- はじめに
- Icebergテーブルのアーキテクチャ
- Icebergの同時実行制御のコンセプト
- Icebergの書き込み処理の流れ
- 同時書き込み時のシナリオパターン
- データ競合チェック
- データパイプライン設計時の注意点
- まとめと宣伝
- おまけ(ソースコードベースの流れ)
はじめに
Apache Icebergテーブルは、テーブル単位、オペレーション単位のトランザクション分離レベルとしてserializableとsnapshotをサポートしています。(デフォルトはserializable).つまり、同時に複数のトランザクションが同じテーブルに書き込んだ場合でもデータの一貫性を確保できます。
Icebergのアーキテクチャをある程度ご存じの方であれば、Icebergカタログに登録されたロケーションのアトミックな更新であるとか、楽観的並行性制御といった仕組みが何となく関係していることを聞いたことがあるかもしれません。一方で、同時実行制御が具体的にどのようなフローで行われているかについての情報は世の中にまとまった情報が少ないように思います。
普段皆さんがIcebergを活用する上では、同時実行制御の詳細を意識する場面は少ないはずです。しかし、同時書き込みの競合が多発するような状況、例えばストリームの書き込みと継続的なテーブルのコンパクションが競合する場面では、仕組みを理解しておくことがより良い設計、運用に繋がります。
そこで本ポストでは、これを実現するためのIcebergの競合解決の仕組みを解説すると共に、その注意点についても紹介します。
Icebergテーブルのアーキテクチャ
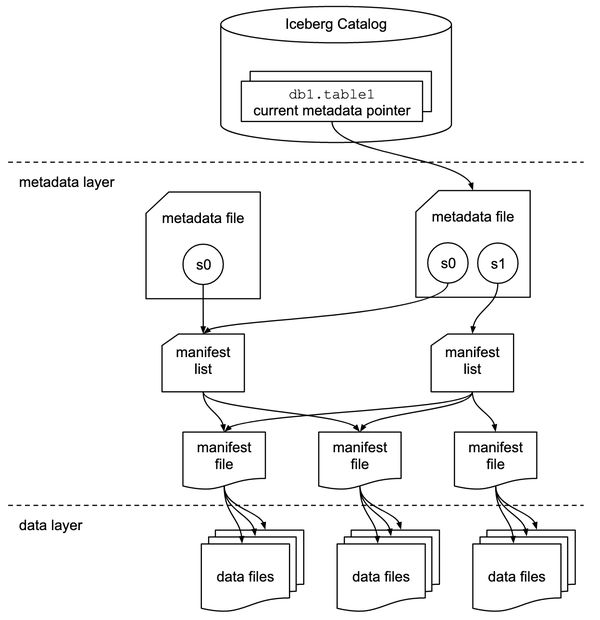
IcebergテーブルはIceberg Catalog(カタログ)、メタデータレイヤー、データレイヤーの3階層で構成されています。
 .
.
ここで、同時実行制御を考える上で特に重要となる要素はカタログとmetadata file(メタデータファイル)です。
メタデータファイルにはテーブルのある時点の状態に関する全ての情報のメタデータが保管されています。カタログには各テーブルのある時点での最新のメタデータファイルのロケーション(ストレージ上の場所)が登録されています。
テーブルを参照するクライアントはカタログを見に行くことで、メタデータファイルの場所を把握し、それを辿ることでテーブルについての最新の情報を得ることができます。
また、テーブルを更新するクライアントは、本ポストで説明する競合解決が実施した上で、カタログ上のロケーションを更新することになります。通常カタログはロケーション情報のアトミックなコミット(更新)をサポートしており、同時に複数のクライアントがロケーションの更新を試みた場合でも、どちらかの更新のみを成功させるようになっています。
Icebergテーブルのアーキテクチャの詳細については、以下の記事を参照してください。
Icebergの同時実行制御のコンセプト
Icebergの同時実行制御のコアとなるコンセプトは、MVCC(多版型同時実行制御)と楽観的並行性制御です。
読み取りに関しては、各トランザクションはスナップショットとしてバージョン管理されており、書き込み処理が行われている最中に読み取りが実施された場合でも、リーダーはコミット済のスナップショットを一貫して参照できます。これはMVCCのコンセプトに基づいています。
書き込みに関しては、ライターは事前にテーブルロックは実施することはせず、一連の書き込み処理が完了後、更新時に競合を確認してコミットを試みます。これは楽観的並行性制御のコンセプトに基づいています。
本エントリでは、後者の書き込み時の同時実行制御の具体的な仕組みを説明します。
Icebergの書き込み処理の流れ
 .
.
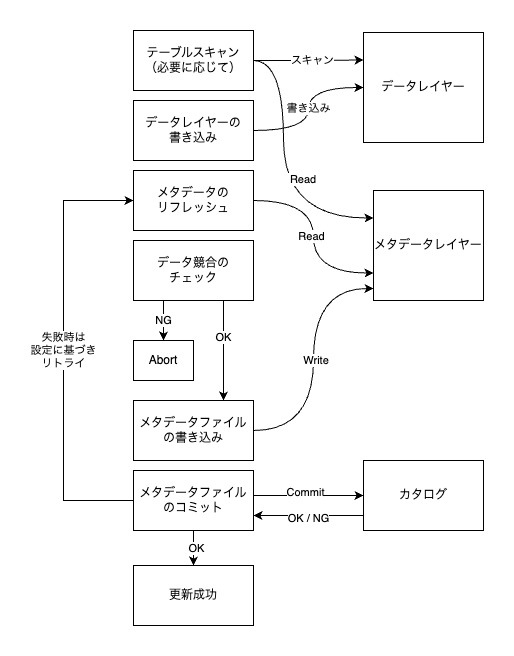
Icebergテーブルへの書き込みは、大きく以下のステップで進行します:
- テーブルスキャン: テーブルの最新の状態を読み取る(テーブルの既存データに依存しないINSERTなどのオペレーションでは不要)
- データレイヤーの書き込み: 更新内容に基づいてデータファイルと削除ファイルを書き込む
- メタデータのリフレッシュ: 最新のメタデータを読み込み
- データ競合のチェック: 書き込み対象のデータと、3で読み込んだ最新のスナップショットの競合をチェックする。チェック内容は書き込みの設定がsnapshotかserializableかで変化する。競合チェックに失敗した場合は、アボートする。(リトライはできない)
- メタデータレイヤーの書き込み: 競合がない場合、新しいメタデータファイルを作成する
- メタデータファイルのコミット: カタログに新しいメタデータファイルのロケーションを登録する。この操作はCompare-and-Swap (CAS)で実行され、他のトランザクションと競合した場合は失敗する可能性がある。失敗した場合、テーブルのプロパティ設定に基づいてリトライを実施する。
特に注目すべき点として、
- 最初のテーブルスキャン時に参照したメタデータファイルと、メタデータファイルのコミット時に基にするメタデータファイルは同じである必要はありません。書き込みの元になるメタデータファイルは、メタデータのリフレッシュ時点で確定します
- データ競合のチェック内容は書き込み設定がserializableの場合とsnapshotの場合で変化します
- write.delete.isolation-level
- write.update.isolation-level
- write.merge.isolation-level
- データ競合のチェックに失敗した場合、処理はアボートし、リトライされません。これはデータの整合性を確保するために必要な措置ですが、継続的な書き込みトランザクションとコンパクションのトランザクションが同時に実行されるようなケースでは課題になる可能性があります(後述)
- メタデータファイルのコミットに失敗した場合、テーブルのコミットリトライ関連のプロパティの設定値に基づいてリトライが行われます
- commit.retry.num-retries(default 4): 失敗時にコミットを再試行する回数
- commit.retry.min-wait-ms(default 100): コミットを再試行するまでの最小待機時間(ミリ秒)
- commit.retry.max-wait-ms(default 60000, 1分):コミットを再試行するまでの最大待機時間(ミリ秒)
- commit.retry.total-timeout-ms(default 1800000, 30分): コミットの再試行の合計タイムアウト時間(ミリ秒)
同時書き込み時のシナリオパターン
2つのトランザクション(tx1, tx2)が同時に実行された場合、競合のパターンによって以下の挙動となります。
- tx1がスキャン後、メタデータをリフレッシュする前にtx2がコミットした場合
- tx1はデータ競合のチェックが通過する限りにおいて、tx2がコミットしたスナップショットを元にメタデータファイルをコミットします。
- データ競合のチェックに失敗した場合はアボートします。
- tx1がメタデータをリフレッシュした後、コミット前にtx2がコミットした場合
データ競合チェック
なぜデータ競合のチェックが必要か?
前述のように、Icebergではカタログがアトミックなコミット(Compare-and-Swap)を行うため、テーブルメタデータファイルの更新同士が物理的に衝突することはありません。しかし、その更新が内容的に競合しているかは別問題です。例えば同じファイルや同じ行を異なるトランザクションが同時に更新しようとした場合や、あるトランザクションが論理的には削除済みのデータを別のトランザクションが再度書き込む(“論理的にはもう存在しないはずのデータ”に対して操作を行う)など、データの不整合や重複が起きないようにする必要があります。
Icebergはメタデータベースのバリデーション機構を通じて、以下のような衝突を防ぎます。
- 同じデータファイルに対して複数の書き込み操作が発生する
- 論理的に削除されたデータを、別トランザクションが再利用してしまう
- 同じ条件でアップデートや削除を実行する複数のトランザクションが同時に動作する …など
データ競合チェックで競合が検出された場合、Icebergはリトライを実施せず、処理をアボートさせます。一見するとスキャンの段階からリトライを行えばよさそうにも感じるかもしれません。しかし、単純にリトライを実施してしまうと、別のトランザクションによって更新の前提となる情報が変更されているため、データの論理的な整合性が破壊される可能性があります。
例えば、あるテーブル employee が以下のレコードを持っているとします。ここでは、すべてのレコードが同一のデータファイルに保存されているものとします。
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 3000 |
| 2 | Bob | Sales | 4000 |
| 3 | Charlie | Marketing | 3500 |
2つのトランザクション(tx1, tx2) が同時に動作し、以下のような操作をしたとします。
トランザクション
tx1- 「id=2(Bob)の
departmentを 'Marketing' に変更する」(= SalesからMarketingへ異動扱いにする)。
sql UPDATE employee SET department = 'Marketing' WHERE id = 2
- 「id=2(Bob)の
トランザクション
tx2- 「Sales 部門の社員を一律10%昇給する」。
sql UPDATE employee SET salary = salary * 1.1 WHERE department = 'Sales'
- 「Sales 部門の社員を一律10%昇給する」。
ここで、tx1 (Bobの部門変更)が先にカタログへのコミットを完了したとします。
| id | name | department | salary |
|---|---|---|---|
| 1 | Alice | Sales | 3000 |
| 2 | Bob | Marketing | 4000 | ← ここが変更 |
| 3 | Charlie | Marketing | 3500 |
一方の tx2 は、当初「department = 'Sales' に該当するレコード」をスキャンしていました。そこでは id=1 (Alice), id=2 (Bob) の2名が該当すると認識しているわけです。
しかしコミット直前にメタデータをリフレッシュすると、「id=2 (Bob) の department は既に 'Marketing' に変わっている」という最新の状態を読み込むことになります。Icebergのデータ競合チェック機構は、こうした不整合を検出します。
この状況では、先述した書き込みフローのうち、メタデータのリフレッシュとテーブルのスキャン、どちらの段階からもデータの整合性を担保しながら更新することができません。
メタデータのリフレッシュからのリトライが機能しない理由
テーブルのスキャンからのリトライが機能しない理由
tx2が最新スナップショットを再スキャンして、トランザクションを再構築することで更新対象を決め直したとします。 ここで、Bob はすでにMarketing部門なのでtx2の実行を開始した時点での「department = 'Sales'」の条件に当てはまりません。 結果、昇給の対象はid=1 (Alice)のみになり、昇給幅もクエリ実行時の当初の想定(Sales 2名分)から変わってしまいます。従って、このアプローチではテーブルデータの論理的な整合性は担保されるものの、更新内容が処理の意図に沿う内容であるかについて、判断が必要になります- ただし、競合の内容によっては、リトライが整合性を破壊しないシナリオも十分にあり得ます(UPDATEとコンパクションの競合など)
主要なオペレーションで実施されるバリデーション
Icebergには4つの主要オペレーションがあり、それぞれで競合チェック(バリデーション)の内容が異なります。
- AppendFiles (APPEND)
- データファイルを追加する(新規INSERT)
- IcebergはPK(Primary Key)をネイティブにサポートしておらず、重複排除や重複書き込み自体は制御しません。従って、Append同士の競合チェックは行われません。
- OverwriteFiles (OVERWRITE)
- Copy-on-Write方式による行単位更新/削除(UPDATE/DELETE)
- 古いファイルを論理的に削除し、新しいファイルに置き換える
- RowDelta (OVERWRITE)
- Merge-on-Read方式による行単位更新/削除(UPDATE/DELETE)。
- 追加のデータファイルや削除ファイル(position/equality delete)を書き込む。
- RewriteFiles (REPLACE)
- 既存のデータファイル群を物理的に再構成(コンパクションやクラスタリング)するための操作。
- データの内容自体は変えず、冗長なファイルをまとめたり、より効率的な形へ再書き込みする。
- いわゆる「コンパクション」
これらのオペレーションには、それぞれ特有のバリデーションチェックが組み込まれています。以下では代表的なバリデーションの例を取り上げ、どのような競合シナリオを防ぐのかを解説します。
AppendFiles
AppendFilesはテーブルに新しいデータファイルを「追加する」だけなので、データ競合のチェックは行われません。 ただし、他のオペレーション(特に行更新/削除を行うOverwriteFilesやRowDelta)から見ると、AppendFilesで追加されたファイルが自分のターゲット範囲に含まれるかどうかをチェックする場合があります(後述の「Added data file validation」など)。 Iceberg自体はPKを持たないため、同じ行が重複して挿入される可能性は排除しません。
OverwriteFiles (Copy-on-Write 更新/削除)
OverwriteFilesは既存のファイルを論理的に削除し、新しいファイルを追加する操作です。これによってUPDATEやDELETEを実現します。このとき、次のようなバリデーションを通じて競合を検知します。
- Fail missing delete paths validation
- 「論理的に削除しようとしているファイルが、実際にまだテーブルに存在するか」をチェックします。
- OverwriteFilesのコミット直前に最新メタデータを読むと、すでに別のオペレーションがそのファイルを削除済みの場合があります。そのファイルがもはや存在しない(=manifestに現れない)とき、このチェックで競合が検知され、アボートします。
- OverwriteFilesが他のOverwriteFilesやRewriteFiles(コンパクション)などと競合するときに特に重要です。
- No new deletes for data files validation
- 直近のスナップショットで新たにdeleteファイル(position/equality)が追加されていないかをチェックします。
- OverwriteFiles(COW)の観点では、自分が論理削除しようとしているファイルが、Merge-on-Read(RowDelta)で追加されたdeleteファイルによって既に更新されていないかを検証し、競合を防ぎます。
- Added data file validation
- 直近のスナップショットで、新たに追加されたデータファイルが自分のクエリ範囲と重複していないかをチェックします。
- serializable 分離の場合のみ実施されます
RowDelta (Merge-on-Read 更新/削除)
RowDeltaは新たなデータファイル(差分)や削除ファイルを追加します。これにより行レベルのUPDATE/DELETEを実装し、テーブル上の元ファイルは物理的には更新せず、「削除ファイルや新データファイル」で差分を表現します。ここで主に行われるバリデーションは以下のとおりです。
- Data files exist validation
- 自分が追加しようとしている削除ファイルが参照するデータファイルが既に論理削除されていないかを確認します。
- もし別のOverwriteFilesやRewriteFilesが先に同じファイルを削除していた場合は競合が発生し、アボートします。
- No new delete files validation
- 自分がスキャンした後のスナップショットで追加された新たなdeleteファイルが、自分の更新/削除対象と重ならないかをチェックします。
- 例えば、同じ行を別トランザクションがDeleteしているのに、自分は更新用のdeleteファイル+新データファイルを作ろうとしているなどのケースを防ぎます。
- Added data file validation
- OverwriteFilesの場合と同様に、「同時に追加されたファイルが自分の対象範囲と重なるかどうか」の確認です。
serializable 分離の場合のみ実施されます
RewriteFiles (REPLACE: コンパクション)
RewriteFilesはファイルの物理再構成のため、いくつかの既存ファイルをまとめて新しいファイルに置き換えます。この操作でも競合防止のために以下のバリデーションが行われます。
Fail missing delete paths validation
- OverwriteFilesのケース同様、同時実行下で「すでに削除されているファイルを自分が対象に含んでいないか」をチェックします。
- No new deletes for data files validation
- Merge-on-Read(RowDelta)などで削除ファイルが追加されていないかを確認し、競合を防ぎます。
RewriteFilesは論理的にデータを変更するわけではありませんが、他のOverwriteFilesやRowDeltaの操作と衝突してしまう可能性があるため、これらのバリデーションが必要になります。
バリデーションの種類
先述のバリデーションを、観点別に整理すると以下のようにまとめられます。
- Fail missing delete paths validation
- 「削除しようとしているデータファイルが、まだテーブルに存在しているか」をチェック。
- OverwriteFiles/RewriteFilesで実行される。
- No new deletes for data files validation
- 「他のトランザクションが追加したdeleteファイルと衝突していないか」をチェック。
- OverwriteFiles/RewriteFiles→RowDeltaなどとの競合を防ぐ。
- Added data file validation
- 「他のトランザクションが追加したデータファイルと自分の更新対象(クエリフィルタ)に重複が無いか」をチェック。
- serializable Isolationにおいて有効。snapshot Isolationの場合は無効化されることが多い。
- Data files exist validation (RowDelta特有)
- 「RowDeltaが追加するdeleteファイルの参照先が、まだテーブル上に存在しているか」をチェック。
- OverwriteFiles/RewriteFilesで既に削除済みのファイルを参照しないように防ぐ。
また、パーティション列や列統計情報(min/maxなど)を活用したフィルタプッシュダウンにより、「自分と関係ないデータファイルへの操作は競合しない」と判定するような最適化も行われます。
データパイプライン設計時の注意点
Icebergを使ったデータパイプラインを設計する上では、特にデータ競合チェックの性質を正しく理解して設計する必要があります。
例えばSparkでデータパイプラインを構成する場合に、ジョブが更新系の処理を含む場合、競合チェックによってジョブが失敗する可能性があります。
この時のリカバリーに適切な方法は、ジョブの処理内容やデータの性質に依存します。先述の例で挙げたような、順序性が問題になるトランザクションである場合、ジョブや更新処理の単純なリトライは整合性を壊してしまうかもしれません。
一方で、ジョブや更新処理のリトライが整合性を破壊しないシナリオも多くあり得ます。(実務的にはこうしたシナリオの方が多いかもしれません)
例えば、ストリーミングデータの継続的な書き込みと、コンパクション処理が競合するようなケースが考えられます。ここでストリームデータの書き込みが失敗した場合は、書き込み処理をリトライするのが望ましいリカバリー方法になるはずです。ここで、Sparkのジョブ全体が失敗してしまうと効率が悪いので、例外をハンドルしてクエリを再試行するような実装も検討する必要があります。
また、ジョブ全体を再試行する場合でも、更新処理だけを再試行する場合でも、処理全体の冪等性を考慮して設計することが重要になります。(これは本件に限った議論ではありませんが)
その他、要件が許すようであれば、コンパクション処理の対象をwhereオプションで古いデータに絞ることで、新規データの更新処理との競合を発生しづらくするような対策も有効です。
まとめと宣伝
本エントリでは、Icebergの同時実行制御における競合解決の仕組みと注意点を解説しました。Icebergテーブルどのようにしてserializable / snapshot分離をサポートするかを理解する一助になれば幸いです。 また、更新とコンパクションが競合した場合のハンドリングについては、Icebergのライブラリ側でのよりスマートな解決策もあり得るように思われるので、改善に向けたPRの余地を検討しています。
[宣伝] 2025/2/21のApache Icebergミートアップにて、「(仮) Icebergにおける同時実行制御の仕組みと注意点」と題して本エントリで紹介した内容を更に掘り下げて発表予定です。
本イベントは、日本のApache Icebergコミュニティの記念すべき初めてのミートアップで、光栄にも登壇者の一人としてお声がけいただきました。
発表ではIcebergライブラリの実装の解説、オペレーション別の競合チェックのさらなる詳細、より実践的な設計/実装上の考慮点とアイデアなどをご紹介できたらと思いますので、ぜひご参加いただけますと幸いです!
Apache Iceberg Japan Meetup #1 - connpass
おまけ(ソースコードベースの流れ)
コードベースで処理の流れを追いたい人向けに、CopyOnWriteOperationを例としてコミットまでの流れを載せておきます。
private class CopyOnWriteOperation extends BaseBatchWrite { @Override public void commit(WriterCommitMessage[] messages) { OverwriteFiles overwriteFiles = table.newOverwrite(); List<DataFile> overwrittenFiles = overwrittenFiles(); int numOverwrittenFiles = overwrittenFiles.size(); for (DataFile overwrittenFile : overwrittenFiles) { overwriteFiles.deleteFile(overwrittenFile); } int numAddedFiles = 0; for (DataFile file : files(messages)) { numAddedFiles += 1; overwriteFiles.addFile(file); } // the scan may be null if the optimizer replaces it with an empty relation (e.g. false cond) // no validation is needed in this case as the command does not depend on the table state if (scan != null) { if (isolationLevel == SERIALIZABLE) { commitWithSerializableIsolation(overwriteFiles, numOverwrittenFiles, numAddedFiles); } else if (isolationLevel == SNAPSHOT) { commitWithSnapshotIsolation(overwriteFiles, numOverwrittenFiles, numAddedFiles); } else { throw new IllegalArgumentException("Unsupported isolation level: " + isolationLevel); } } else { commitOperation( overwriteFiles, String.format("overwrite with %d new data files (no validation)", numAddedFiles)); } }
@Override protected void validate(TableMetadata base, Snapshot parent) { if (validateAddedFilesMatchOverwriteFilter) { PartitionSpec spec = dataSpec(); Expression rowFilter = rowFilter(); Expression inclusiveExpr = Projections.inclusive(spec).project(rowFilter); Evaluator inclusive = new Evaluator(spec.partitionType(), inclusiveExpr); Expression strictExpr = Projections.strict(spec).project(rowFilter); Evaluator strict = new Evaluator(spec.partitionType(), strictExpr); StrictMetricsEvaluator metrics = new StrictMetricsEvaluator(base.schema(), rowFilter, isCaseSensitive()); for (DataFile file : addedDataFiles()) { // the real test is that the strict or metrics test matches the file, indicating that all // records in the file match the filter. inclusive is used to avoid testing the metrics, // which is more complicated ValidationException.check( inclusive.eval(file.partition()) && (strict.eval(file.partition()) || metrics.eval(file)), "Cannot append file with rows that do not match filter: %s: %s", rowFilter, file.location()); } } if (validateNewDataFiles) { validateAddedDataFiles(base, startingSnapshotId, dataConflictDetectionFilter(), parent); } if (validateNewDeletes) { if (rowFilter() != Expressions.alwaysFalse()) { Expression filter = conflictDetectionFilter != null ? conflictDetectionFilter : rowFilter(); validateNoNewDeleteFiles(base, startingSnapshotId, filter, parent); validateDeletedDataFiles(base, startingSnapshotId, filter, parent); } if (!deletedDataFiles.isEmpty()) { validateNoNewDeletesForDataFiles( base, startingSnapshotId, conflictDetectionFilter, deletedDataFiles, parent); } } }
private void commitOperation(SnapshotUpdate<?> operation, String description) { LOG.info("Committing {} to table {}", description, table); if (applicationId != null) { operation.set("spark.app.id", applicationId); } if (!extraSnapshotMetadata.isEmpty()) { extraSnapshotMetadata.forEach(operation::set); } if (!CommitMetadata.commitProperties().isEmpty()) { CommitMetadata.commitProperties().forEach(operation::set); } if (wapEnabled && wapId != null) { // write-audit-publish is enabled for this table and job // stage the changes without changing the current snapshot operation.set(SnapshotSummary.STAGED_WAP_ID_PROP, wapId); operation.stageOnly(); } if (branch != null) { operation.toBranch(branch); } try { long start = System.currentTimeMillis(); operation.commit(); // abort is automatically called if this fails long duration = System.currentTimeMillis() - start; LOG.info("Committed in {} ms", duration); } catch (Exception e) { cleanupOnAbort = e instanceof CleanableFailure; throw e; } }
@Override @SuppressWarnings("checkstyle:CyclomaticComplexity") public void commit() { // this is always set to the latest commit attempt's snapshot AtomicReference<Snapshot> stagedSnapshot = new AtomicReference<>(); try (Timed ignore = commitMetrics().totalDuration().start()) { try { Tasks.foreach(ops) .retry(base.propertyAsInt(COMMIT_NUM_RETRIES, COMMIT_NUM_RETRIES_DEFAULT)) .exponentialBackoff( base.propertyAsInt(COMMIT_MIN_RETRY_WAIT_MS, COMMIT_MIN_RETRY_WAIT_MS_DEFAULT), base.propertyAsInt(COMMIT_MAX_RETRY_WAIT_MS, COMMIT_MAX_RETRY_WAIT_MS_DEFAULT), base.propertyAsInt(COMMIT_TOTAL_RETRY_TIME_MS, COMMIT_TOTAL_RETRY_TIME_MS_DEFAULT), 2.0 /* exponential */) .onlyRetryOn(CommitFailedException.class) .countAttempts(commitMetrics().attempts()) .run( taskOps -> { Snapshot newSnapshot = apply(); stagedSnapshot.set(newSnapshot); TableMetadata.Builder update = TableMetadata.buildFrom(base); if (base.snapshot(newSnapshot.snapshotId()) != null) { // this is a rollback operation update.setBranchSnapshot(newSnapshot.snapshotId(), targetBranch); } else if (stageOnly) { update.addSnapshot(newSnapshot); } else { update.setBranchSnapshot(newSnapshot, targetBranch); } TableMetadata updated = update.build(); if (updated.changes().isEmpty()) { // do not commit if the metadata has not changed. for example, this may happen // when setting the current // snapshot to an ID that is already current. note that this check uses // identity. return; } // if the table UUID is missing, add it here. the UUID will be re-created each // time // this operation retries // to ensure that if a concurrent operation assigns the UUID, this operation will // not fail. taskOps.commit(base, updated.withUUID()); }); } catch (CommitStateUnknownException commitStateUnknownException) { throw commitStateUnknownException; } catch (RuntimeException e) { if (!strictCleanup || e instanceof CleanableFailure) { Exceptions.suppressAndThrow(e, this::cleanAll); } throw e; } // at this point, the commit must have succeeded so the stagedSnapshot is committed Snapshot committedSnapshot = stagedSnapshot.get(); try { LOG.info( "Committed snapshot {} ({})", committedSnapshot.snapshotId(), getClass().getSimpleName()); if (cleanupAfterCommit()) { cleanUncommitted(Sets.newHashSet(committedSnapshot.allManifests(ops.io()))); } // also clean up unused manifest lists created by multiple attempts for (String manifestList : manifestLists) { if (!committedSnapshot.manifestListLocation().equals(manifestList)) { deleteFile(manifestList); } } } catch (Throwable e) { LOG.warn( "Failed to load committed table metadata or during cleanup, skipping further cleanup", e); } } try { notifyListeners(); } catch (Throwable e) { LOG.warn("Failed to notify event listeners", e); } }