この記事は著者であるRui Li氏の許可を得て翻訳したものです。
Original article: How Bilibili Builds OLAP Data Lakehouse with Apache Iceberg | by Rui Li | Medium.
文中の注釈は、訳者(@_Bassari)が読者の理解を助けるために付け加えました。


はじめに
Bilibiliは中国最大級の動画共有サイトです。私たちはBilibiliのbig data infrastructureチームとして、2021年にApache Iceberg1を使用したlake-warehouseプラットフォームを構築するためのプロジェクトを開始しました。このプラットフォームは、主にOLAP分析シナリオに焦点を当てています。
このプロジェクトの前は、当社のdata warehouseはApache Hive2をベースにしていました。Apache Hiveを利用する中での課題として、クエリのパフォーマンスが、インタラクティブな分析の要件を満たせないことが頻発する問題がありました。そのため、私たちのプラットフォームのユーザー3は、Apache HiveからClickHouse4のような他のシステムにデータを同期させるための余分なETLタスクが頻繁に必要になっていました。これらのETLタスクは、メンテナンスコストとデータの冗長性を増加させます。このプロジェクトによって、私たちはインタラクティブな分析のコストを、完全になくすことはできないにしても、削減することを目指しました。
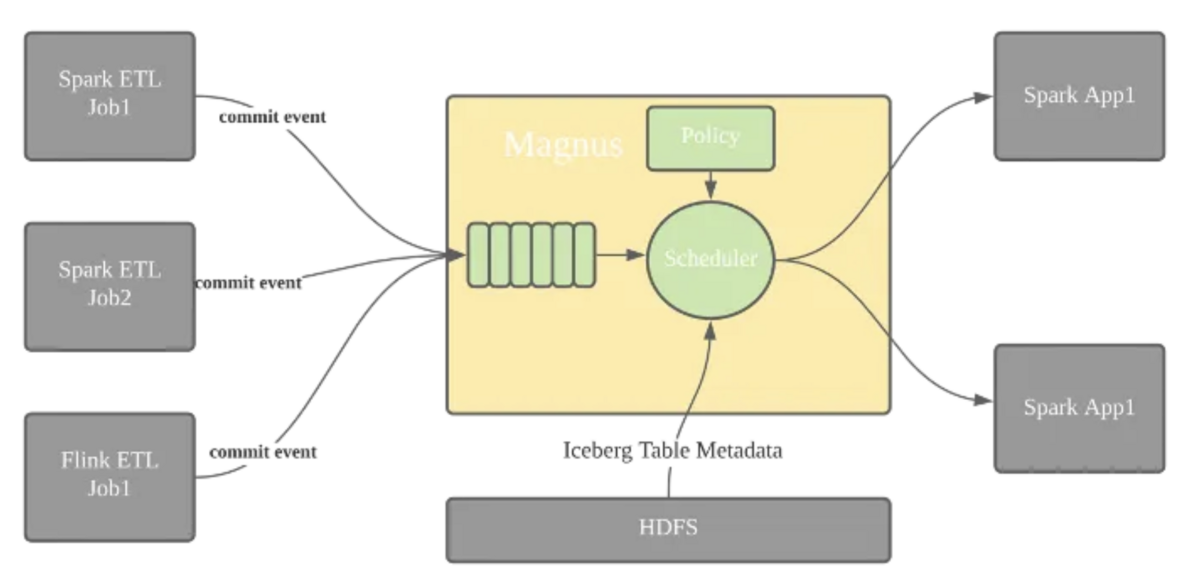
次の図は、我々のlake-warehouseプラットフォームの全体的なアーキテクチャを示しています。
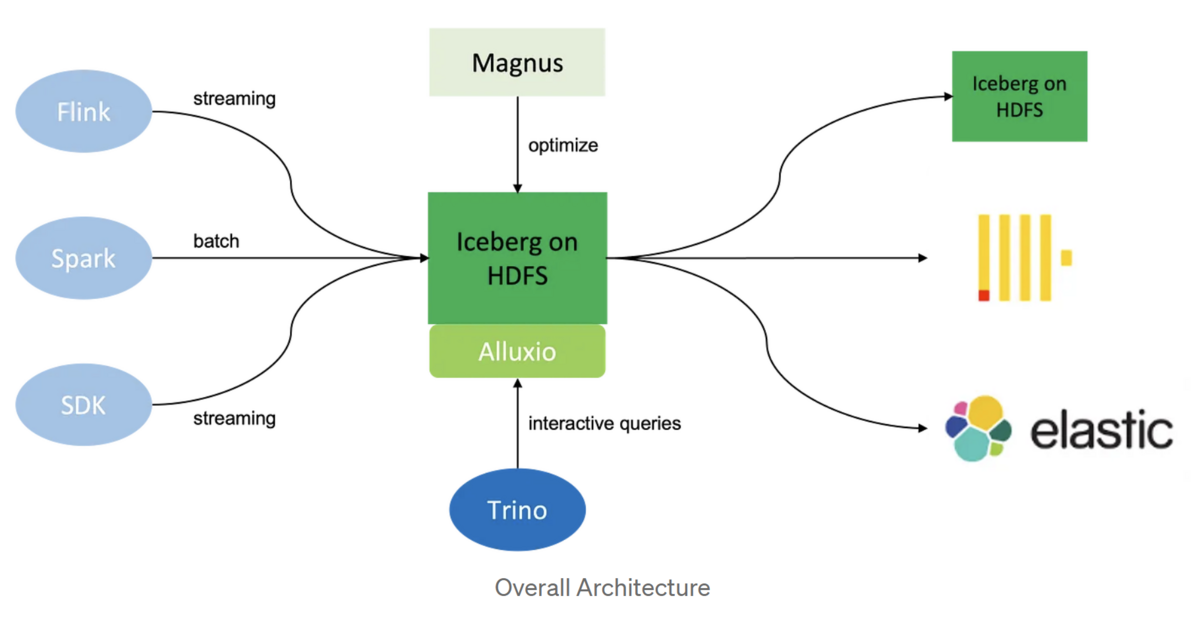
左から順に見ていきましょう。データの取り込みについては、Apache Spark5、Apache Flink6、そしてHDFS7上のIcebergテーブルにデータを書き込むためのJava SDKをサポートしています。いったんデータを取り込んだあと、Magnusというバックグラウンド・サービスが継続的にデータを最適化します。インタラクティブなクエリーを実行するための実行エンジンとしてはTrino8を選びました。さらに、データへのアクセスを高速化するためにAlluxio9を採用しました。最後に、データを別のIcebergテーブルや他のシステムにエクスポートして処理することもサポートしています。
この記事の残りは、クエリのパフォーマンスを向上させるために行った作業と、Magnusがどのようにこれらの最適化を実行するのに役立っているかに焦点を当てます。
データ分布の最適化
Apache Icebergはテーブルのメタデータにカラムの統計情報(カラム値の上限と下限など)を保持し、クエリプランニング時にデータファイルのフィルタリングに使用します。ここで、いくつかのカラムをソートした上でファイル間でデータを分散させると、これらのカラムに対するフィルタを使ったクエリでより多くのファイルをスキップできる可能性が高まります。10
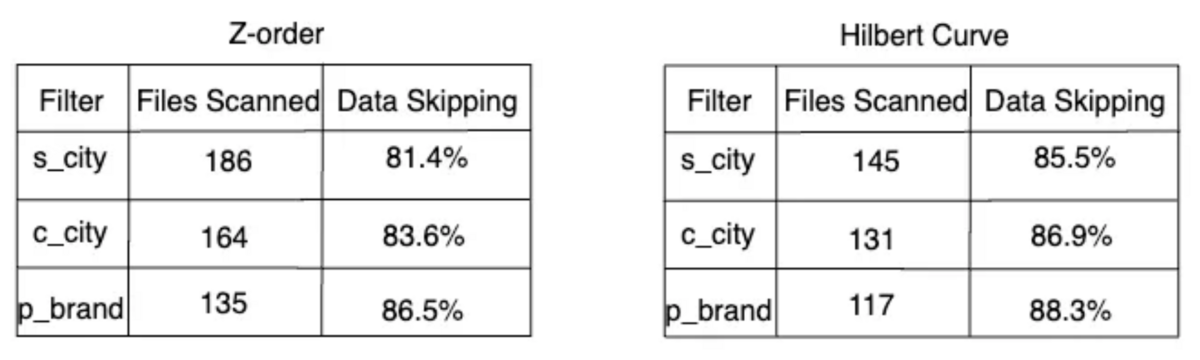
しかし、問題はソート対象となるカラムが複数ある場合(つまり、クエリが複数のカラムをフィルタする場合)、おそらく最初のカラムのデータスキップしか期待できないことです。SSB (star schema benchmark)の以下のクエリを例にしてみましょう。s_city、c_city、p_brandの3つのカラムをソートしてデータを分散させ、それぞれにフィルタリングをかけた3つのクエリを実行しました。その結果、スキャン対象のファイルをスキップできたのは最初のクエリだけでした。

この問題に対処するために、我々はZ-order11とヒルベルト曲線12を導入しました。両者とも複数のカラムをクラスタリングすることができる仕組みです。その上で先述と同じベンチマークを実施した結果、3つのクエリ全てでスキャン対象のデータをスキップできることを確認しました。
Data Skipping Index
Z-orderとヒルベルト曲線は複数のカラムに基づくクラスタリングをサポートしますが、カラムの数が増えるにつれて効果が減少します。基本的に、Z-orderとヒルベルト曲線では、4列以上を使用しないようユーザーにお勧めしています。
データをスキップするもう1つの方法はIndexで、特にカーディナリティが高い(ユニークな値の数が多い)カラムに使用します。このような列に対するIndexは、たとえデータがこれらの列によってクラスタリングされていなくても、ファイルをスキップすることができます。
私たちはIcebergテーブルにファイル単位のIndexを導入しました。ユーザーはテーブルに対して複数のIndexを定義できます。各Indexは、カラムに対して定義することも、カラムの変換(JSON文字列から特定のフィールドを抽出するなど)に対して定義することもできます。ほとんどの場合、Indexはdata fileと一緒に別のファイルとして保存され、メタデータはmanifest fileの各data fileに関連付けられています。Indexファイルが非常に小さい場合、たとえば数十KB しかない場合、manifest entryに埋め込むこともできます。
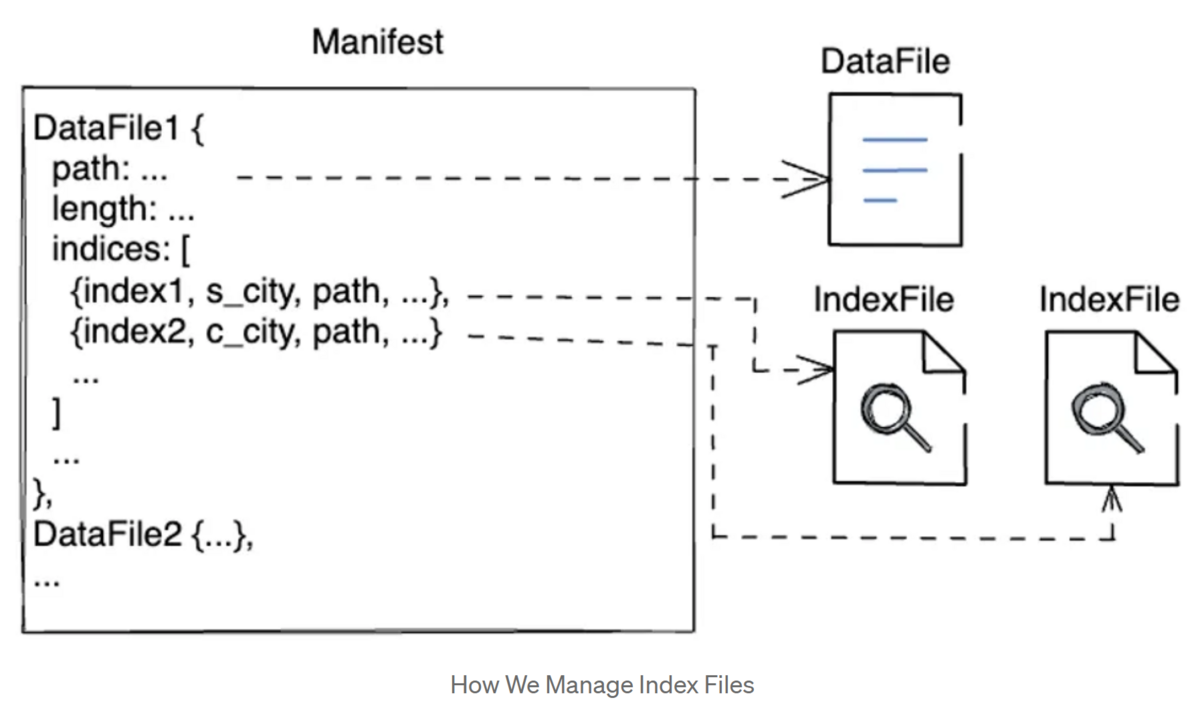
TrinoでIcebergのテーブルをクエリする際、manifest entryに埋め込まれたIndexはコーディネータ上でファイルのフィルタリングに使用され、Index fileはワーカー上で読み込まれます。
以下に、現在サポートしているIndexの種類を示します:
- Bloomfilter: シンプルで小さい。pointクエリで利用可能。誤検出の可能性あり13
- Bitmap: 比較的大きい。pointクエリとrangeクエリ14の両方で使用可能。誤検出なし。行番号を格納し、異なる列のマッチ結果を交差させることができる。マッチ結果はデータファイル内の行をスキップするためにも使用できる
- BloomRF: Bloomfilterに似ているが、rangeクエリでも使用可能
- TokenBloomfilter と TokenBitmap: ログ分析シナリオで使用される特別なインデックス。ログデータをトークン化して、それぞれ Bloomfilter と Bitmap インデックスを構築する
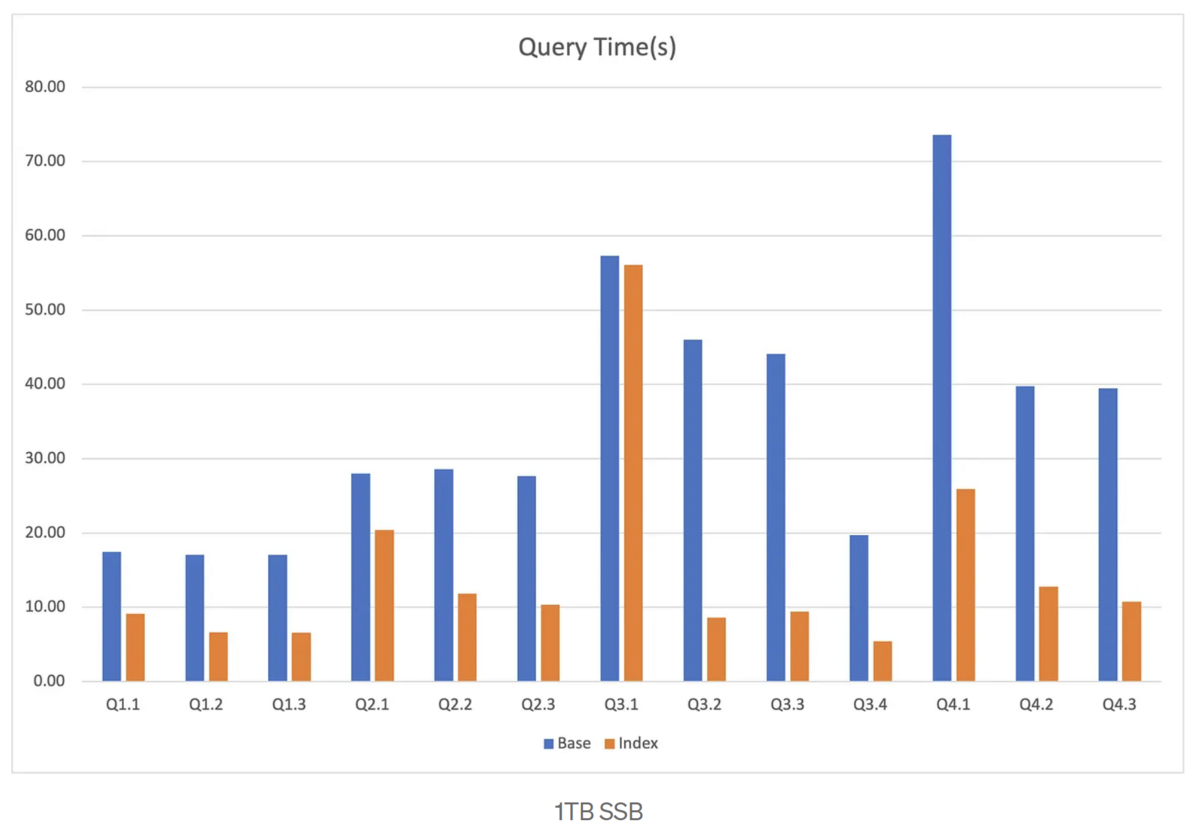
SSBを使用してデータ分布の最適化とIndexをテストした結果、ほとんどのクエリでかなりの改善が見られました。
Aggregation Index
Aggregation Index(略してAggIndex)は、集約を使った分析クエリの高速化を目的としています。
このアイデアは、集計結果を事前に計算してmaterializeし、ユーザー・クエリを自動的に書き換えて未加工データの代わりに事前に計算された結果を読み込むようにすることです。
ユーザーはテーブルに複数の AggIndex を定義できます。各 AggIndex は、基本的に以下2つのフィールドを定義します:
- ディメンション列: filter や group by で使用されるカラムは、ディメンションとして定義する
- 集約方式: 集約関数とその引数を定義する
例えばSSBの以下のクエリでは、ディメンション列が d_year、p_brand、s_region で、集約方式がsum(lo_revenue) である AggIndex を定義できます。
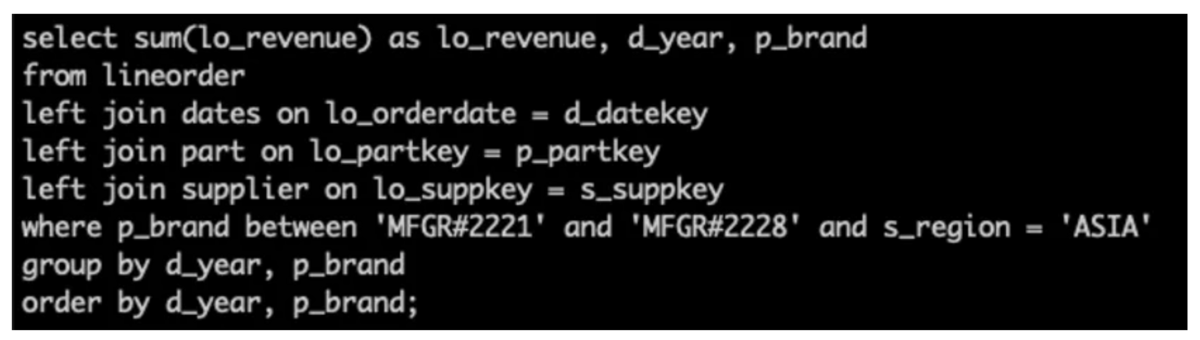
data skipping indexと同様に、AggIndexもファイル単位であり、メタデータはマニフェストの生のDataFileに関連付けられます。異なるファイルからの集計結果をマージできるように、AVG や PERCENTILE のような特定の集計関数の内部状態を保存します。
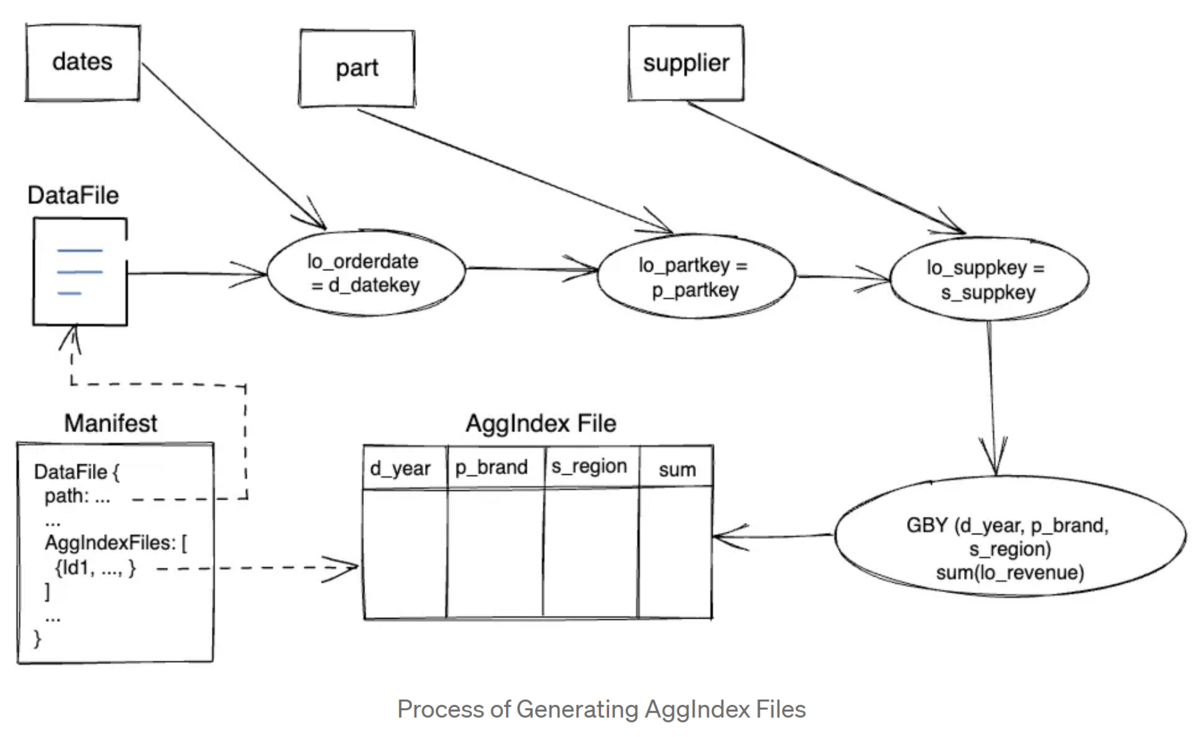
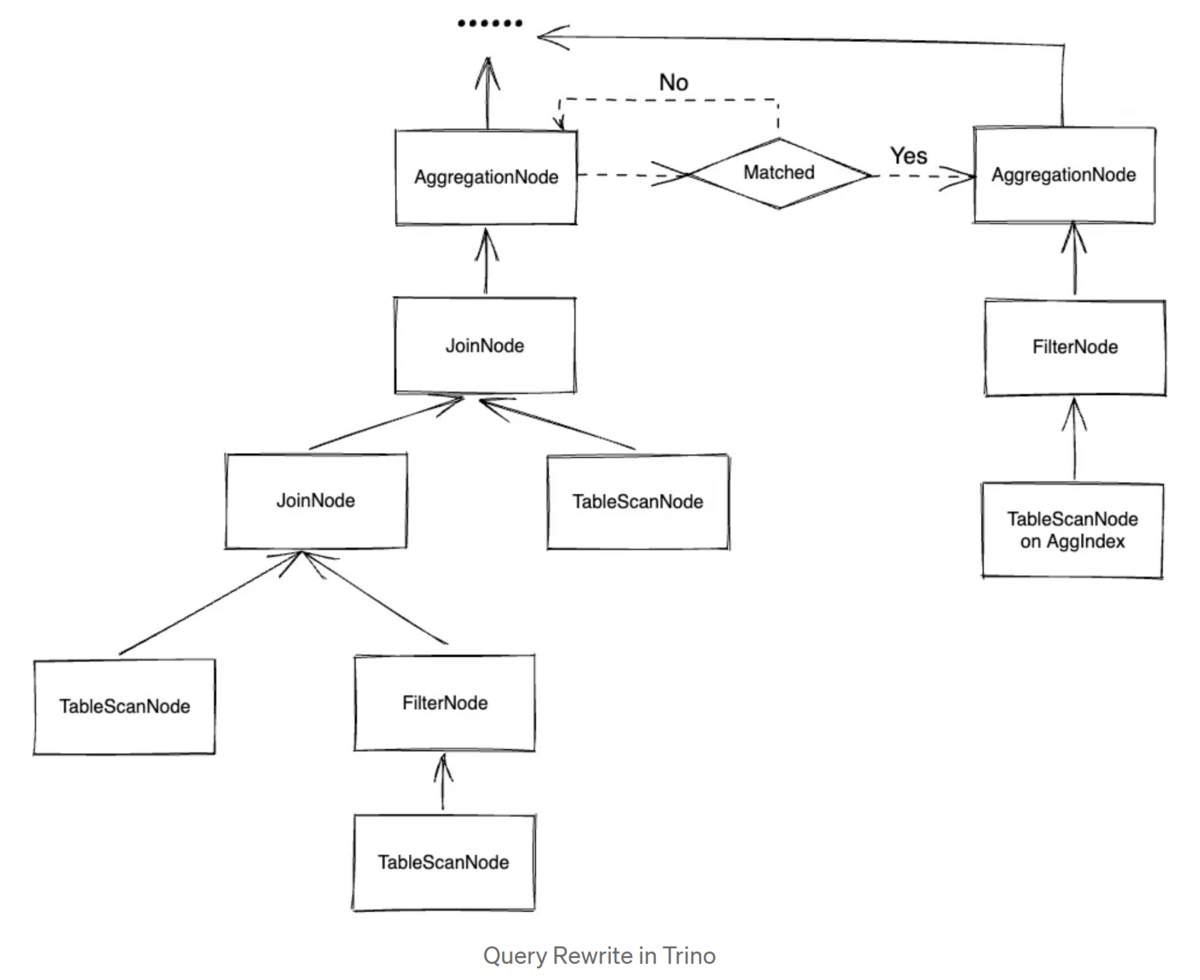
クエリ時に、論理プランとAggIndex定義をマッチさせる最適化ルールをTrinoに実装しました。有効なAggIndexが見つかったら、テーブルスキャン中にAggIndexファイルを読み込むように論理計画を修正します。
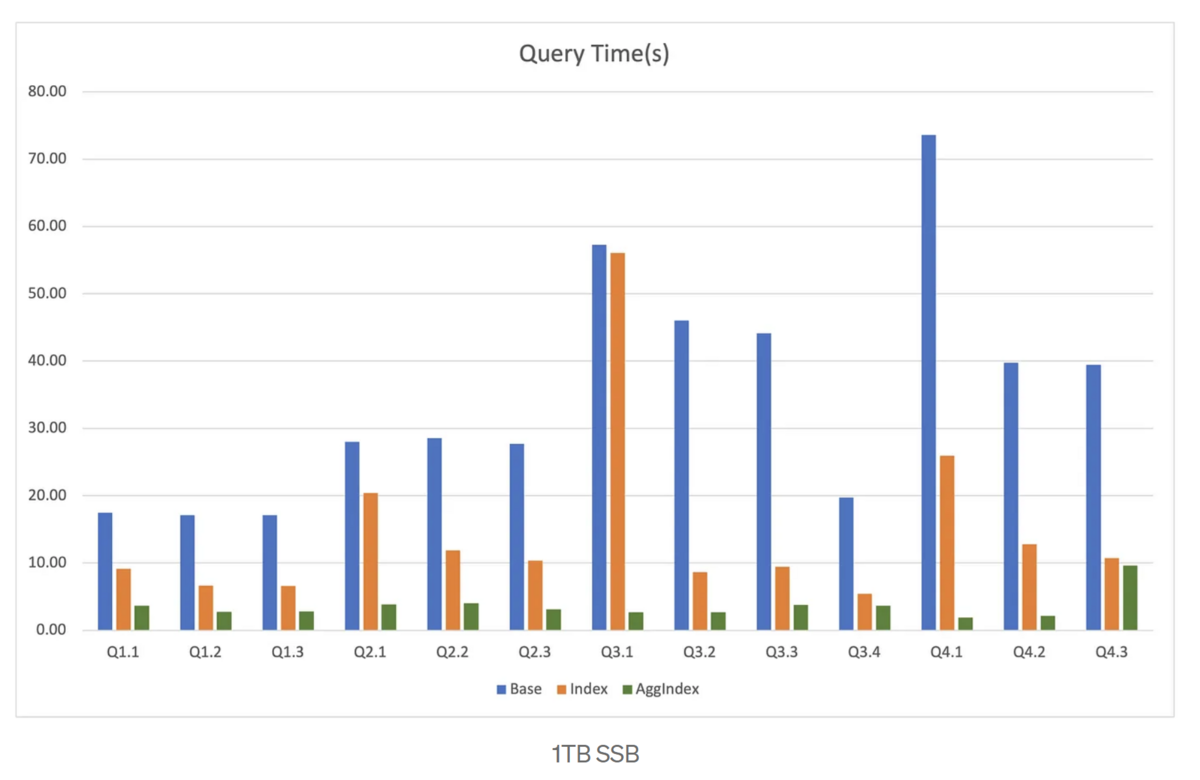
SSBの結果は、AggIndexがクエリーパフォーマンスをさらに向上させることを示しています。
Magnus
Apache Icebergは単にテーブル・フォーマットであるため、すべてのIcebergテーブルを管理し、これまでに述べた最適化を実施する仕組みとしてMagnusというサービスを実装しました。
Magnusには3つの主要な責務があります。最も重要なのは、Icebergテーブルのコミットイベントをサブスクライブし、データ分布の最適化や、indexの構築、AggIndexの構築、スナップショットの期限切れ管理などの最適化ジョブをスケジュールすることです。
次に、Magnusはデバッグに役立つテーブルの内部状態を公開するWeb UIを提供します。例えば、パーティション内で最適化されたファイルの数を知ることができ、あるクエリの実行が遅い理由を説明するのに役立ちます。
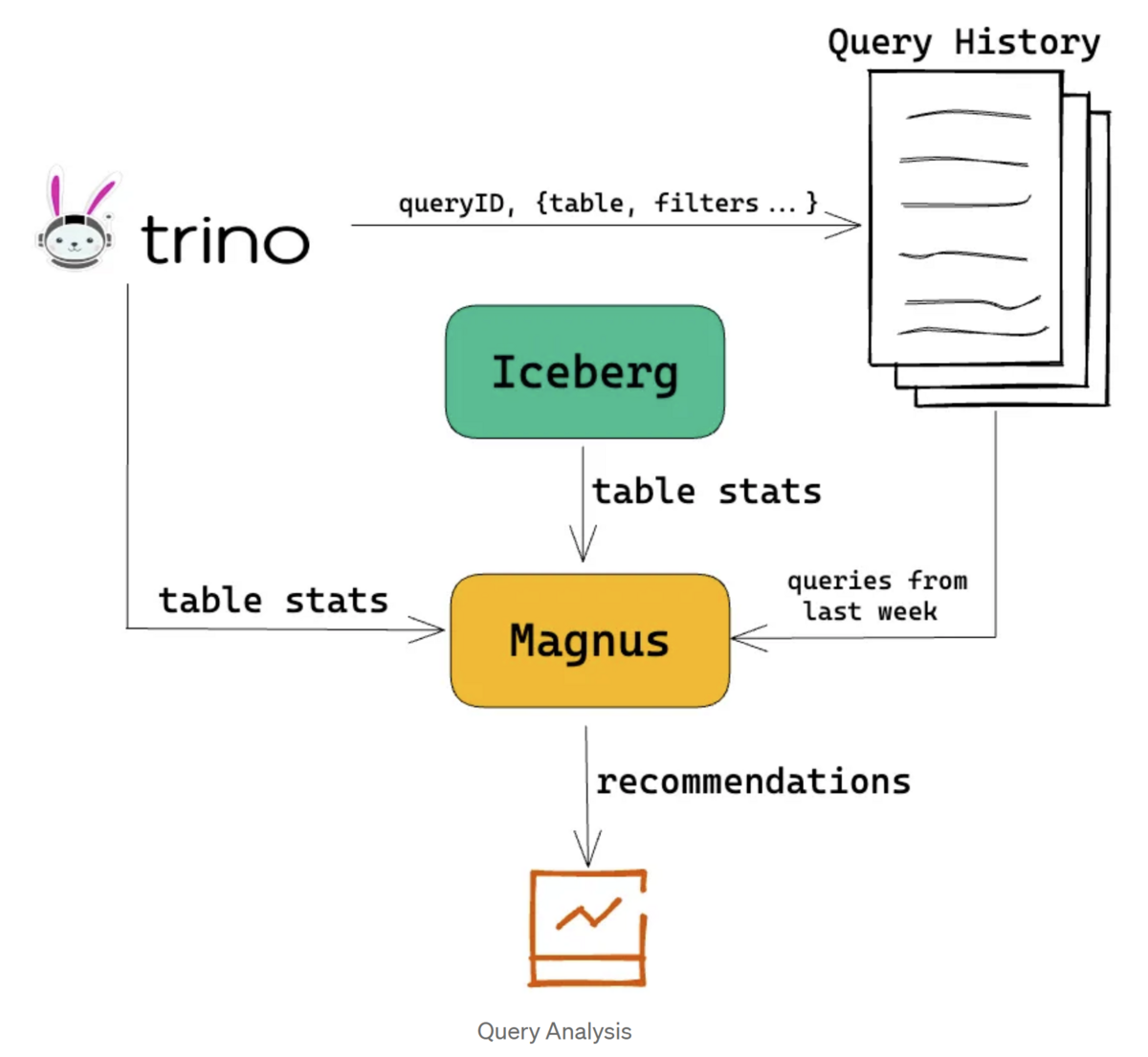
最後に、Magnusは定期的にクエリ履歴を分析し、より良いテーブル構成を見つけます。例えば、あるカラムが過去1週間のクエリフィルタで頻繁に使用されている場合、そのカラムを分散カラムとして追加したり、そのカラムにindexを定義したりすることをユーザーに提案できます。
結論
現在、私たちのData Lakehouseには1000以上のIcebergテーブルがあり、総データサイズは10PB、1日の増分データサイズは75TBです。Trinoは毎日20万以上のクエリを処理していて、レスポンスタイムは95パーセンタイルで約5秒です。Apache HiveからApache Icebergに移行することで、私たちのユーザーのほとんどは、インタラクティブなクエリのためにデータを他のシステムにエクスポートする必要がなくなりました。
明確に定義されたOpen Table Formatのおかげで、私たちのプロジェクトはApache IcebergをOLAPプラットフォームの構築に使用できることを証明しており、コスト削減とユーザー・エクスペリエンスの向上に役立っています。
- Apache Icebergは、大規模なデータセットのためのオープンソースのOpen Table Format。僭越ながら弊ブログでも関連記事を出しております:Apache Iceberg とは何か - 流沙河鎮 、データレイクの新しいカタチ:Open Table Formatの紹介 - 流沙河鎮↩
- Apache Hiveは、Hadoop上でのデータウェアハウス機能を提供し、SQLライクな言語(HiveQL)を使用して大規模なデータセットに対するクエリ操作をサポートする↩
- 興味深い点として、原文ではプラットフォームのユーザーを「our customers」と表現している↩
- ClickHouseは、高速でスケーラブルなオープンソースの列指向データベース管理システム↩
- Apache Sparkは、大規模データ処理のためのオープンソース分散コンピューティングシステム↩
- Apache Flinkは、ストリームとバッチデータの処理のためのオープンソースの分散ストリーミングプロセスフレームワーク↩
- Apache Hadoopは、大規模データ処理のためのオープンソースフレームワークであり、分散ストレージ(HDFS)と分散コンピューティング(MapReduce)のコンポーネントから構成される↩
- Trinoは、高速で分散型のSQLクエリエンジンであり、多様なデータソースに対して単一のクエリインターフェースを提供する↩
- alluxioは、カリフォルニア大学バークレー校が開発した分散インメモリストレージ↩
- 例えば、カラムの1つにポケモンの名前が入った、複数のparquetファイルで構成されるテーブルがあるとする。もしピカチュウに関するデータを参照するクエリを実行する場合、ピカチュウがレコードに含まれるファイルが1つしかなかったとしても、全てのparquetファイルをスキャンしなければならないので計算コストが増加する。そこで、テーブルをポケモンの名前でソートすれば、クエリエンジンはピカチュウが含まれ得るファイルの範囲を特定することができるため、スキャン対象のデータを削減(スキップ)し、性能向上を図ることが出来る↩
- Z-Orderは、多次元データを一次元にマッピングする手法の一つで、各次元のビットを組み合わせて一次元の値に変換することで大量の空間的なデータを効率的にストレージに保存したり、クエリを高速に実行するためのインデックスとして使用される。IcebergにおけるZ-OrderについてはHow Z-Ordering in Apache Iceberg Helps Improve Performance | Dremioに詳しい↩
- IcebergのHilbert curveは2023/09/30現在未サポート(将来的に対応予定)であるため、これはBilibiliオリジナルと思われる。ロードマップの詳細はZ-Order Proposal - Google ドキュメントを参照↩
- ブルームフィルター(Bloom Filters)は、ある要素が集合に含まれているかどうかを高速に判定するためのデータ構造で、集合の中に特定の要素が存在するかどうかを効率的にチェックできる。特徴として、要素が「存在しない」ことに関しては確実に判定できる一方で、要素が「存在する」ことに関しては誤った判定をする場合がある(偽陽性)↩
- pointクエリは特定のキーまたは値に基づいてデータベースから単一のエントリやレコードを取得するクエリを指し、rangeクエリはデータベースの特定の範囲のレコードを取得するクエリを指す↩