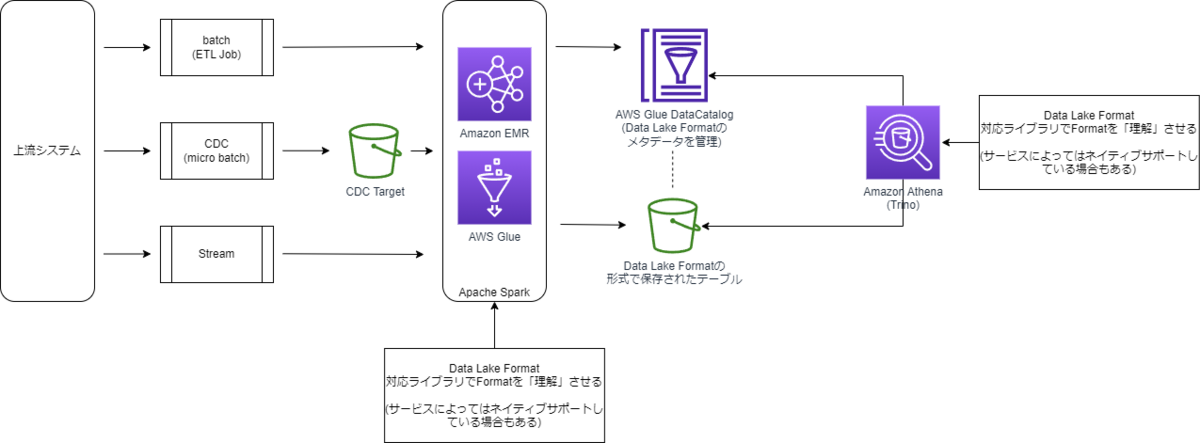
こうした課題・要請に応える形で出てきたのがData Lake Table Formatだ。これは以下の組み合わせによって、従来のデータレイクの様々な課題を解決する機能を実現する。
- データフォーマット
- データレイク内の「データの持ち方」の定義。Data Lake Table Formatを適用したデータレイクでは、決められたフォーマットに従ってデータ+メタデータを保持することになる。
- メタデータ管理機構
- クエリエンジン側の対応
- Data Lake Table Formatを使用するには、Apache SparkやTrinoなどのクエリエンジン側が当該フォーマットをどう扱うべきか「知って」いなければならない。そのため、クエリエンジンにTable Formatをサポートするライブラリを導入することで対応させる。
AWSに寄せた構成例で説明すると、以下のような形になる。
Data Lake Table Formatの種類
Apache Hudi, Apache Iceberg, Delta Lakeの3種類がメジャーな選択肢で、どれもOSSである。それぞれの概要と特徴を簡単に紹介する。また、それぞれの特徴が先述の課題のどの部分を解決するかの対応関係を示す。(網羅的ではないので注意)
Apache Hudi
- Uberが開発したData Lake Table Format
- Timelineによってテーブルに実行された全てのアクションの時間軸を保持
- 過去特定の断面のデータに対するTime Travelクエリを実現 → 課題③テーブルを編集すると過去の断面が復元できない
- WritersとReaders間のisolationをサポート(同時実行制御がサポートされる範囲、条件に注意が必要:リンク先参照) → 課題②同時書き込み、読込みの独立性を確保できない
- 性能特性に合わせて2種類のテーブル(Copy on WriteとMerge on Read)と3種類のクエリ(Snapshot Queries, Incremental Queries, Read Optimized Queries)を使い分けられる → 課題①レコードレベルの変更が非効率
- 直近のデータをAvroで処理しつつ、ヒストリカルデータはParquetに纏めることで書き込みと読み込みの性能をバランスする → 課題①レコードレベルの変更が非効率
- hoodie Keyによって効率的な更新、削除操作を実現 → 課題①レコードレベルの変更が非効率, 課題④テーブルを構成するファイルが増えるとテーブル操作が高コスト化する
- 効率的なメタデータアクセスによるプランニングの最適化 → 課題④テーブルを構成するファイルが増えるとテーブル操作が高コスト化する
- データソースのスキーマ変更に追従するSchema Evolutionをサポート → 課題⑤スキーマ変更への追従が大変
- 以下の記事でUberによるHudi開発の背景や自社でどのように活用しているかを紹介している
Apache Iceberg
Icebergの詳細記事を書きました。 bering.hatenadiary.com
- Netflixが開発したData Lake Table Format
- NetflixはS3上に60ペタバイト規模(2018時点)のデータレイクを保持しており、これらのデータを効率よく扱う必要に迫られて開発したらしい
- Table Specはこちら
- テーブルへの変更をスナップショットログで追跡する
- 過去特定の断面のデータに対するTime Travelクエリを実現 → 課題③テーブルを編集すると過去の断面が復元できない
- 効率的なクエリプランニング → 課題④テーブルを構成するファイルが増えるとテーブル操作が高コスト化する
- 同時実行制御 → 課題②同時書き込み、読込みの独立性を確保できない
- Readerはテーブルメタデータをロードした時点のSnapshotを参照し、その後の変更の影響を受けず一貫した断面を参照できる
- WriterはOCCで同時実行制御が可能。isolation levelはserializableとsnapshotから選択できる
- Evolution → 課題⑤スキーマ変更への追従が大変, 課題⑥効率よくクエリを実行するにはユーザがテーブルの物理構造を把握する必要がある
 (https://iceberg.apache.org/docs/latest/evolution/より)
(https://iceberg.apache.org/docs/latest/evolution/より)
Table sampleTable = ...;
sampleTable.updateSpec()
.addField(bucket("id", 8))
.removeField("category")
.commit();
- Sort order evolution
- Sortに使用するカラム、順序などを途中から変更することが出来る
Table sampleTable = ...;
sampleTable.replaceSortOrder()
.asc("id", NullOrder.NULLS_LAST)
.dec("category", NullOrder.NULL_FIRST)
.commit();
- hidden partitioning
- 各テーブルのDDLごとにきめ細やかなCopy-On-WriteとMerge-On-Readの組み合わせが可能 → 課題①レコードレベルの変更が非効率
- AWSもIcebergの公式紹介ページを公開している
- 以下の動画でNetflixによるIceberg開発の背景や自社でどのように活用しているかを紹介している
Delta Lake
- Databricksが開発したData Lake Table Format
- Hudi、Icebergと同じく様々な機能をサポート
- ただし、一部機能はDelta Engine(Databricksプラットフォーム)上でのみサポートされる点は注意が必要
Delta Lakeについてはktksqさんの「Delta Lake とは何か」で非常に詳しく解説されている。
ktksq.hatenablog.com
Apache Hudi, Apache Iceberg, Delta Lakeの比較
Apache Hudi, Apache Iceberg, Deltalakeの比較は以下の記事が参考になる。(dremioの記事は各フォーマットのコミッターの内訳なども分析していておもしろい)
Comparison of Data Lake Table Formats | Dremio Blog
Transactional Data Lakes — a Comparison of Apache Iceberg, Apache Hudi and Delta Lake | by Chouaieb Nemri | Geek Culture | Medium
Data Lake Table Format事例(見つけ次第追記予定)
- Gunosy: 更新できるデータレイクを作る 〜Apache Hudiを用いたユーザデータ基盤の刷新〜
- Yahoo: Apache Hudi を用いてレコード単位で削除可能なデータレイクを構築した話
- PayPay: Near Real-Time Data Lake at PayPay - Speaker Deck
- bilibili動画: How Bilibili Builds OLAP Data Lakehouse with Apache Iceberg | by Rui Li | Medium
- Trino Fest 2023(HudiやIcebergの事例が色々紹介されている):Trino Fest 2023 | Starburst
- Adobe
- さくらインターネット
参考ページ
Apache Iceberg: Architectural Insights | Dremio
https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Datalake-Format-On-AWS_0516_v1.pdf
How Apache Iceberg enables ACID compliance for data lakes | by Sumeet Tandure | Snowflake | Medium
https://conferences.oreilly.com/strata/strata-ny-2018/cdn.oreillystatic.com/en/assets/1/event/278/Introducing%20Iceberg_%20Tables%20designed%20for%20object%20stores%20Presentation.pdf